 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Trust to Transactions: Tracking Affiliate Marketing and FTC Compliance in YouTube's Influencer Economy
Mar 04, 2026YouTube has evolved into a powerful platform that where creators monetize their influence through affiliate marketing, raising concerns about transparency and ethics, especially when creators fail to disclose their affiliate relationships. Although regulatory agencies like the US Federal Trade Commission (FTC) have issued guidelines to address these issues, non-compliance and consumer harm persist, and the extent of these problems remains unclear. In this paper, we introduce tools, developed with insights from recent advances in Web measurement and NLP research, to examine the state of the affiliate marketing ecosystem on YouTube. We apply these tools to a 10-year dataset of 2 million videos from nearly 540,000 creators, analyzing the prevalence of affiliate marketing on YouTube and the rates of non-compliant behavior. Our findings reveal that affiliate links are widespread, yet dis- closure compliance remains low, with most videos failing to meet FTC standards. Furthermore, we analyze the effects of different stakeholders in improving disclosure behavior. Our study suggests that the platform is highly associated with improved compliance through standardized disclosure features. We recommend that regulators and affiliate partners collaborate with platforms to enhance transparency, accountability, and trust in the influencer economy.
AutoLike: Auditing Social Media Recommendations through User Interactions
Feb 13, 2025Modern social media platforms, such as TikTok, Facebook, and YouTube, rely on recommendation systems to personalize content for users based on user interactions with endless streams of content, such as "For You" pages. However, these complex algorithms can inadvertently deliver problematic content related to self-harm, mental health, and eating disorders. We introduce AutoLike, a framework to audit recommendation systems in social media platforms for topics of interest and their sentiments. To automate the process, we formulate the problem as a reinforcement learning problem. AutoLike drives the recommendation system to serve a particular type of content through interactions (e.g., liking). We apply the AutoLike framework to the TikTok platform as a case study. We evaluate how well AutoLike identifies TikTok content automatically across nine topics of interest; and conduct eight experiments to demonstrate how well it drives TikTok's recommendation system towards particular topics and sentiments. AutoLike has the potential to assist regulators in auditing recommendation systems for problematic content. (Warning: This paper contains qualitative examples that may be viewed as offensive or harmful.)
Harnessing TI Feeds for Exploitation Detection
Sep 12, 2024



Many organizations rely on Threat Intelligence (TI) feeds to assess the risk associated with security threats. Due to the volume and heterogeneity of data, it is prohibitive to manually analyze the threat information available in different loosely structured TI feeds. Thus, there is a need to develop automated methods to vet and extract actionable information from TI feeds. To this end, we present a machine learning pipeline to automatically detect vulnerability exploitation from TI feeds. We first model threat vocabulary in loosely structured TI feeds using state-of-the-art embedding techniques (Doc2Vec and BERT) and then use it to train a supervised machine learning classifier to detect exploitation of security vulnerabilities. We use our approach to identify exploitation events in 191 different TI feeds. Our longitudinal evaluation shows that it is able to accurately identify exploitation events from TI feeds only using past data for training and even on TI feeds withheld from training. Our proposed approach is useful for a variety of downstream tasks such as data-driven vulnerability risk assessment.
Benchmarking Adversarial Robustness of Compressed Deep Learning Models
Aug 16, 2023

