 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Paper and Code
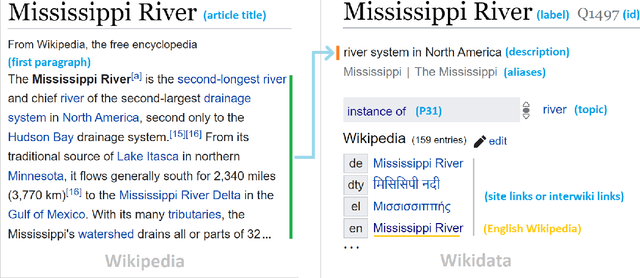
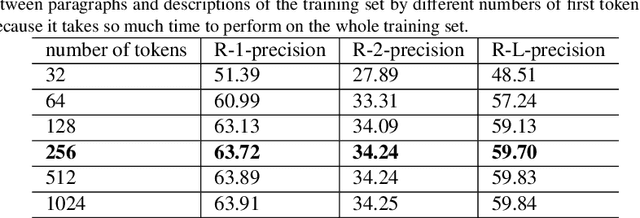
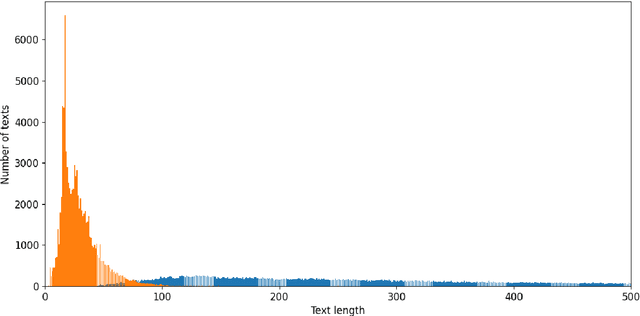
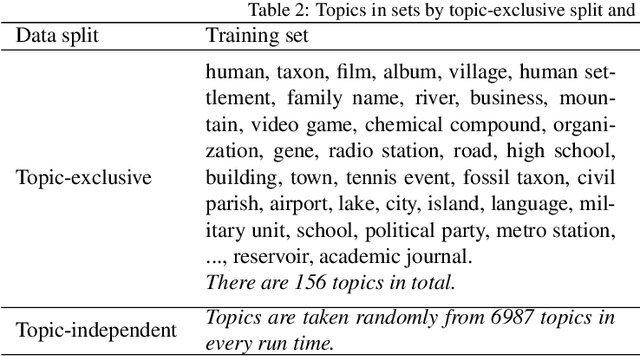
As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.