 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in LLM Problem Solving: The Case of the Shortest Path
Apr 16, 2026Whether language models can systematically generalize remains actively debated. Yet empirical performance is jointly shaped by multiple factors such as training data, training paradigms, and inference-time strategies, making failures difficult to interpret. We introduce a controlled synthetic environment based on shortest-path planning, a canonical composable sequential optimization problem. The setup enables clean separation of these factors and supports two orthogonal axes of generalization: spatial transfer to unseen maps and length scaling to longer-horizon problems. We find that models exhibit strong spatial transfer but consistently fail under length scaling due to recursive instability. We further analyze how distinct stages of the learning pipeline influence systematic problem-solving: for example, data coverage sets capability limits; reinforcement learning improves training stability but does not expand those limits; and inference-time scaling enhances performance but cannot rescue length-scaling failures.
Training-Free Generative Modeling via Kernelized Stochastic Interpolants
Feb 25, 2026We develop a kernel method for generative modeling within the stochastic interpolant framework, replacing neural network training with linear systems. The drift of the generative SDE is $\hat b_t(x) = \nablaφ(x)^\topη_t$, where $η_t\in\R^P$ solves a $P\times P$ system computable from data, with $P$ independent of the data dimension $d$. Since estimates are inexact, the diffusion coefficient $D_t$ affects sample quality; the optimal $D_t^*$ from Girsanov diverges at $t=0$, but this poses no difficulty and we develop an integrator that handles it seamlessly. The framework accommodates diverse feature maps -- scattering transforms, pretrained generative models etc. -- enabling training-free generation and model combination. We demonstrate the approach on financial time series, turbulence, and image generation.
Concept Reachability in Diffusion Models: Beyond Dataset Constraints
May 25, 2025Despite significant advances in quality and complexity of the generations in text-to-image models, prompting does not always lead to the desired outputs. Controlling model behaviour by directly steering intermediate model activations has emerged as a viable alternative allowing to reach concepts in latent space that may otherwise remain inaccessible by prompt. In this work, we introduce a set of experiments to deepen our understanding of concept reachability. We design a training data setup with three key obstacles: scarcity of concepts, underspecification of concepts in the captions, and data biases with tied concepts. Our results show: (i) concept reachability in latent space exhibits a distinct phase transition, with only a small number of samples being sufficient to enable reachability, (ii) where in the latent space the intervention is performed critically impacts reachability, showing that certain concepts are reachable only at certain stages of transformation, and (iii) while prompting ability rapidly diminishes with a decrease in quality of the dataset, concepts often remain reliably reachable through steering. Model providers can leverage this to bypass costly retraining and dataset curation and instead innovate with user-facing control mechanisms.