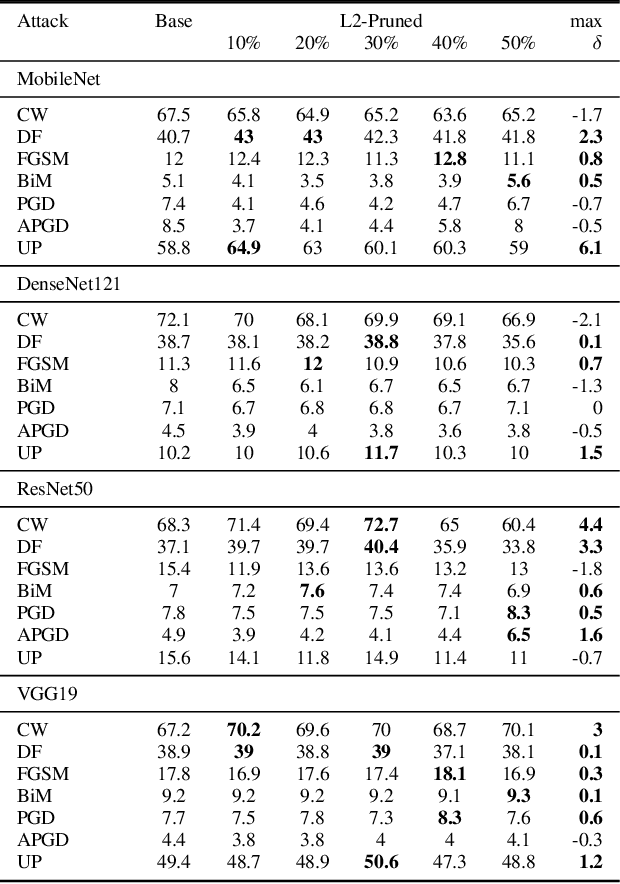

The increasing size of Deep Neural Networks (DNNs) poses a pressing need for model compression, particularly when employed on resource constrained devices. Concurrently, the susceptibility of DNNs to adversarial attacks presents another significant hurdle. Despite substantial research on both model compression and adversarial robustness, their joint examination remains underexplored. Our study bridges this gap, seeking to understand the effect of adversarial inputs crafted for base models on their pruned versions. To examine this relationship, we have developed a comprehensive benchmark across diverse adversarial attacks and popular DNN models. We uniquely focus on models not previously exposed to adversarial training and apply pruning schemes optimized for accuracy and performance. Our findings reveal that while the benefits of pruning enhanced generalizability, compression, and faster inference times are preserved, adversarial robustness remains comparable to the base model. This suggests that model compression while offering its unique advantages, does not undermine adversarial robustness.
PURL: Safe and Effective Sanitization of Link Decoration
Aug 07, 2023

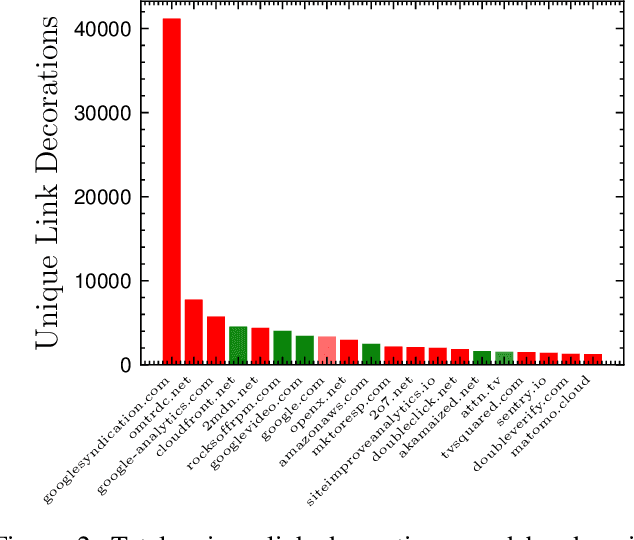
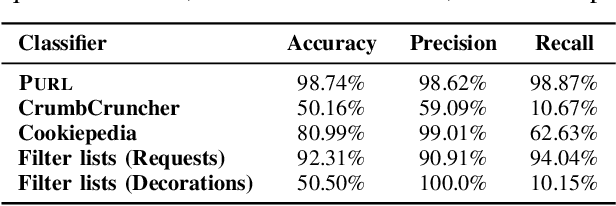
While privacy-focused browsers have taken steps to block third-party cookies and browser fingerprinting, novel tracking methods that bypass existing defenses continue to emerge. Since trackers need to exfiltrate information from the client- to server-side through link decoration regardless of the tracking technique they employ, a promising orthogonal approach is to detect and sanitize tracking information in decorated links. We present PURL, a machine-learning approach that leverages a cross-layer graph representation of webpage execution to safely and effectively sanitize link decoration. Our evaluation shows that PURL significantly outperforms existing