 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want to Believe (but the Vocabulary Changed): Measuring the Semantic Structure and Evolution of Conspiracy Theories
Mar 27, 2026Research on conspiracy theories has largely focused on belief formation, exposure, and diffusion, while paying less attention to how their meanings change over time. This gap persists partly because conspiracy-related terms are often treated as stable lexical markers, making it difficult to separate genuine semantic changes from surface-level vocabulary changes. In this paper, we measure the semantic structure and evolution of conspiracy theories in online political discourse. Using 169.9M comments from Reddit's r/politics subreddit spanning 2012--2022, we first demonstrate that conspiracy-related language forms coherent and semantically distinguishable regions of language space, allowing conspiracy theories to be treated as semantic objects. We then track how these objects evolve over time using aligned word embeddings, enabling comparisons of semantic neighborhoods across periods. Our analysis reveals that conspiracy theories evolve non-uniformly, exhibiting patterns of semantic stability, expansion, contraction, and replacement that are not captured by keyword-based approaches alone.
Style Matters! Investigating Linguistic Style in Online Communities
Sep 27, 2022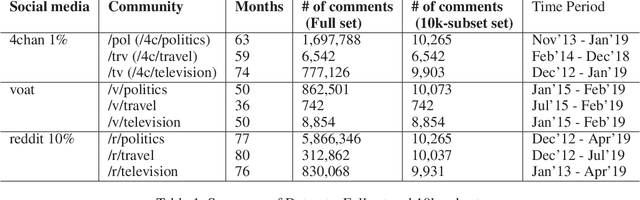
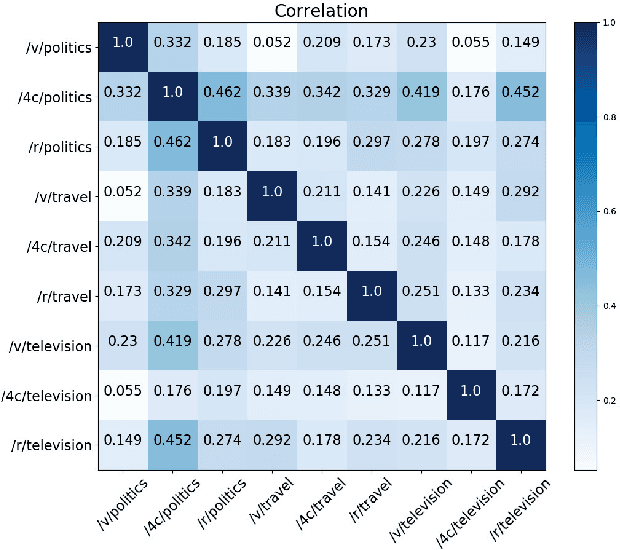

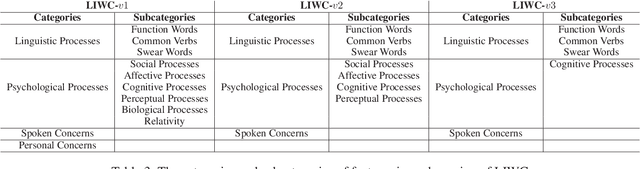
Content has historically been the primary lens used to study language in online communities. This paper instead focuses on the linguistic style of communities. While we know that individuals have distinguishable styles, here we ask whether communities have distinguishable styles. Additionally, while prior work has relied on a narrow definition of style, we employ a broad definition involving 262 features to analyze the linguistic style of 9 online communities from 3 social media platforms discussing politics, television and travel. We find that communities indeed have distinct styles. Also, style is an excellent predictor of group membership (F-score 0.952 and Accuracy 96.09%). While on average it is statistically equivalent to predictions using content alone, it is more resilient to reductions in training data.