Deep Unlearn: Benchmarking Machine Unlearning
Oct 02, 2024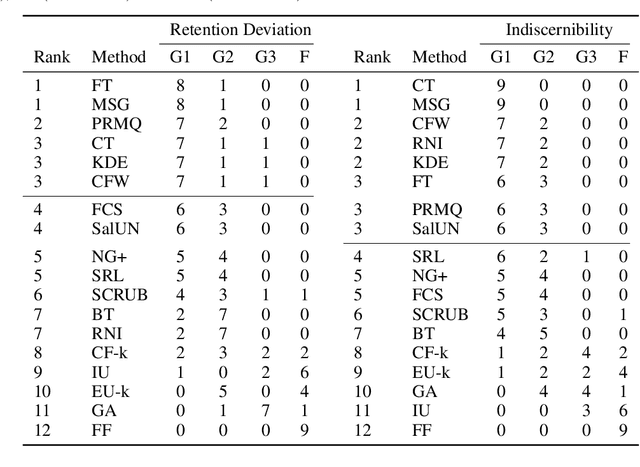
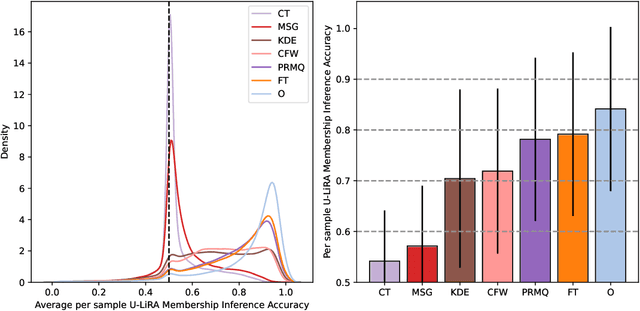
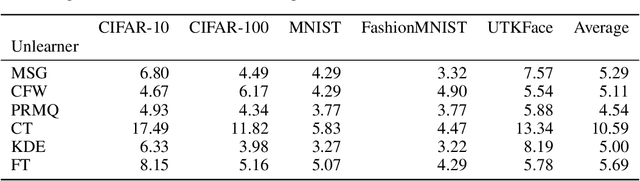
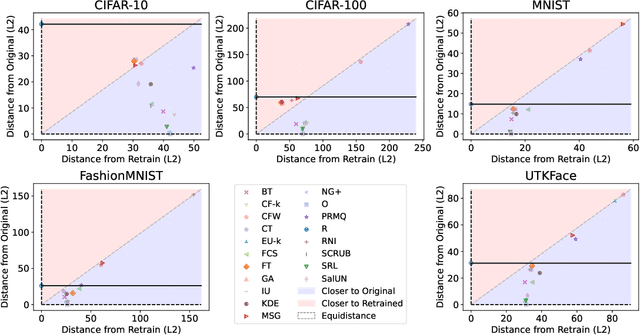
Machine unlearning (MU) aims to remove the influence of particular data points from the learnable parameters of a trained machine learning model. This is a crucial capability in light of data privacy requirements, trustworthiness, and safety in deployed models. MU is particularly challenging for deep neural networks (DNNs), such as convolutional nets or vision transformers, as such DNNs tend to memorize a notable portion of their training dataset. Nevertheless, the community lacks a rigorous and multifaceted study that looks into the success of MU methods for DNNs. In this paper, we investigate 18 state-of-the-art MU methods across various benchmark datasets and models, with each evaluation conducted over 10 different initializations, a comprehensive evaluation involving MU over 100K models. We show that, with the proper hyperparameters, Masked Small Gradients (MSG) and Convolution Transpose (CT), consistently perform better in terms of model accuracy and run-time efficiency across different models, datasets, and initializations, assessed by population-based membership inference attacks (MIA) and per-sample unlearning likelihood ratio attacks (U-LiRA). Furthermore, our benchmark highlights the fact that comparing a MU method only with commonly used baselines, such as Gradient Ascent (GA) or Successive Random Relabeling (SRL), is inadequate, and we need better baselines like Negative Gradient Plus (NG+) with proper hyperparameter selection.
P4: Towards private, personalized, and Peer-to-Peer learning
May 27, 2024Personalized learning is a proposed approach to address the problem of data heterogeneity in collaborative machine learning. In a decentralized setting, the two main challenges of personalization are client clustering and data privacy. In this paper, we address these challenges by developing P4 (Personalized Private Peer-to-Peer) a method that ensures that each client receives a personalized model while maintaining differential privacy guarantee of each client's local dataset during and after the training. Our approach includes the design of a lightweight algorithm to identify similar clients and group them in a private, peer-to-peer (P2P) manner. Once grouped, we develop differentially-private knowledge distillation for clients to co-train with minimal impact on accuracy. We evaluate our proposed method on three benchmark datasets (FEMNIST or Federated EMNIST, CIFAR-10 and CIFAR-100) and two different neural network architectures (Linear and CNN-based networks) across a range of privacy parameters. The results demonstrate the potential of P4, as it outperforms the state-of-the-art of differential private P2P by up to 40 percent in terms of accuracy. We also show the practicality of P4 by implementing it on resource constrained devices, and validating that it has minimal overhead, e.g., about 7 seconds to run collaborative training between two clients.
