 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based approaches to Sentiment Detection
Mar 13, 2023



The use of transfer learning methods is largely responsible for the present breakthrough in Natural Learning Processing (NLP) tasks across multiple domains. In order to solve the problem of sentiment detection, we examined the performance of four different types of well-known state-of-the-art transformer models for text classification. Models such as Bidirectional Encoder Representations from Transformers (BERT), Robustly Optimized BERT Pre-training Approach (RoBERTa), a distilled version of BERT (DistilBERT), and a large bidirectional neural network architecture (XLNet) were proposed. The performance of the four models that were used to detect disaster in the text was compared. All the models performed well enough, indicating that transformer-based models are suitable for the detection of disaster in text. The RoBERTa transformer model performs best on the test dataset with a score of 82.6% and is highly recommended for quality predictions. Furthermore, we discovered that the learning algorithms' performance was influenced by the pre-processing techniques, the nature of words in the vocabulary, unbalanced labeling, and the model parameters.
Mapping Process for the Task: Wikidata Statements to Text as Wikipedia Sentences
Oct 23, 2022



Acknowledged as one of the most successful online cooperative projects in human society, Wikipedia has obtained rapid growth in recent years and desires continuously to expand content and disseminate knowledge values for everyone globally. The shortage of volunteers brings to Wikipedia many issues, including developing content for over 300 languages at the present. Therefore, the benefit that machines can automatically generate content to reduce human efforts on Wikipedia language projects could be considerable. In this paper, we propose our mapping process for the task of converting Wikidata statements to natural language text (WS2T) for Wikipedia projects at the sentence level. The main step is to organize statements, represented as a group of quadruples and triples, and then to map them to corresponding sentences in English Wikipedia. We evaluate the output corpus in various aspects: sentence structure analysis, noise filtering, and relationships between sentence components based on word embedding models. The results are helpful not only for the data-to-text generation task but also for other relevant works in the field.
WikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Sep 27, 2022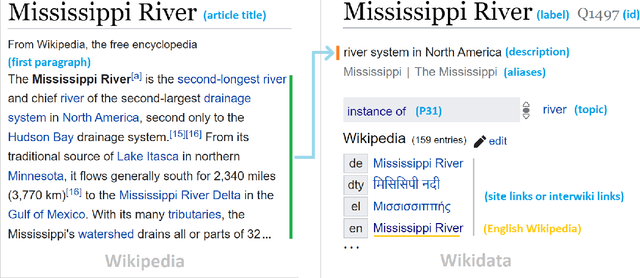
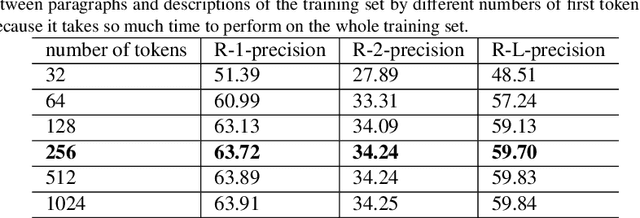
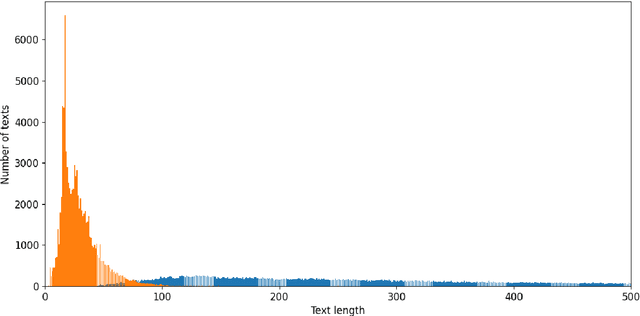
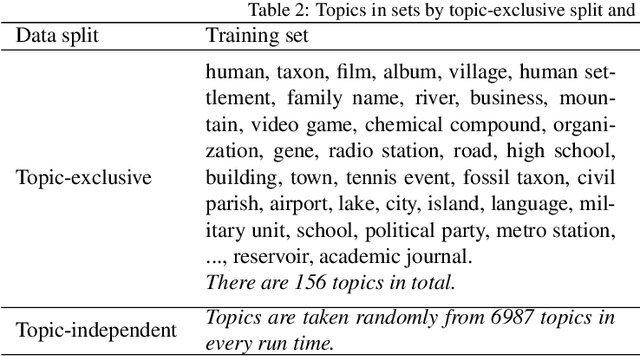
As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.