Smells like Teen Spirit: An Exploration of Sensorial Style in Literary Genres
Sep 26, 2022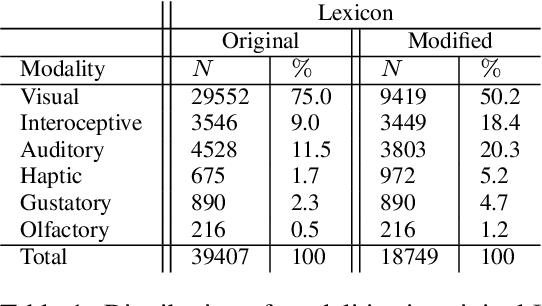
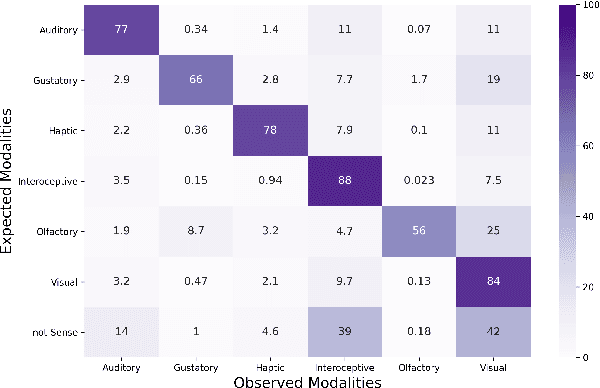
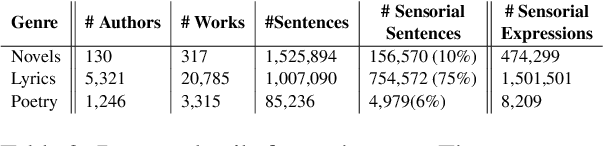
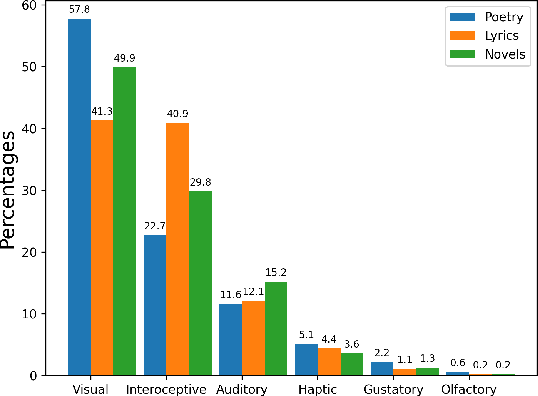
It is well recognized that sensory perceptions and language have interconnections through numerous studies in psychology, neuroscience, and sensorial linguistics. Set in this rich context we ask whether the use of sensorial language in writings is part of linguistic style? This question is important from the view of stylometrics research where a rich set of language features have been explored, but with insufficient attention given to features related to sensorial language. Taking this as the goal we explore several angles about sensorial language and style in collections of lyrics, novels, and poetry. We find, for example, that individual use of sensorial language is not a random phenomenon; choice is likely involved. Also, sensorial style is generally stable over time - the shifts are extremely small. Moreover, style can be extracted from just a few hundred sentences that have sensorial terms. We also identify representative and distinctive features within each genre. For example, we observe that 4 of the top 6 representative features in novels collection involved individuals using olfactory language where we expected them to use non-olfactory language.
Suum Cuique: Studying Bias in Taboo Detection with a Community Perspective
Mar 22, 2022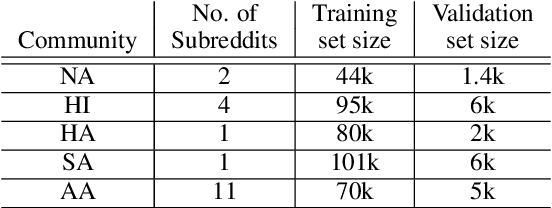
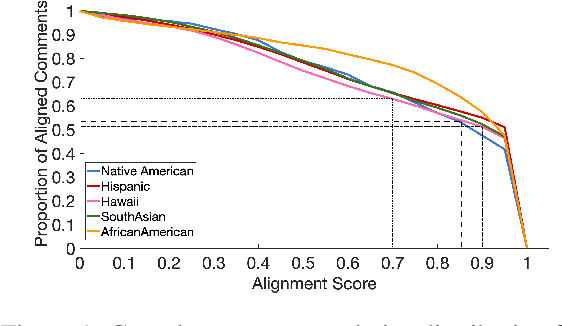
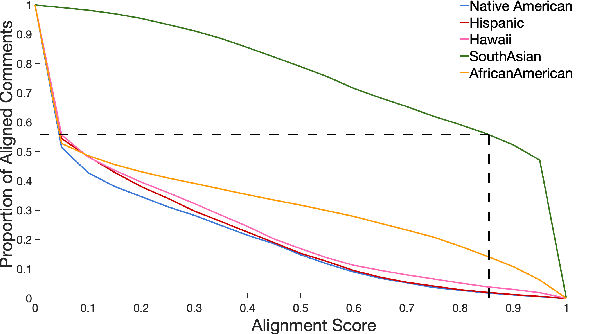
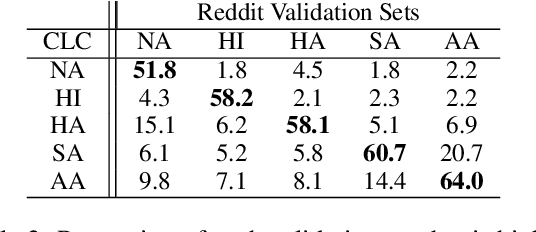
Prior research has discussed and illustrated the need to consider linguistic norms at the community level when studying taboo (hateful/offensive/toxic etc.) language. However, a methodology for doing so, that is firmly founded on community language norms is still largely absent. This can lead both to biases in taboo text classification and limitations in our understanding of the causes of bias. We propose a method to study bias in taboo classification and annotation where a community perspective is front and center. This is accomplished by using special classifiers tuned for each community's language. In essence, these classifiers represent community level language norms. We use these to study bias and find, for example, biases are largest against African Americans (7/10 datasets and all 3 classifiers examined). In contrast to previous papers we also study other communities and find, for example, strong biases against South Asians. In a small scale user study we illustrate our key idea which is that common utterances, i.e., those with high alignment scores with a community (community classifier confidence scores) are unlikely to be regarded taboo. Annotators who are community members contradict taboo classification decisions and annotations in a majority of instances. This paper is a significant step toward reducing false positive taboo decisions that over time harm minority communities.