 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Bias Detection in MLMs and its Application to Human Trait Ratings
Feb 21, 2025There has been significant prior work using templates to study bias against demographic attributes in MLMs. However, these have limitations: they overlook random variability of templates and target concepts analyzed, assume equality amongst templates, and overlook bias quantification. Addressing these, we propose a systematic statistical approach to assess bias in MLMs, using mixed models to account for random effects, pseudo-perplexity weights for sentences derived from templates and quantify bias using statistical effect sizes. Replicating prior studies, we match on bias scores in magnitude and direction with small to medium effect sizes. Next, we explore the novel problem of gender bias in the context of $\textit{personality}$ and $\textit{character}$ traits, across seven MLMs (base and large). We find that MLMs vary; ALBERT is unbiased for binary gender but the most biased for non-binary $\textit{neo}$, while RoBERTa-large is the most biased for binary gender but shows small to no bias for $\textit{neo}$. There is some alignment of MLM bias and findings in psychology (human perspective) - in $\textit{agreeableness}$ with RoBERTa-large and $\textit{emotional stability}$ with BERT-large. There is general agreement for the remaining 3 personality dimensions: both sides observe at most small differences across gender. For character traits, human studies on gender bias are limited thus comparisons are not feasible.
C3PA: An Open Dataset of Expert-Annotated and Regulation-Aware Privacy Policies to Enable Scalable Regulatory Compliance Audits
Oct 04, 2024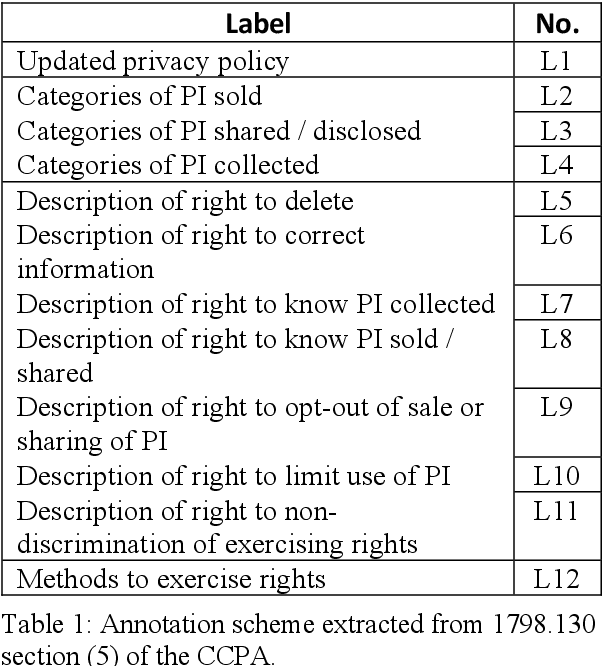
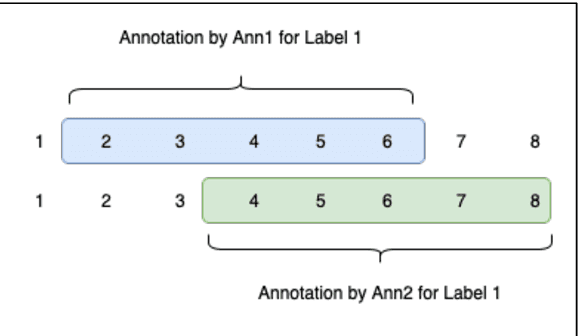

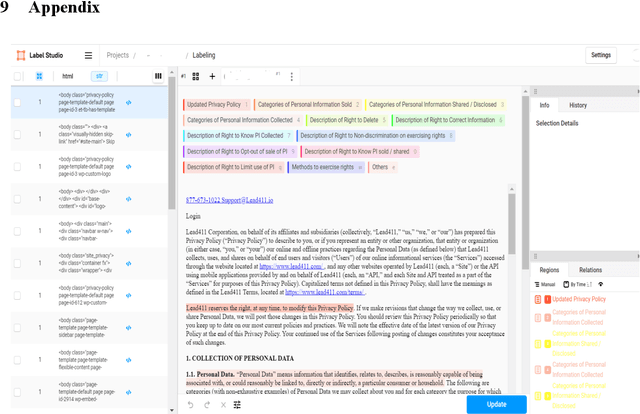
The development of tools and techniques to analyze and extract organizations data habits from privacy policies are critical for scalable regulatory compliance audits. Unfortunately, these tools are becoming increasingly limited in their ability to identify compliance issues and fixes. After all, most were developed using regulation-agnostic datasets of annotated privacy policies obtained from a time before the introduction of landmark privacy regulations such as EUs GDPR and Californias CCPA. In this paper, we describe the first open regulation-aware dataset of expert-annotated privacy policies, C3PA (CCPA Privacy Policy Provision Annotations), aimed to address this challenge. C3PA contains over 48K expert-labeled privacy policy text segments associated with responses to CCPA-specific disclosure mandates from 411 unique organizations. We demonstrate that the C3PA dataset is uniquely suited for aiding automated audits of compliance with CCPA-related disclosure mandates.