countermeasures in terms of accuracy and reducing website breakage while being robust to common evasion techniques. We use PURL to perform a measurement study on top-million websites. We find that link decorations are widely abused by well-known advertisers and trackers to exfiltrate user information collected from browser storage, email addresses, and scripts involved in fingerprinting.
A Girl Has A Name, And It's Adversarial Authorship Attribution for Deobfuscation
Mar 22, 2022
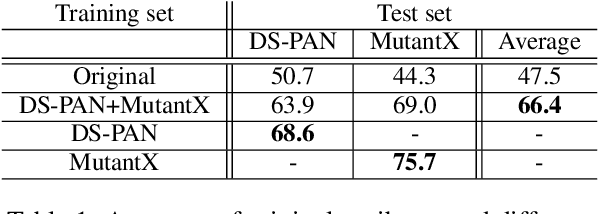
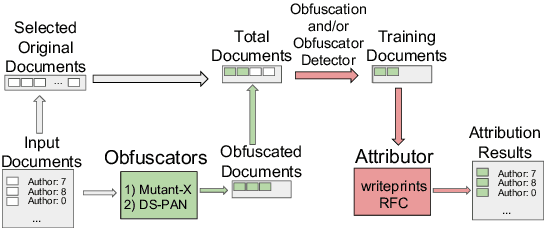
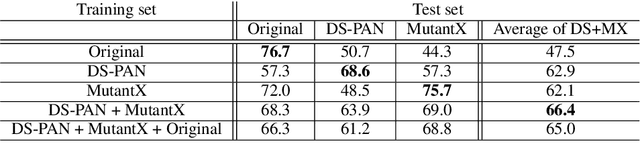
Recent advances in natural language processing have enabled powerful privacy-invasive authorship attribution. To counter authorship attribution, researchers have proposed a variety of rule-based and learning-based text obfuscation approaches. However, existing authorship obfuscation approaches do not consider the adversarial threat model. Specifically, they are not evaluated against adversarially trained authorship attributors that are aware of potential obfuscation. To fill this gap, we investigate the problem of adversarial authorship attribution for deobfuscation. We show that adversarially trained authorship attributors are able to degrade the effectiveness of existing obfuscators from 20-30% to 5-10%. We also evaluate the effectiveness of adversarial training when the attributor makes incorrect assumptions about whether and which obfuscator was used. While there is a a clear degradation in attribution accuracy, it is noteworthy that this degradation is still at or above the attribution accuracy of the attributor that is not adversarially trained at all. Our results underline the need for stronger obfuscation approaches that are resistant to deobfuscation
On The Robustness of Offensive Language Classifiers
Mar 21, 2022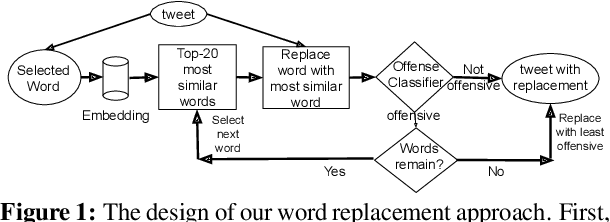
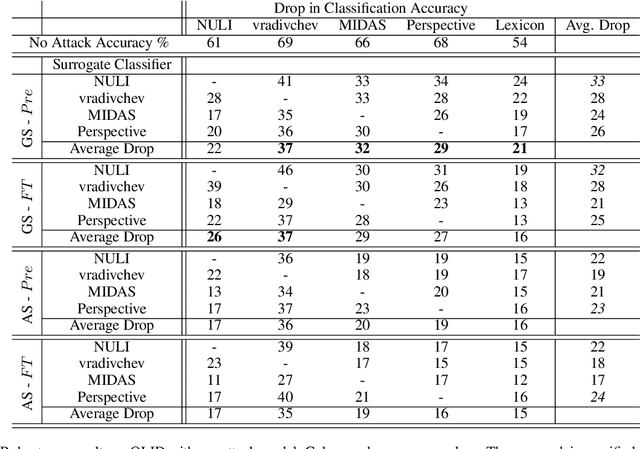
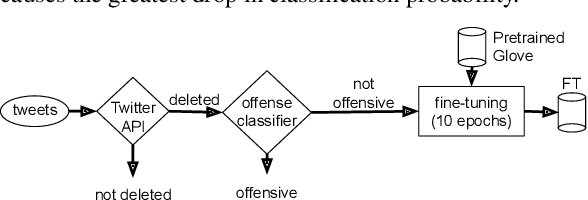

