 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurkish Delights: a Dataset on Turkish Euphemisms
Jul 17, 2024Euphemisms are a form of figurative language relatively understudied in natural language processing. This research extends the current computational work on potentially euphemistic terms (PETs) to Turkish. We introduce the Turkish PET dataset, the first available of its kind in the field. By creating a list of euphemisms in Turkish, collecting example contexts, and annotating them, we provide both euphemistic and non-euphemistic examples of PETs in Turkish. We describe the dataset and methodologies, and also experiment with transformer-based models on Turkish euphemism detection by using our dataset for binary classification. We compare performances across models using F1, accuracy, and precision as evaluation metrics.
MEDs for PETs: Multilingual Euphemism Disambiguation for Potentially Euphemistic Terms
Jan 25, 2024
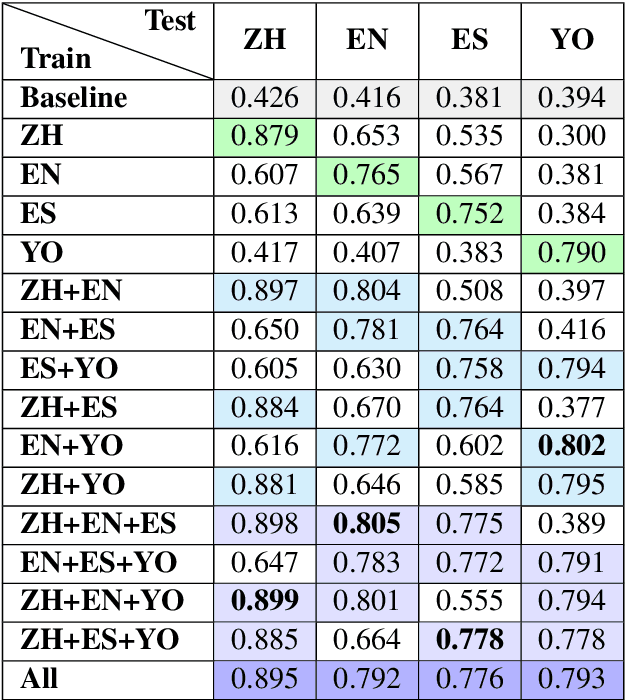
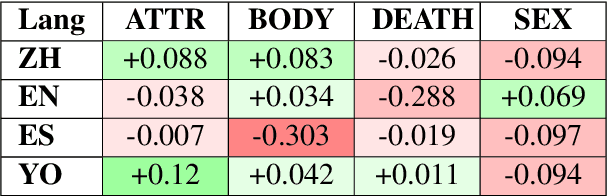
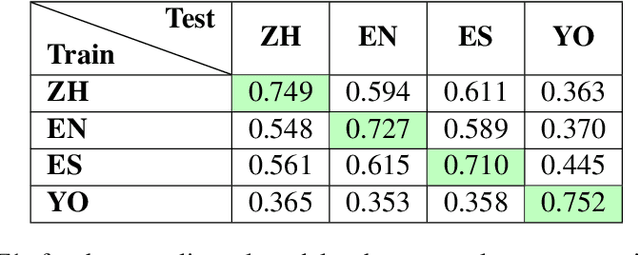
This study investigates the computational processing of euphemisms, a universal linguistic phenomenon, across multiple languages. We train a multilingual transformer model (XLM-RoBERTa) to disambiguate potentially euphemistic terms (PETs) in multilingual and cross-lingual settings. In line with current trends, we demonstrate that zero-shot learning across languages takes place. We also show cases where multilingual models perform better on the task compared to monolingual models by a statistically significant margin, indicating that multilingual data presents additional opportunities for models to learn about cross-lingual, computational properties of euphemisms. In a follow-up analysis, we focus on universal euphemistic "categories" such as death and bodily functions among others. We test to see whether cross-lingual data of the same domain is more important than within-language data of other domains to further understand the nature of the cross-lingual transfer.
PURL: Safe and Effective Sanitization of Link Decoration
Aug 07, 2023

