 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want to Believe (but the Vocabulary Changed): Measuring the Semantic Structure and Evolution of Conspiracy Theories
Mar 27, 2026Research on conspiracy theories has largely focused on belief formation, exposure, and diffusion, while paying less attention to how their meanings change over time. This gap persists partly because conspiracy-related terms are often treated as stable lexical markers, making it difficult to separate genuine semantic changes from surface-level vocabulary changes. In this paper, we measure the semantic structure and evolution of conspiracy theories in online political discourse. Using 169.9M comments from Reddit's r/politics subreddit spanning 2012--2022, we first demonstrate that conspiracy-related language forms coherent and semantically distinguishable regions of language space, allowing conspiracy theories to be treated as semantic objects. We then track how these objects evolve over time using aligned word embeddings, enabling comparisons of semantic neighborhoods across periods. Our analysis reveals that conspiracy theories evolve non-uniformly, exhibiting patterns of semantic stability, expansion, contraction, and replacement that are not captured by keyword-based approaches alone.
Examining the Role of YouTube Production and Consumption Dynamics on the Formation of Extreme Ideologies
Mar 09, 2026The relationship between content production and consumption on algorithm-driven platforms like YouTube plays a critical role in shaping ideological behaviors. While prior work has largely focused on user behavior and algorithmic recommendations, the interplay between what is produced and what gets consumed, and its role in ideological shifts remains understudied. In this paper, we present a longitudinal, mixed-methods analysis combining one year of YouTube watch history with two waves of ideological surveys from 1,100 U.S. participants. We identify users who exhibited significant shifts toward more extreme ideologies and compare their content consumption and the production patterns of YouTube channels they engaged with to ideologically stable users. Our findings show that users who became more extreme consumed have different consumption habits from those who do not. This gets amplified by the fact that channels favored by users with extreme ideologies also have a higher affinity to produce content with a higher anger, grievance and other such markers. Lastly, using time series analysis, we examine whether content producers are the primary drivers of consumption behavior or merely responding to user demand.
Turning Trust to Transactions: Tracking Affiliate Marketing and FTC Compliance in YouTube's Influencer Economy
Mar 04, 2026YouTube has evolved into a powerful platform that where creators monetize their influence through affiliate marketing, raising concerns about transparency and ethics, especially when creators fail to disclose their affiliate relationships. Although regulatory agencies like the US Federal Trade Commission (FTC) have issued guidelines to address these issues, non-compliance and consumer harm persist, and the extent of these problems remains unclear. In this paper, we introduce tools, developed with insights from recent advances in Web measurement and NLP research, to examine the state of the affiliate marketing ecosystem on YouTube. We apply these tools to a 10-year dataset of 2 million videos from nearly 540,000 creators, analyzing the prevalence of affiliate marketing on YouTube and the rates of non-compliant behavior. Our findings reveal that affiliate links are widespread, yet dis- closure compliance remains low, with most videos failing to meet FTC standards. Furthermore, we analyze the effects of different stakeholders in improving disclosure behavior. Our study suggests that the platform is highly associated with improved compliance through standardized disclosure features. We recommend that regulators and affiliate partners collaborate with platforms to enhance transparency, accountability, and trust in the influencer economy.
On the Suitability of LLM-Driven Agents for Dark Pattern Audits
Mar 04, 2026As LLM-driven agents begin to autonomously navigate the web, their ability to interpret and respond to manipulative interface design becomes critical. A fundamental question that emerges is: can such agents reliably recognize patterns of friction, misdirection, and coercion in interface design (i.e., dark patterns)? We study this question in a setting where the workflows are consequential: website portals associated with the submission of CCPA-related data rights requests. These portals operationalize statutory rights, but they are implemented as interactive interfaces whose design can be structured to facilitate, burden, or subtly discourage the exercise of those rights. We design and deploy an LLM-driven auditing agent capable of end-to-end traversal of rights-request workflows, structured evidence gathering, and classification of potential dark patterns. Across a set of 456 data broker websites, we evaluate: (1) the ability of the agent to consistently locate and complete request flows, (2) the reliability and reproducibility of its dark pattern classifications, and (3) the conditions under which it fails or produces poor judgments. Our findings characterize both the feasibility and the limitations of using LLM-driven agents for scalable dark pattern auditing.
C3PA: An Open Dataset of Expert-Annotated and Regulation-Aware Privacy Policies to Enable Scalable Regulatory Compliance Audits
Oct 04, 2024
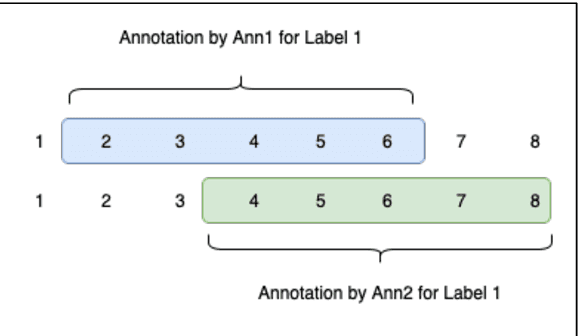

