 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP4: Towards private, personalized, and Peer-to-Peer learning
May 27, 2024Personalized learning is a proposed approach to address the problem of data heterogeneity in collaborative machine learning. In a decentralized setting, the two main challenges of personalization are client clustering and data privacy. In this paper, we address these challenges by developing P4 (Personalized Private Peer-to-Peer) a method that ensures that each client receives a personalized model while maintaining differential privacy guarantee of each client's local dataset during and after the training. Our approach includes the design of a lightweight algorithm to identify similar clients and group them in a private, peer-to-peer (P2P) manner. Once grouped, we develop differentially-private knowledge distillation for clients to co-train with minimal impact on accuracy. We evaluate our proposed method on three benchmark datasets (FEMNIST or Federated EMNIST, CIFAR-10 and CIFAR-100) and two different neural network architectures (Linear and CNN-based networks) across a range of privacy parameters. The results demonstrate the potential of P4, as it outperforms the state-of-the-art of differential private P2P by up to 40 percent in terms of accuracy. We also show the practicality of P4 by implementing it on resource constrained devices, and validating that it has minimal overhead, e.g., about 7 seconds to run collaborative training between two clients.
SINBAD: Saliency-informed detection of breakage caused by ad blocking
May 08, 2024
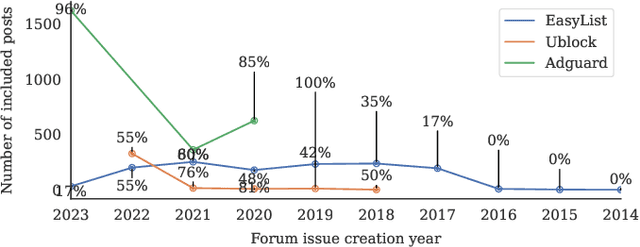
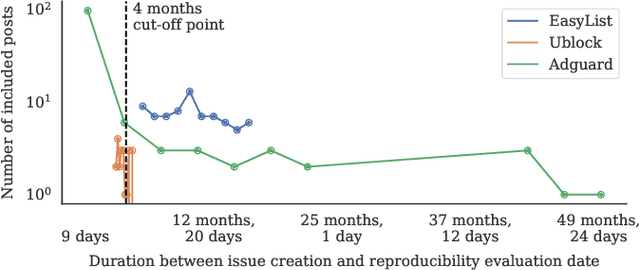
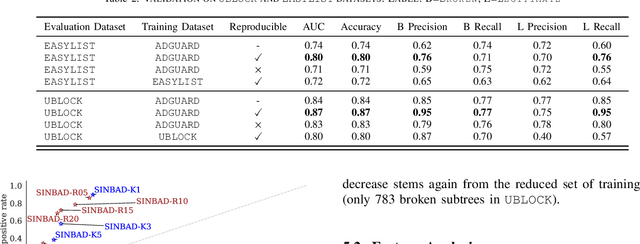
Privacy-enhancing blocking tools based on filter-list rules tend to break legitimate functionality. Filter-list maintainers could benefit from automated breakage detection tools that allow them to proactively fix problematic rules before deploying them to millions of users. We introduce SINBAD, an automated breakage detector that improves the accuracy over the state of the art by 20%, and is the first to detect dynamic breakage and breakage caused by style-oriented filter rules. The success of SINBAD is rooted in three innovations: (1) the use of user-reported breakage issues in forums that enable the creation of a high-quality dataset for training in which only breakage that users perceive as an issue is included; (2) the use of 'web saliency' to automatically identify user-relevant regions of a website on which to prioritize automated interactions aimed at triggering breakage; and (3) the analysis of webpages via subtrees which enables fine-grained identification of problematic filter rules.
PURL: Safe and Effective Sanitization of Link Decoration
Aug 07, 2023

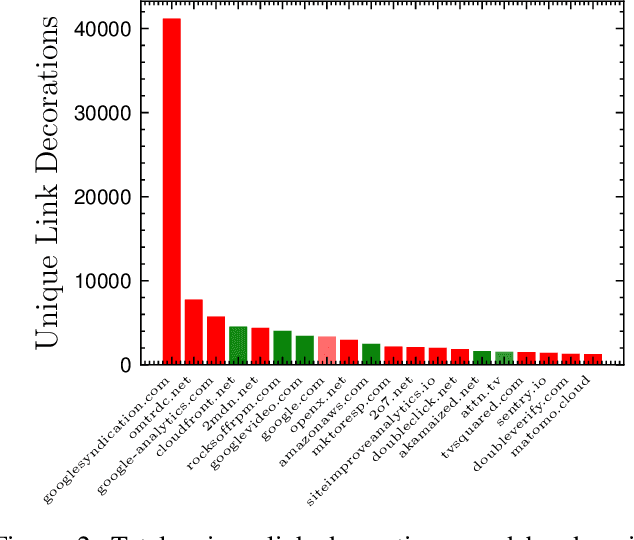
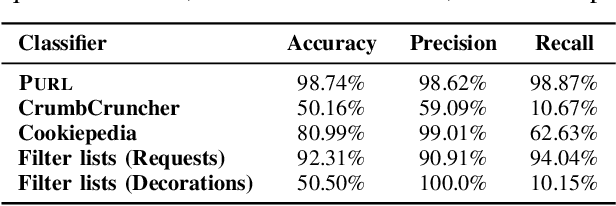
While privacy-focused browsers have taken steps to block third-party cookies and browser fingerprinting, novel tracking methods that bypass existing defenses continue to emerge. Since trackers need to exfiltrate information from the client- to server-side through link decoration regardless of the tracking technique they employ, a promising orthogonal approach is to detect and sanitize tracking information in decorated links. We present PURL, a machine-learning approach that leverages a cross-layer graph representation of webpage execution to safely and effectively sanitize link decoration. Our evaluation shows that PURL significantly outperforms existing countermeasures in terms of accuracy and reducing website breakage while being robust to common evasion techniques. We use PURL to perform a measurement study on top-million websites. We find that link decorations are widely abused by well-known advertisers and trackers to exfiltrate user information collected from browser storage, email addresses, and scripts involved in fingerprinting.