On original and latent space connectivity in deep neural networks
Nov 12, 2023We study whether inputs from the same class can be connected by a continuous path, in original or latent representation space, such that all points on the path are mapped by the neural network model to the same class. Understanding how the neural network views its own input space and how the latent spaces are structured has value for explainability and robustness. We show that paths, linear or nonlinear, connecting same-class inputs exist in all cases studied.
Leave-one-out Distinguishability in Machine Learning
Sep 29, 2023



We introduce a new analytical framework to quantify the changes in a machine learning algorithm's output distribution following the inclusion of a few data points in its training set, a notion we define as leave-one-out distinguishability (LOOD). This problem is key to measuring data **memorization** and **information leakage** in machine learning, and the **influence** of training data points on model predictions. We illustrate how our method broadens and refines existing empirical measures of memorization and privacy risks associated with training data. We use Gaussian processes to model the randomness of machine learning algorithms, and validate LOOD with extensive empirical analysis of information leakage using membership inference attacks. Our theoretical framework enables us to investigate the causes of information leakage and where the leakage is high. For example, we analyze the influence of activation functions, on data memorization. Additionally, our method allows us to optimize queries that disclose the most significant information about the training data in the leave-one-out setting. We illustrate how optimal queries can be used for accurate **reconstruction** of training data.
Privacy Risk for anisotropic Langevin dynamics using relative entropy bounds
Feb 01, 2023The privacy preserving properties of Langevin dynamics with additive isotropic noise have been extensively studied. However, the isotropic noise assumption is very restrictive: (a) when adding noise to existing learning algorithms to preserve privacy and maintain the best possible accuracy one should take into account the relative magnitude of the outputs and their correlations; (b) popular algorithms such as stochastic gradient descent (and their continuous time limits) appear to possess anisotropic covariance properties. To study the privacy risks for the anisotropic noise case, one requires general results on the relative entropy between the laws of two Stochastic Differential Equations with different drifts and diffusion coefficients. Our main contribution is to establish such a bound using stability estimates for solutions to the Fokker-Planck equations via functional inequalities. With additional assumptions, the relative entropy bound implies an $(\epsilon,\delta)$-differential privacy bound. We discuss the practical implications of our bound related to privacy risk in different contexts.Finally, the benefits of anisotropic noise are illustrated using numerical results on optimising a quadratic loss or calibrating a neural network.
