 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Embeddings for One-Shot Classification of Doctor-AI Consultations
Feb 06, 2024Effective communication between healthcare providers and patients is crucial to providing high-quality patient care. In this work, we investigate how Doctor-written and AI-generated texts in healthcare consultations can be classified using state-of-the-art embeddings and one-shot classification systems. By analyzing embeddings such as bag-of-words, character n-grams, Word2Vec, GloVe, fastText, and GPT2 embeddings, we examine how well our one-shot classification systems capture semantic information within medical consultations. Results show that the embeddings are capable of capturing semantic features from text in a reliable and adaptable manner. Overall, Word2Vec, GloVe and Character n-grams embeddings performed well, indicating their suitability for modeling targeted to this task. GPT2 embedding also shows notable performance, indicating its suitability for models tailored to this task as well. Our machine learning architectures significantly improved the quality of health conversations when training data are scarce, improving communication between patients and healthcare providers.
MEDs for PETs: Multilingual Euphemism Disambiguation for Potentially Euphemistic Terms
Jan 25, 2024
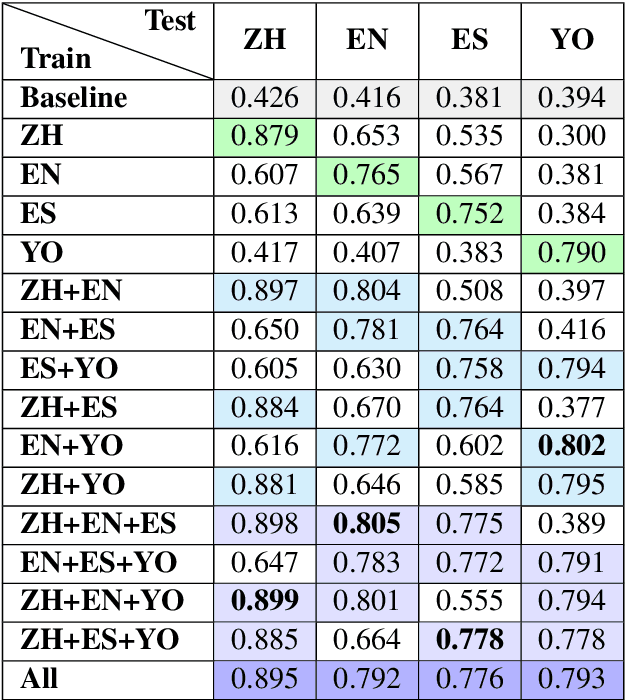
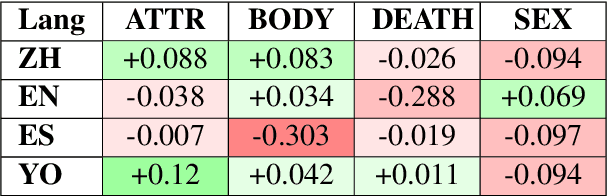
This study investigates the computational processing of euphemisms, a universal linguistic phenomenon, across multiple languages. We train a multilingual transformer model (XLM-RoBERTa) to disambiguate potentially euphemistic terms (PETs) in multilingual and cross-lingual settings. In line with current trends, we demonstrate that zero-shot learning across languages takes place. We also show cases where multilingual models perform better on the task compared to monolingual models by a statistically significant margin, indicating that multilingual data presents additional opportunities for models to learn about cross-lingual, computational properties of euphemisms. In a follow-up analysis, we focus on universal euphemistic "categories" such as death and bodily functions among others. We test to see whether cross-lingual data of the same domain is more important than within-language data of other domains to further understand the nature of the cross-lingual transfer.
FEED PETs: Further Experimentation and Expansion on the Disambiguation of Potentially Euphemistic Terms
Jun 06, 2023

