 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralisation in fully-connected neural networks for time series forecasting
Paper and Code
Feb 14, 2019

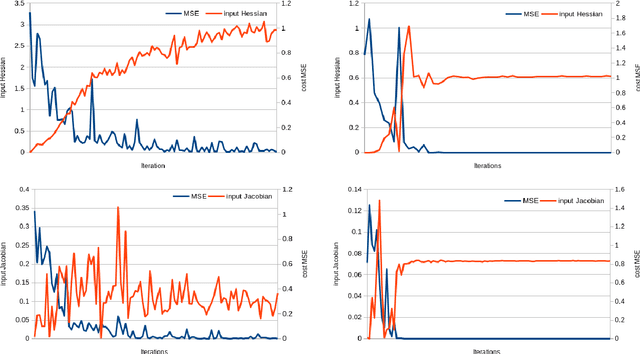

In this paper we study the generalisation capabilities of fully-connected neural networks trained in the context of time series forecasting. Time series do not satisfy the typical assumption in statistical learning theory of the data being i.i.d. samples from some data-generating distribution. We use the input and weight Hessians, that is the smoothness of the learned function with respect to the input and the width of the minimum in weight space, to quantify a network's ability to generalise to unseen data. While such generalisation metrics have been studied extensively in the i.i.d. setting of for example image recognition, here we empirically validate their use in the task of time series forecasting. Furthermore we discuss how one can control the generalisation capability of the network by means of the training process using the learning rate, batch size and the number of training iterations as controls. Using these hyperparameters one can efficiently control the complexity of the output function without imposing explicit constraints.