Data-driven initialization of deep learning solvers for Hamilton-Jacobi-Bellman PDEs
Jul 19, 2022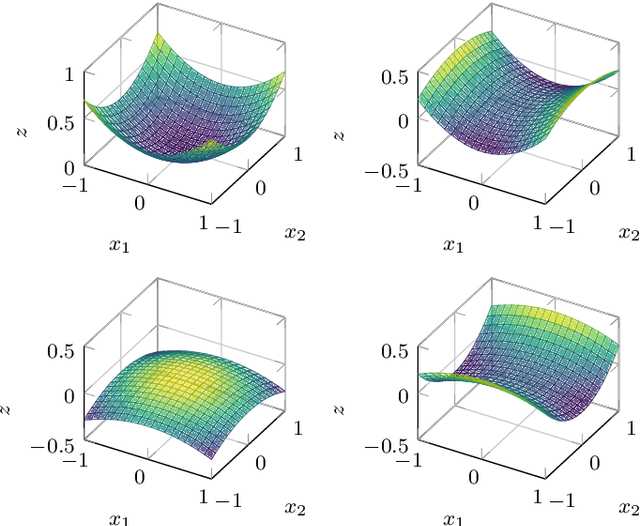

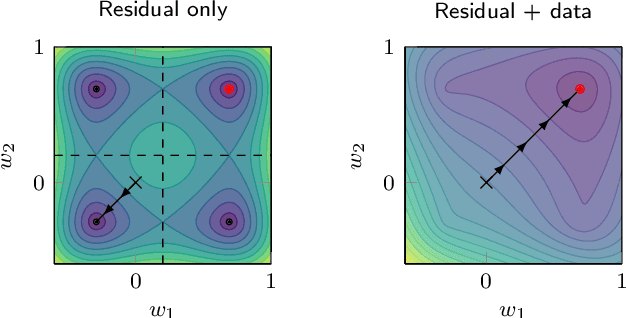
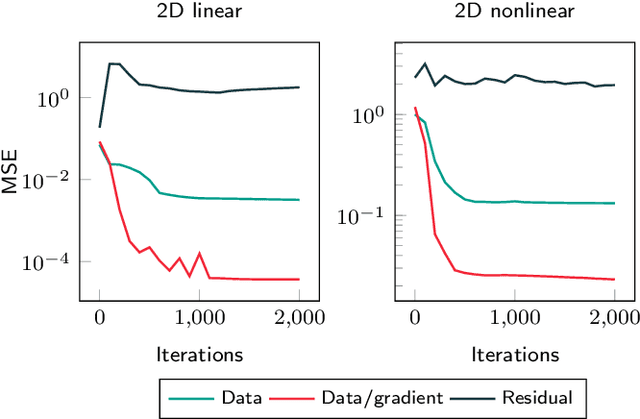
A deep learning approach for the approximation of the Hamilton-Jacobi-Bellman partial differential equation (HJB PDE) associated to the Nonlinear Quadratic Regulator (NLQR) problem. A state-dependent Riccati equation control law is first used to generate a gradient-augmented synthetic dataset for supervised learning. The resulting model becomes a warm start for the minimization of a loss function based on the residual of the HJB PDE. The combination of supervised learning and residual minimization avoids spurious solutions and mitigate the data inefficiency of a supervised learning-only approach. Numerical tests validate the different advantages of the proposed methodology.
Quantifying Information Leakage from Gradients
May 28, 2021
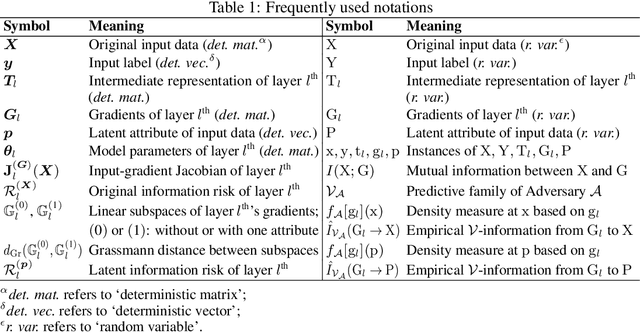
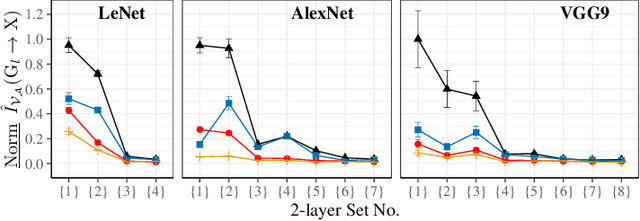

Sharing deep neural networks' gradients instead of training data could facilitate data privacy in collaborative learning. In practice however, gradients can disclose both private latent attributes and original data. Mathematical metrics are needed to quantify both original and latent information leakages from gradients computed over the training data. In this work, we first use an adaptation of the empirical $\mathcal{V}$-information to present an information-theoretic justification for the attack success rates in a layer-wise manner. We then move towards a deeper understanding of gradient leakages and propose more general and efficient metrics, using sensitivity and subspace distance to quantify the gradient changes w.r.t. original and latent information, respectively. Our empirical results, on six datasets and four models, reveal that gradients of the first layers contain the highest amount of original information, while the classifier/fully-connected layers placed after the feature extractor contain the highest latent information. Further, we show how training hyperparameters such as gradient aggregation can decrease information leakages. Our characterization provides a new understanding on gradient-based information leakages using the gradients' sensitivity w.r.t. changes in private information, and portends possible defenses such as layer-based protection or strong aggregation.