Style Matters! Investigating Linguistic Style in Online Communities
Sep 27, 2022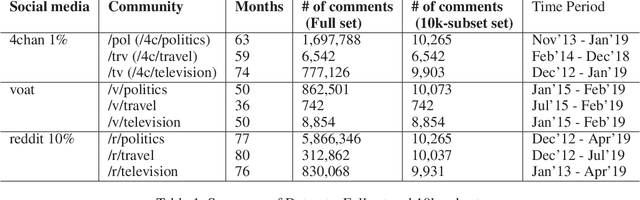
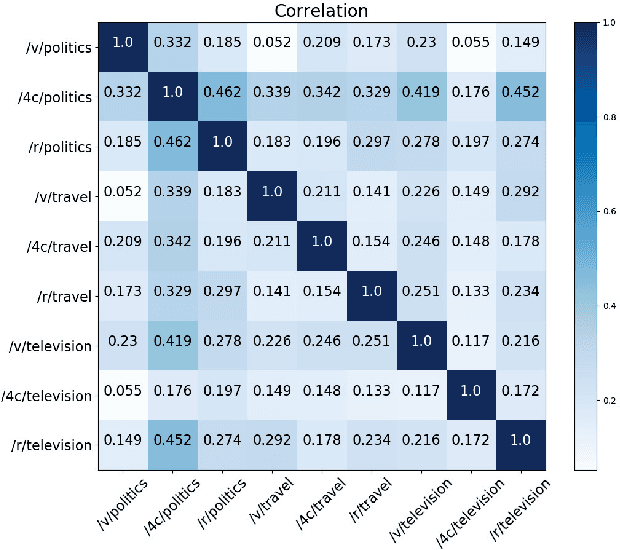

Content has historically been the primary lens used to study language in online communities. This paper instead focuses on the linguistic style of communities. While we know that individuals have distinguishable styles, here we ask whether communities have distinguishable styles. Additionally, while prior work has relied on a narrow definition of style, we employ a broad definition involving 262 features to analyze the linguistic style of 9 online communities from 3 social media platforms discussing politics, television and travel. We find that communities indeed have distinct styles. Also, style is an excellent predictor of group membership (F-score 0.952 and Accuracy 96.09%). While on average it is statistically equivalent to predictions using content alone, it is more resilient to reductions in training data.