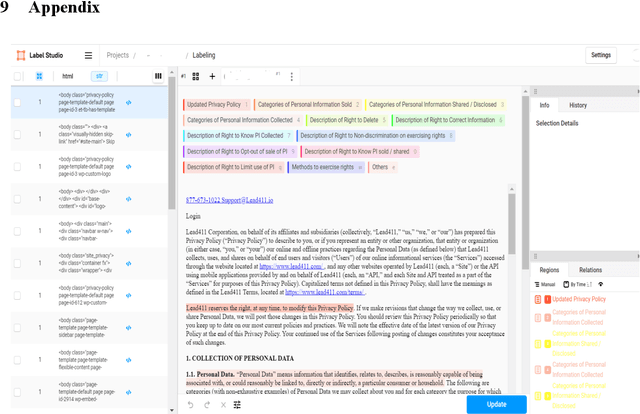
The development of tools and techniques to analyze and extract organizations data habits from privacy policies are critical for scalable regulatory compliance audits. Unfortunately, these tools are becoming increasingly limited in their ability to identify compliance issues and fixes. After all, most were developed using regulation-agnostic datasets of annotated privacy policies obtained from a time before the introduction of landmark privacy regulations such as EUs GDPR and Californias CCPA. In this paper, we describe the first open regulation-aware dataset of expert-annotated privacy policies, C3PA (CCPA Privacy Policy Provision Annotations), aimed to address this challenge. C3PA contains over 48K expert-labeled privacy policy text segments associated with responses to CCPA-specific disclosure mandates from 411 unique organizations. We demonstrate that the C3PA dataset is uniquely suited for aiding automated audits of compliance with CCPA-related disclosure mandates.
Algorithmic amplification of biases on Google Search
Jan 17, 2024The evolution of information-seeking processes, driven by search engines like Google, has transformed the access to information people have. This paper investigates how individuals' preexisting attitudes influence the modern information-seeking process, specifically the results presented by Google Search. Through a comprehensive study involving surveys and information-seeking tasks focusing on the topic of abortion, the paper provides four crucial insights: 1) Individuals with opposing attitudes on abortion receive different search results. 2) Individuals express their beliefs in their choice of vocabulary used in formulating the search queries, shaping the outcome of the search. 3) Additionally, the user's search history contributes to divergent results among those with opposing attitudes. 4) Google Search engine reinforces preexisting beliefs in search results. Overall, this study provides insights into the interplay between human biases and algorithmic processes, highlighting the potential for information polarization in modern information-seeking processes.
How Auditing Methodologies Can Impact Our Understanding of YouTube's Recommendation Systems
Mar 06, 2023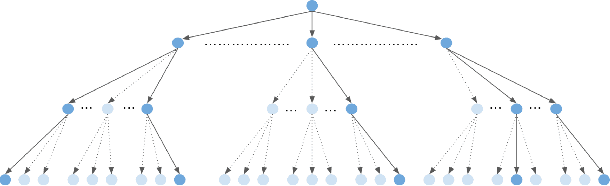
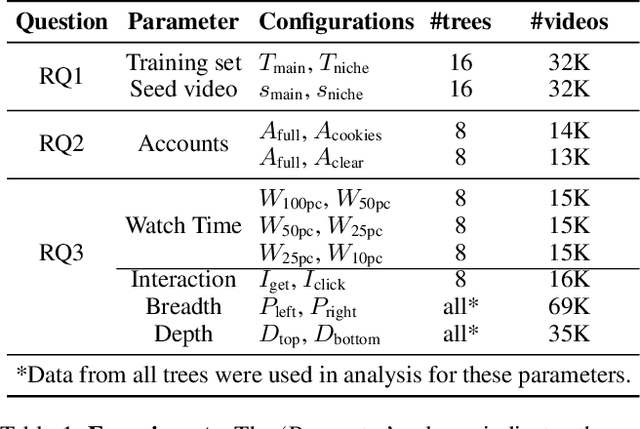


Data generated by audits of social media websites have formed the basis of our understanding of the biases presented in algorithmic content recommendation systems. As legislators around the world are beginning to consider regulating the algorithmic systems that drive online platforms, it is critical to ensure the correctness of these inferred biases. However, as we will show in this paper, doing so is a challenging task for a variety of reasons related to the complexity of configuration parameters associated with the audits that gather data from a specific platform. Focusing specifically on YouTube, we show that conducting audits to make inferences about YouTube's recommendation systems is more methodologically challenging than one might expect. There are many methodological decisions that need to be considered in order to obtain scientifically valid results, and each of these decisions incur costs. For example, should an auditor use (expensive to obtain) logged-in YouTube accounts while gathering recommendations from the algorithm to obtain more accurate inferences? We explore the impact of this and many other decisions and make some startling discoveries about the methodological choices that impact YouTube's recommendations. Taken all together, our research suggests auditing configuration compromises that YouTube auditors and researchers can use to reduce audit overhead, both economically and computationally, without sacrificing accuracy of their inferences. Similarly, we also identify several configuration parameters that have a significant impact on the accuracy of measured inferences and should be carefully considered.
Measuring Offensive Speech in Online Political Discourse
Jul 19, 2017



The Internet and online forums such as Reddit have become an increasingly popular medium for citizens to engage in political conversations. However, the online disinhibition effect resulting from the ability to use pseudonymous identities may manifest in the form of offensive speech, consequently making political discussions more aggressive and polarizing than they already are. Such environments may result in harassment and self-censorship from its targets. In this paper, we present preliminary results from a large-scale temporal measurement aimed at quantifying offensiveness in online political discussions. To enable our measurements, we develop and evaluate an offensive speech classifier. We then use this classifier to quantify and compare offensiveness in the political and general contexts. We perform our study using a database of over 168M Reddit comments made by over 7M pseudonyms between January 2015 and January 2017 -- a period covering several divisive political events including the 2016 US presidential elections.