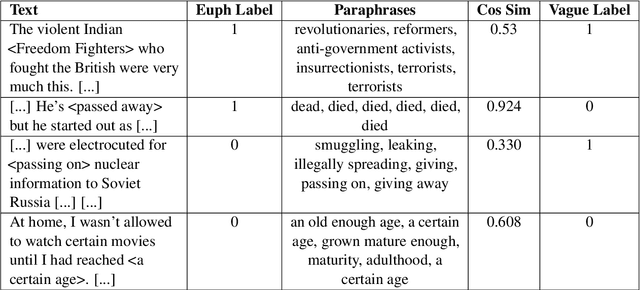

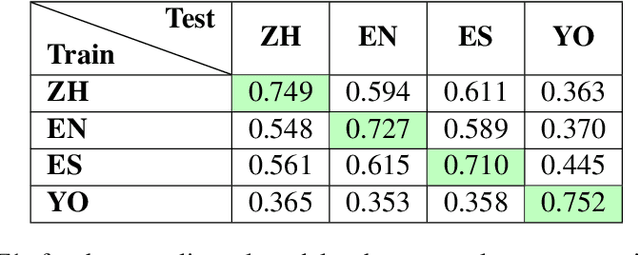
Transformers have been shown to work well for the task of English euphemism disambiguation, in which a potentially euphemistic term (PET) is classified as euphemistic or non-euphemistic in a particular context. In this study, we expand on the task in two ways. First, we annotate PETs for vagueness, a linguistic property associated with euphemisms, and find that transformers are generally better at classifying vague PETs, suggesting linguistic differences in the data that impact performance. Second, we present novel euphemism corpora in three different languages: Yoruba, Spanish, and Mandarin Chinese. We perform euphemism disambiguation experiments in each language using multilingual transformer models mBERT and XLM-RoBERTa, establishing preliminary results from which to launch future work.
Transformer-based approaches to Sentiment Detection
Mar 13, 2023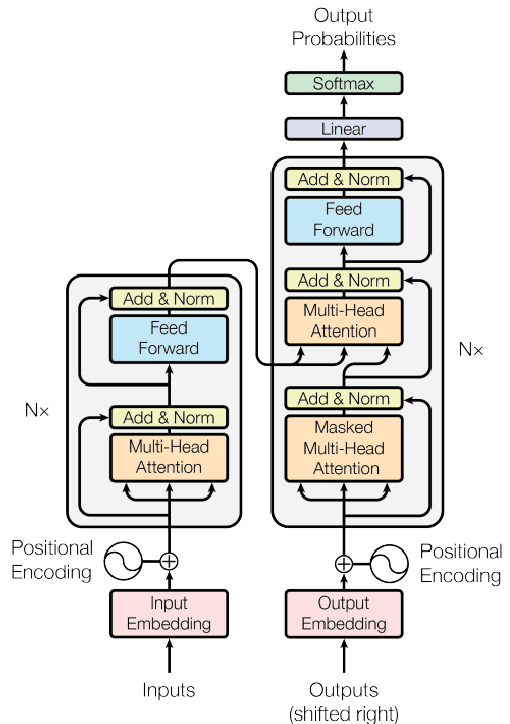



The use of transfer learning methods is largely responsible for the present breakthrough in Natural Learning Processing (NLP) tasks across multiple domains. In order to solve the problem of sentiment detection, we examined the performance of four different types of well-known state-of-the-art transformer models for text classification. Models such as Bidirectional Encoder Representations from Transformers (BERT), Robustly Optimized BERT Pre-training Approach (RoBERTa), a distilled version of BERT (DistilBERT), and a large bidirectional neural network architecture (XLNet) were proposed. The performance of the four models that were used to detect disaster in the text was compared. All the models performed well enough, indicating that transformer-based models are suitable for the detection of disaster in text. The RoBERTa transformer model performs best on the test dataset with a score of 82.6% and is highly recommended for quality predictions. Furthermore, we discovered that the learning algorithms' performance was influenced by the pre-processing techniques, the nature of words in the vocabulary, unbalanced labeling, and the model parameters.