Smells like Teen Spirit: An Exploration of Sensorial Style in Literary Genres
Sep 26, 2022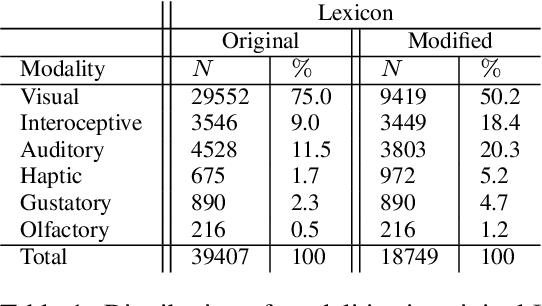
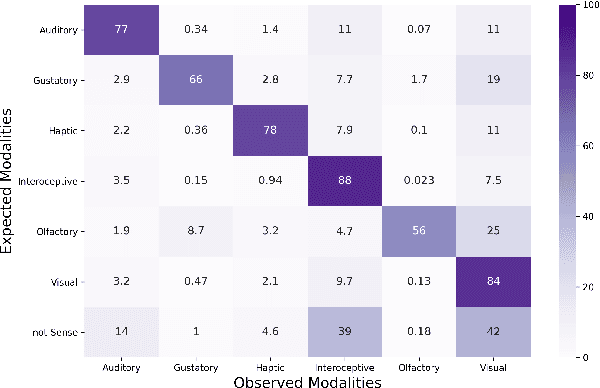
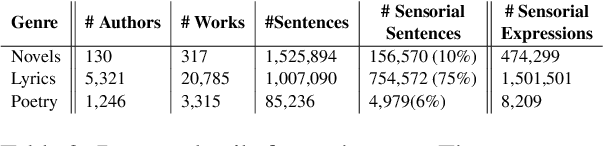
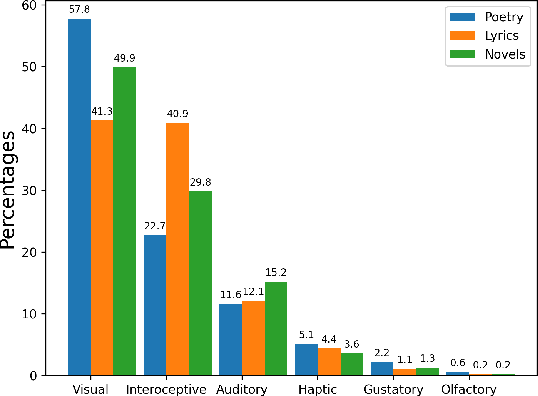
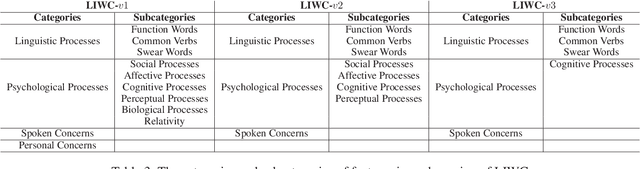
It is well recognized that sensory perceptions and language have interconnections through numerous studies in psychology, neuroscience, and sensorial linguistics. Set in this rich context we ask whether the use of sensorial language in writings is part of linguistic style? This question is important from the view of stylometrics research where a rich set of language features have been explored, but with insufficient attention given to features related to sensorial language. Taking this as the goal we explore several angles about sensorial language and style in collections of lyrics, novels, and poetry. We find, for example, that individual use of sensorial language is not a random phenomenon; choice is likely involved. Also, sensorial style is generally stable over time - the shifts are extremely small. Moreover, style can be extracted from just a few hundred sentences that have sensorial terms. We also identify representative and distinctive features within each genre. For example, we observe that 4 of the top 6 representative features in novels collection involved individuals using olfactory language where we expected them to use non-olfactory language.
Don't sweat the small stuff, classify the rest: Sample Shielding to protect text classifiers against adversarial attacks
May 03, 2022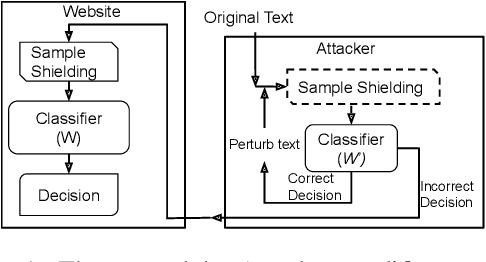
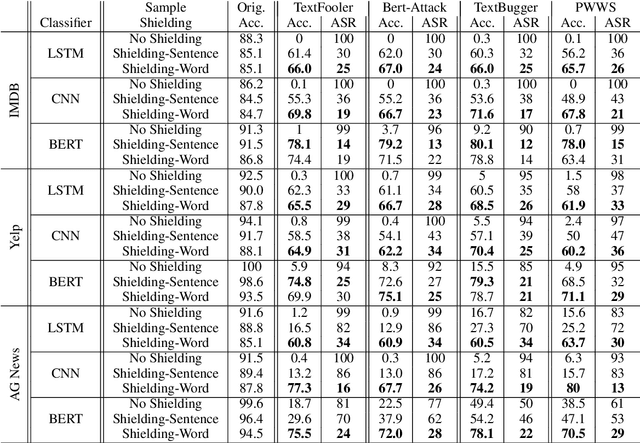
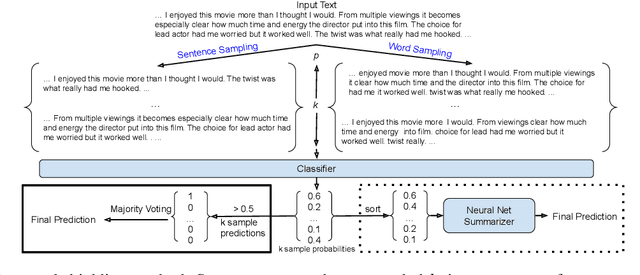

Deep learning (DL) is being used extensively for text classification. However, researchers have demonstrated the vulnerability of such classifiers to adversarial attacks. Attackers modify the text in a way which misleads the classifier while keeping the original meaning close to intact. State-of-the-art (SOTA) attack algorithms