Social media platforms are deploying machine learning based offensive language classification systems to combat hateful, racist, and other forms of offensive speech at scale. However, despite their real-world deployment, we do not yet comprehensively understand the extent to which offensive language classifiers are robust against adversarial attacks. Prior work in this space is limited to studying robustness of offensive language classifiers against primitive attacks such as misspellings and extraneous spaces. To address this gap, we systematically analyze the robustness of state-of-the-art offensive language classifiers against more crafty adversarial attacks that leverage greedy- and attention-based word selection and context-aware embeddings for word replacement. Our results on multiple datasets show that these crafty adversarial attacks can degrade the accuracy of offensive language classifiers by more than 50% while also being able to preserve the readability and meaning of the modified text.
AutoFR: Automated Filter Rule Generation for Adblocking
Feb 25, 2022

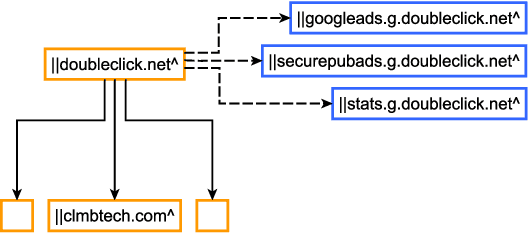

Adblocking relies on filter lists, which are manually curated and maintained by a small community of filter list authors. This manual process is laborious and does not scale well to a large number of sites and over time. We introduce AutoFR, a reinforcement learning framework to fully automate the process of filter rule creation and evaluation. We design an algorithm based on multi-arm bandits to generate filter rules while controlling the trade-off between blocking ads and avoiding breakage. We test our implementation of AutoFR on thousands of sites in terms of efficiency and effectiveness. AutoFR is efficient: it takes only a few minutes to generate filter rules for a site. AutoFR is also effective: it generates filter rules that can block 86% of the ads, as compared to 87% by EasyList while achieving comparable visual breakage. The filter rules generated by AutoFR generalize well to new and unseen sites. We envision AutoFR to assist the adblocking community in automated filter rule generation at scale.
HARPO: Learning to Subvert Online Behavioral Advertising
Nov 24, 2021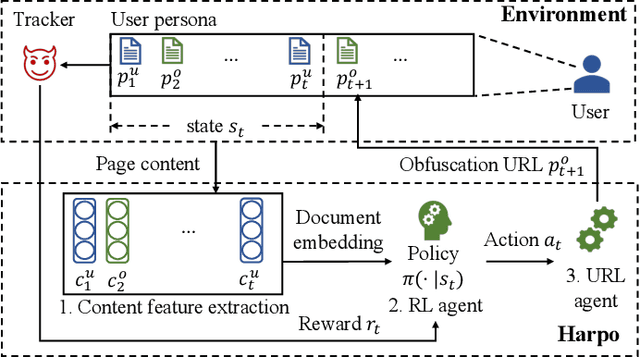


Online behavioral advertising, and the associated tracking paraphernalia, poses a real privacy threat. Unfortunately, existing privacy-enhancing tools are not always effective against online advertising and tracking. We propose Harpo, a principled learning-based approach to subvert online behavioral advertising through obfuscation. Harpo uses reinforcement learning to adaptively interleave real page visits with fake pages to distort a tracker's view of a user's browsing profile. We evaluate Harpo against real-world user profiling and ad targeting models used for online behavioral advertising. The results show that Harpo improves privacy by triggering more than 40% incorrect interest segments and 6x higher bid values. Harpo outperforms existing obfuscation tools by as much as 16x for the same overhead. Harpo is also able to achieve better stealthiness to adversarial detection than existing obfuscation tools. Harpo meaningfully advances the state-of-the-art in leveraging obfuscation to subvert online behavioral advertising
Avengers Ensemble! Improving Transferability of Authorship Obfuscation
Sep 15, 2021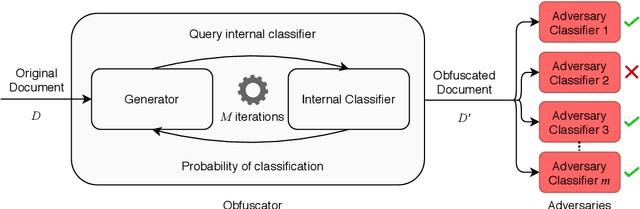

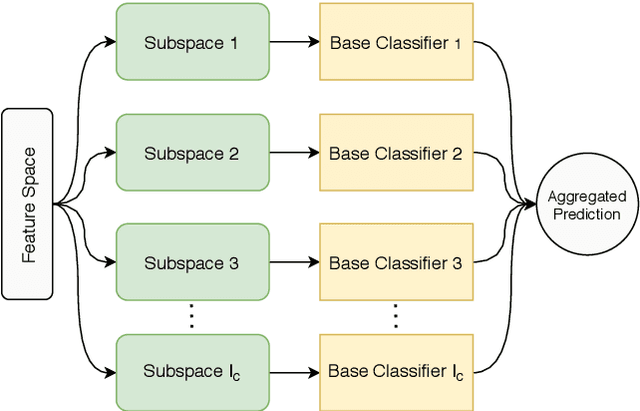
Stylometric approaches have been shown to be quite effective for real-world authorship attribution. To mitigate the privacy threat posed by authorship attribution, researchers have proposed automated authorship obfuscation approaches that aim to conceal the stylometric artefacts that give away the identity of an anonymous document's author. Recent work has focused on authorship obfuscation approaches that rely on black-box access to an attribution classifier to evade attribution while preserving semantics. However, to be useful under a realistic threat model, it is important that these obfuscation approaches work well even when the adversary's attribution classifier is different from the one used internally by the obfuscator. Unfortunately, existing authorship obfuscation approaches do not transfer well to unseen attribution classifiers. In this paper, we propose an ensemble-based approach for transferable authorship obfuscation. Our experiments show that if an obfuscator can evade an ensemble attribution classifier, which is based on multiple base attribution classifiers, it is more likely to transfer to different attribution classifiers. Our analysis shows that ensemble-based authorship obfuscation achieves better transferability because it combines the knowledge from each of the base attribution classifiers by essentially averaging their decision boundaries.