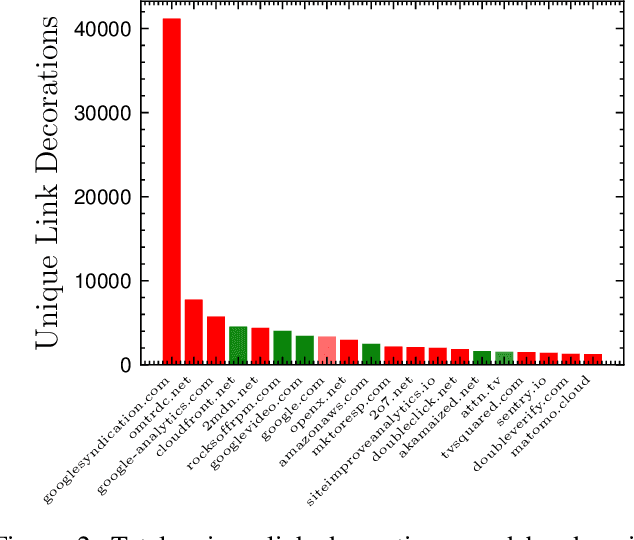
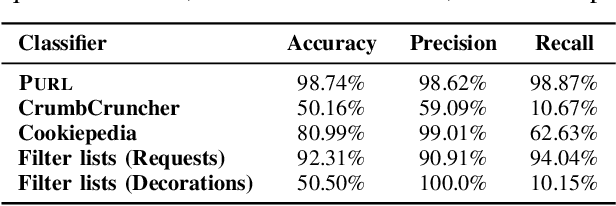
While privacy-focused browsers have taken steps to block third-party cookies and browser fingerprinting, novel tracking methods that bypass existing defenses continue to emerge. Since trackers need to exfiltrate information from the client- to server-side through link decoration regardless of the tracking technique they employ, a promising orthogonal approach is to detect and sanitize tracking information in decorated links. We present PURL, a machine-learning approach that leverages a cross-layer graph representation of webpage execution to safely and effectively sanitize link decoration. Our evaluation shows that PURL significantly outperforms existing countermeasures in terms of accuracy and reducing website breakage while being robust to common evasion techniques. We use PURL to perform a measurement study on top-million websites. We find that link decorations are widely abused by well-known advertisers and trackers to exfiltrate user information collected from browser storage, email addresses, and scripts involved in fingerprinting.
FEED PETs: Further Experimentation and Expansion on the Disambiguation of Potentially Euphemistic Terms
Jun 06, 2023

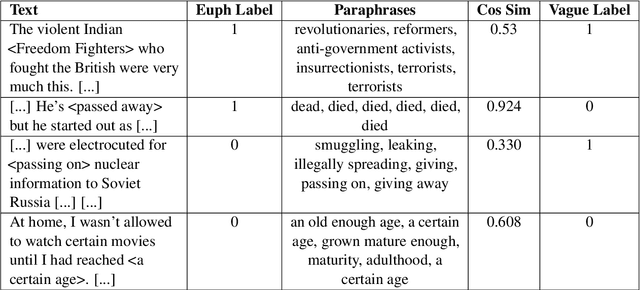

Transformers have been shown to work well for the task of English euphemism disambiguation, in which a potentially euphemistic term (PET) is classified as euphemistic or non-euphemistic in a particular context. In this study, we expand on the task in two ways. First, we annotate PETs for vagueness, a linguistic property associated with euphemisms, and find that transformers are generally better at classifying vague PETs, suggesting linguistic differences in the data that impact performance. Second, we present novel euphemism corpora in three different languages: Yoruba, Spanish, and Mandarin Chinese. We perform euphemism disambiguation experiments in each language using multilingual transformer models mBERT and XLM-RoBERTa, establishing preliminary results from which to launch future work.
A Report on the Euphemisms Detection Shared Task
Dec 03, 2022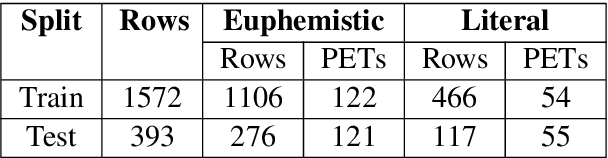