follow the general principle of making minimal changes to the text so as to not jeopardize semantics. Taking advantage of this we propose a novel and intuitive defense strategy called Sample Shielding. It is attacker and classifier agnostic, does not require any reconfiguration of the classifier or external resources and is simple to implement. Essentially, we sample subsets of the input text, classify them and summarize these into a final decision. We shield three popular DL text classifiers with Sample Shielding, test their resilience against four SOTA attackers across three datasets in a realistic threat setting. Even when given the advantage of knowing about our shielding strategy the adversary's attack success rate is <=10% with only one exception and often < 5%. Additionally, Sample Shielding maintains near original accuracy when applied to original texts. Crucially, we show that the `make minimal changes' approach of SOTA attackers leads to critical vulnerabilities that can be defended against with an intuitive sampling strategy.
A Girl Has A Name, And It's Adversarial Authorship Attribution for Deobfuscation
Mar 22, 2022
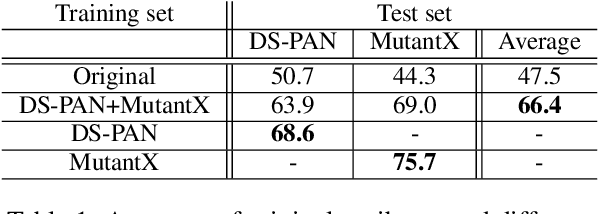
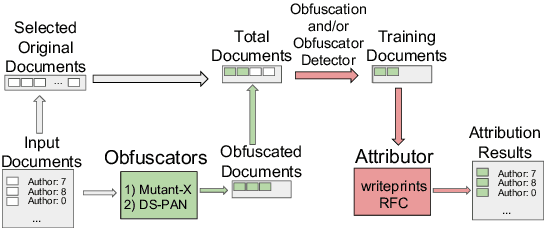
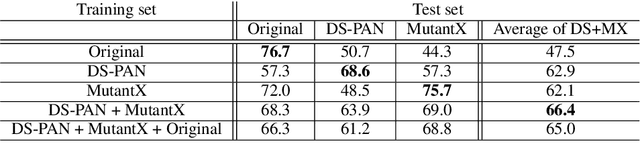
Recent advances in natural language processing have enabled powerful privacy-invasive authorship attribution. To counter authorship attribution, researchers have proposed a variety of rule-based and learning-based text obfuscation approaches. However, existing authorship obfuscation approaches do not consider the adversarial threat model. Specifically, they are not evaluated against adversarially trained authorship attributors that are aware of potential obfuscation. To fill this gap, we investigate the problem of adversarial authorship attribution for deobfuscation. We show that adversarially trained authorship attributors are able to degrade the effectiveness of existing obfuscators from 20-30% to 5-10%. We also evaluate the effectiveness of adversarial training when the attributor makes incorrect assumptions about whether and which obfuscator was used. While there is a a clear degradation in attribution accuracy, it is noteworthy that this degradation is still at or above the attribution accuracy of the attributor that is not adversarially trained at all. Our results underline the need for stronger obfuscation approaches that are resistant to deobfuscation
Suum Cuique: Studying Bias in Taboo Detection with a Community Perspective
Mar 22, 2022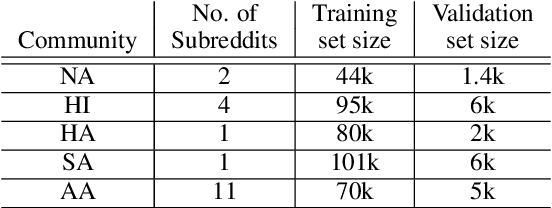
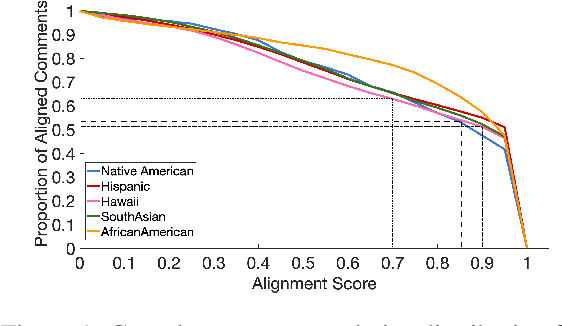
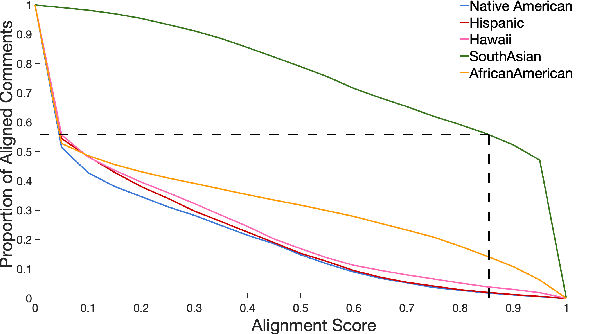
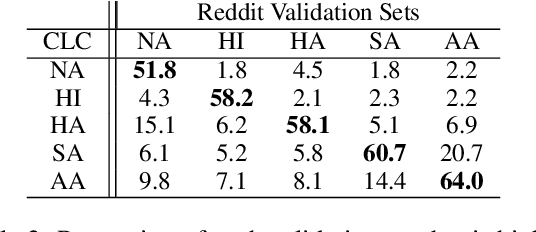
Prior research has discussed and illustrated the need to consider linguistic norms at the community level when studying taboo (hateful/offensive/toxic etc.) language. However, a methodology for doing so, that is firmly founded on community language norms is still largely absent. This can lead both to biases in taboo text classification and limitations in our understanding of the causes of bias. We propose a method to study bias in taboo classification and annotation where a community perspective is front and center. This is accomplished by using special classifiers tuned for each community's language. In essence, these classifiers represent community level language norms. We use these to study bias and find, for example, biases are largest against African Americans (7/10 datasets and all 3 classifiers examined). In contrast to previous papers we also study other communities and find, for example, strong biases against South Asians. In a small scale user study we illustrate our key idea which is that common utterances, i.e., those with high alignment scores with a community (community classifier confidence scores) are unlikely to be regarded taboo. Annotators who are community members contradict taboo classification decisions and annotations in a majority of instances. This paper is a significant step toward reducing false positive taboo decisions that over time harm minority communities.