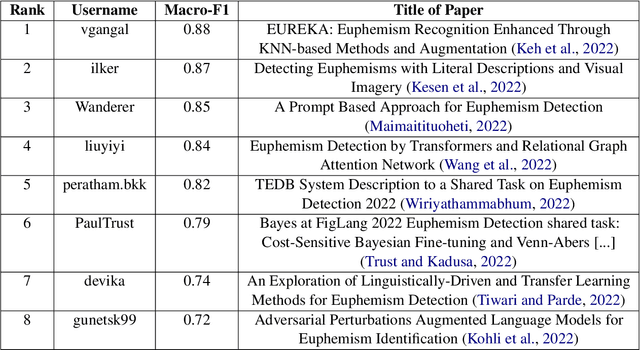
This paper presents The Shared Task on Euphemism Detection for the Third Workshop on Figurative Language Processing (FigLang 2022) held in conjunction with EMNLP 2022. Participants were invited to investigate the euphemism detection task: given input text, identify whether it contains a euphemism. The input data is a corpus of sentences containing potentially euphemistic terms (PETs) collected from the GloWbE corpus (Davies and Fuchs, 2015), and are human-annotated as containing either a euphemistic or literal usage of a PET. In this paper, we present the results and analyze the common themes, methods and findings of the participating teams
Searching for PETs: Using Distributional and Sentiment-Based Methods to Find Potentially Euphemistic Terms
May 20, 2022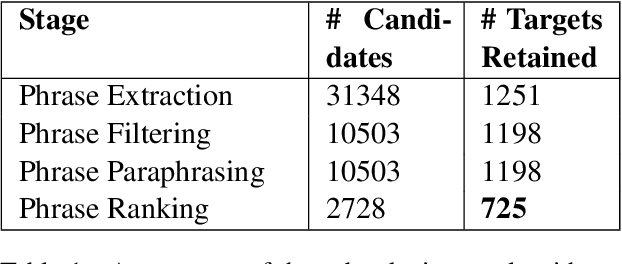

This paper presents a linguistically driven proof of concept for finding potentially euphemistic terms, or PETs. Acknowledging that PETs tend to be commonly used expressions for a certain range of sensitive topics, we make use of distributional similarities to select and filter phrase candidates from a sentence and rank them using a set of simple sentiment-based metrics. We present the results of our approach tested on a corpus of sentences containing euphemisms, demonstrating its efficacy for detecting single and multi-word PETs from a broad range of topics. We also discuss future potential for sentiment-based methods on this task.
CATs are Fuzzy PETs: A Corpus and Analysis of Potentially Euphemistic Terms
May 05, 2022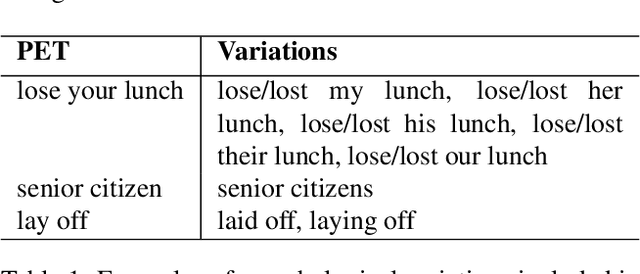
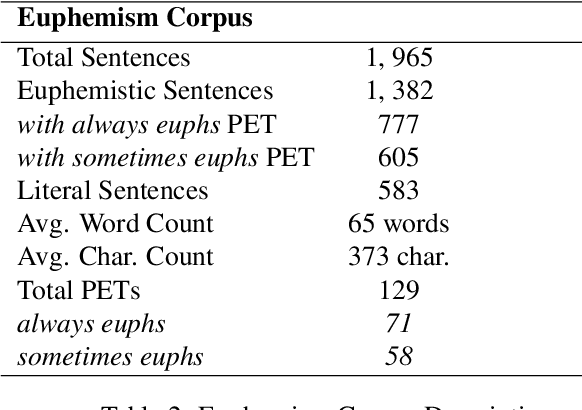


Euphemisms have not received much attention in natural language processing, despite being an important element of polite and figurative language. Euphemisms prove to be a difficult topic, not only because they are subject to language change, but also because humans may not agree on what is a euphemism and what is not. Nevertheless, the first step to tackling the issue is to collect and analyze examples of euphemisms. We present a corpus of potentially euphemistic terms (PETs) along with example texts from the GloWbE corpus. Additionally, we present a subcorpus of texts where these PETs are not being used euphemistically, which may be useful for future applications. We also discuss the results of multiple analyses run on the corpus. Firstly, we find that sentiment analysis on the euphemistic texts supports that PETs generally decrease negative and offensive sentiment. Secondly, we observe cases of disagreement in an annotation task, where humans are asked to label PETs as euphemistic or not in a subset of our corpus text examples. We attribute the disagreement to a variety of potential reasons, including if the PET was a commonly accepted term (CAT).