On The Robustness of Offensive Language Classifiers
Mar 21, 2022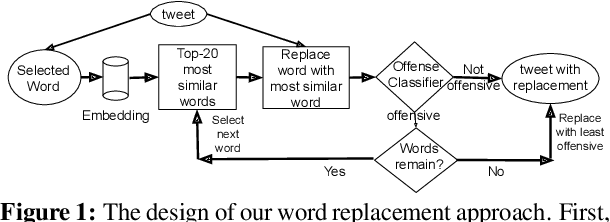
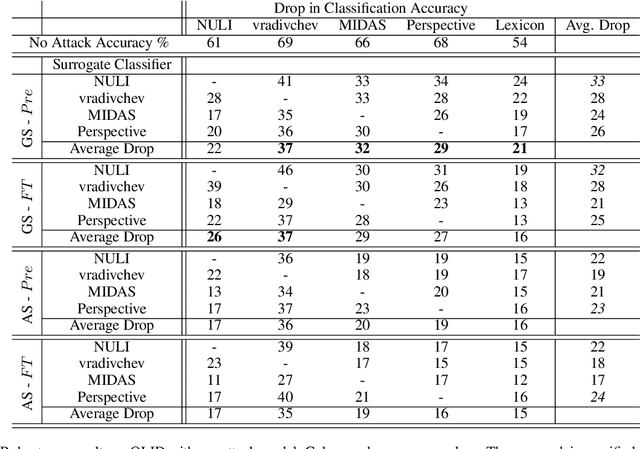
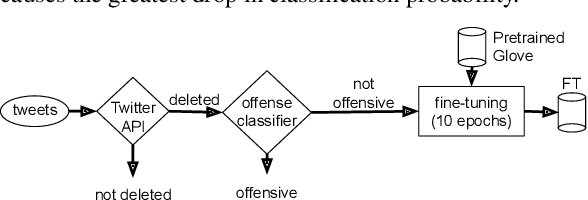

Social media platforms are deploying machine learning based offensive language classification systems to combat hateful, racist, and other forms of offensive speech at scale. However, despite their real-world deployment, we do not yet comprehensively understand the extent to which offensive language classifiers are robust against adversarial attacks. Prior work in this space is limited to studying robustness of offensive language classifiers against primitive attacks such as misspellings and extraneous spaces. To address this gap, we systematically analyze the robustness of state-of-the-art offensive language classifiers against more crafty adversarial attacks that leverage greedy- and attention-based word selection and context-aware embeddings for word replacement. Our results on multiple datasets show that these crafty adversarial attacks can degrade the accuracy of offensive language classifiers by more than 50% while also being able to preserve the readability and meaning of the modified text.
Avengers Ensemble! Improving Transferability of Authorship Obfuscation
Sep 15, 2021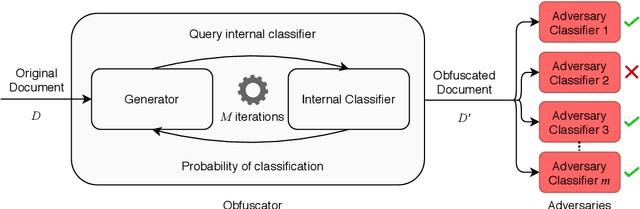

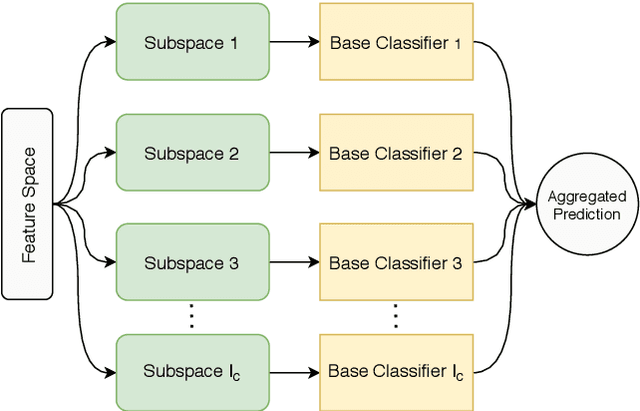
Stylometric approaches have been shown to be quite effective for real-world authorship attribution. To mitigate the privacy threat posed by authorship attribution, researchers have proposed automated authorship obfuscation approaches that aim to conceal the stylometric artefacts that give away the identity of an anonymous document's author. Recent work has focused on authorship obfuscation approaches that rely on black-box access to an attribution classifier to evade attribution while preserving semantics. However, to be useful under a realistic threat model, it is important that these obfuscation approaches work well even when the adversary's attribution classifier is different from the one used internally by the obfuscator. Unfortunately, existing authorship obfuscation approaches do not transfer well to unseen attribution classifiers. In this paper, we propose an ensemble-based approach for transferable authorship obfuscation. Our experiments show that if an obfuscator can evade an ensemble attribution classifier, which is based on multiple base attribution classifiers, it is more likely to transfer to different attribution classifiers. Our analysis shows that ensemble-based authorship obfuscation achieves better transferability because it combines the knowledge from each of the base attribution classifiers by essentially averaging their decision boundaries.
A Girl Has A Name: Detecting Authorship Obfuscation
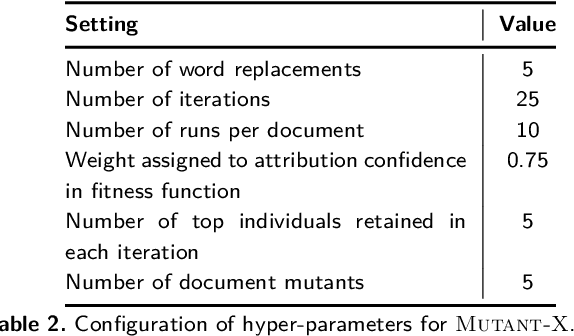
May 02, 2020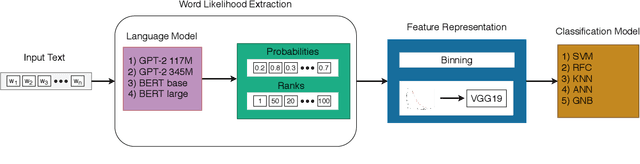
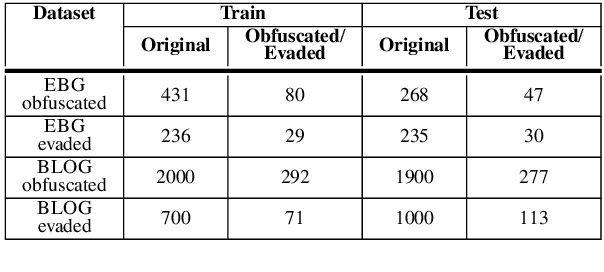
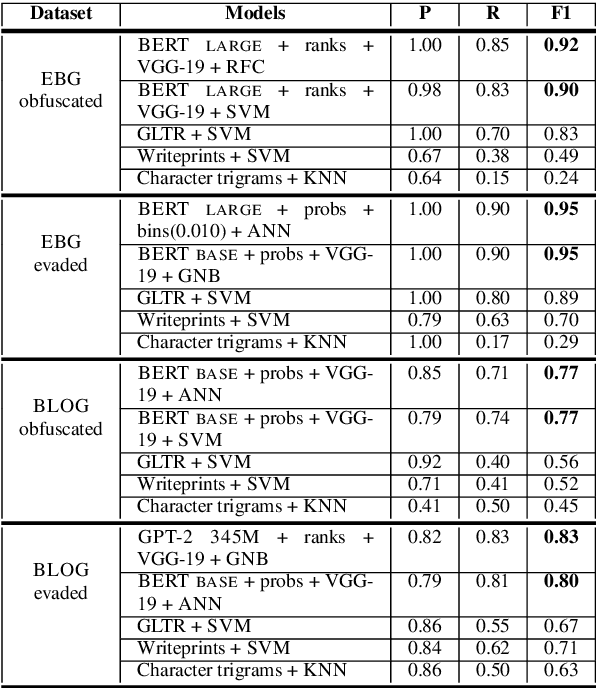
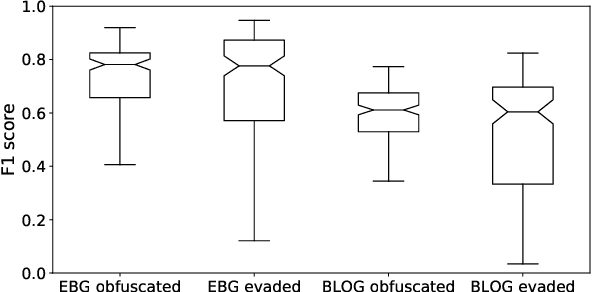
Authorship attribution aims to identify the author of a text based on the stylometric analysis. Authorship obfuscation, on the other hand, aims to protect against authorship attribution by modifying a text's style. In this paper, we evaluate the stealthiness of state-of-the-art authorship obfuscation methods under an adversarial threat model. An obfuscator is stealthy to the extent an adversary finds it challenging to detect whether or not a text modified by the obfuscator is obfuscated - a decision that is key to the adversary interested in authorship attribution. We show that the existing authorship obfuscation methods are not stealthy as their obfuscated texts can be identified with an average F1 score of 0.87. The reason for the lack of stealthiness is that these obfuscators degrade text smoothness, as ascertained by neural language models, in a detectable manner. Our results highlight the need to develop stealthy authorship obfuscation methods that can better protect the identity of an author seeking anonymity.