 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnAD: Learning Interpretable Rules for Brain Networks in Alzheimer's Disease Classification
Dec 30, 2025We introduce LearnAD, a neuro-symbolic method for predicting Alzheimer's disease from brain magnetic resonance imaging data, learning fully interpretable rules. LearnAD applies statistical models, Decision Trees, Random Forests, or GNNs to identify relevant brain connections, and then employs FastLAS to learn global rules. Our best instance outperforms Decision Trees, matches Support Vector Machine accuracy, and performs only slightly below Random Forests and GNNs trained on all features, all while remaining fully interpretable. Ablation studies show that our neuro-symbolic approach improves interpretability with comparable performance to pure statistical models. LearnAD demonstrates how symbolic learning can deepen our understanding of GNN behaviour in clinical neuroscience.
Deep Unlearn: Benchmarking Machine Unlearning
Oct 02, 2024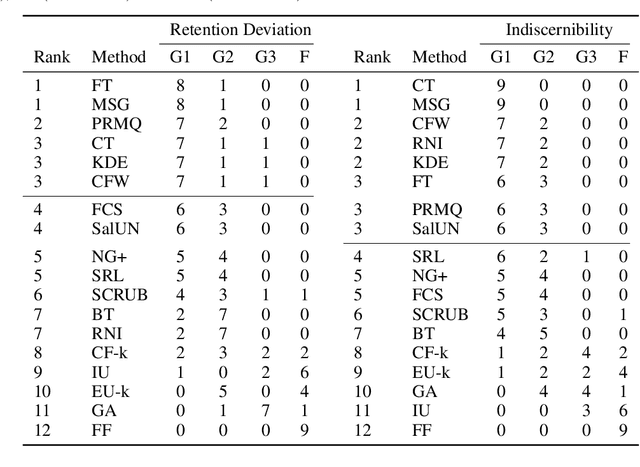
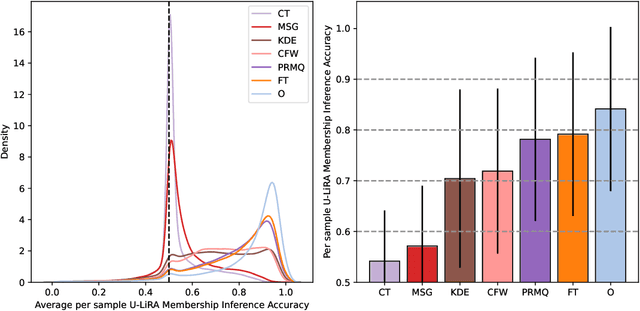
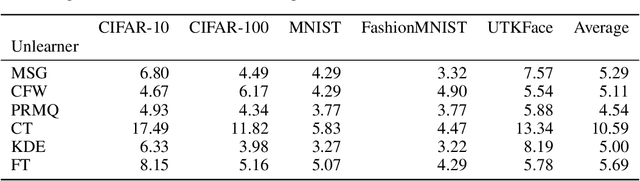
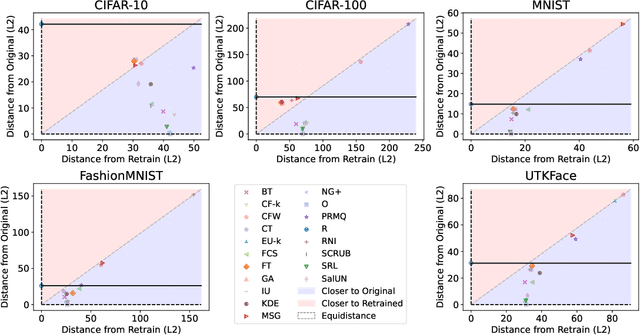
Machine unlearning (MU) aims to remove the influence of particular data points from the learnable parameters of a trained machine learning model. This is a crucial capability in light of data privacy requirements, trustworthiness, and safety in deployed models. MU is particularly challenging for deep neural networks (DNNs), such as convolutional nets or vision transformers, as such DNNs tend to memorize a notable portion of their training dataset. Nevertheless, the community lacks a rigorous and multifaceted study that looks into the success of MU methods for DNNs. In this paper, we investigate 18 state-of-the-art MU methods across various benchmark datasets and models, with each evaluation conducted over 10 different initializations, a comprehensive evaluation involving MU over 100K models. We show that, with the proper hyperparameters, Masked Small Gradients (MSG) and Convolution Transpose (CT), consistently perform better in terms of model accuracy and run-time efficiency across different models, datasets, and initializations, assessed by population-based membership inference attacks (MIA) and per-sample unlearning likelihood ratio attacks (U-LiRA). Furthermore, our benchmark highlights the fact that comparing a MU method only with commonly used baselines, such as Gradient Ascent (GA) or Successive Random Relabeling (SRL), is inadequate, and we need better baselines like Negative Gradient Plus (NG+) with proper hyperparameter selection.
A Study on the Reliability of Automatic Dysarthric Speech Assessments
Jun 07, 2023

Automating dysarthria assessments offers the opportunity to develop effective, low-cost tools that address the current limitations of manual and subjective assessments. Nonetheless, it is unclear whether current approaches rely on dysarthria-related speech patterns or external factors. We aim toward obtaining a clearer understanding of dysarthria patterns. To this extent, we study the effects of noise in recordings, both through addition and reduction. We design and implement a new method for visualizing and comparing feature extractors and models, at a patient level, in a more interpretable way. We use the UA-Speech dataset with a speaker-based split of the dataset. Results reported in the literature appear to have been done irrespective of such split, leading to models that may be overconfident due to data-leakage. We hope that these results raise awareness in the research community regarding the requirements for establishing reliable automatic dysarthria assessment systems.
Evaluating The Robustness of Self-Supervised Representations to Background/Foreground Removal
Jun 02, 2023Despite impressive empirical advances of SSL in solving various tasks, the problem of understanding and characterizing SSL representations learned from input data remains relatively under-explored. We provide a comparative analysis of how the representations produced by SSL models differ when masking parts of the input. Specifically, we considered state-of-the-art SSL pretrained models, such as DINOv2, MAE, and SwaV, and analyzed changes at the representation levels across 4 Image Classification datasets. First, we generate variations of the datasets by applying foreground and background segmentation. Then, we conduct statistical analysis using Canonical Correlation Analysis (CCA) and Centered Kernel Alignment (CKA) to evaluate the robustness of the representations learned in SSL models. Empirically, we show that not all models lead to representations that separate foreground, background, and complete images. Furthermore, we test different masking strategies by occluding the center regions of the images to address cases where foreground and background are difficult. For example, the DTD dataset that focuses on texture rather specific objects.
FIB: A Method for Evaluation of Feature Impact Balance in Multi-Dimensional Data
Jul 10, 2022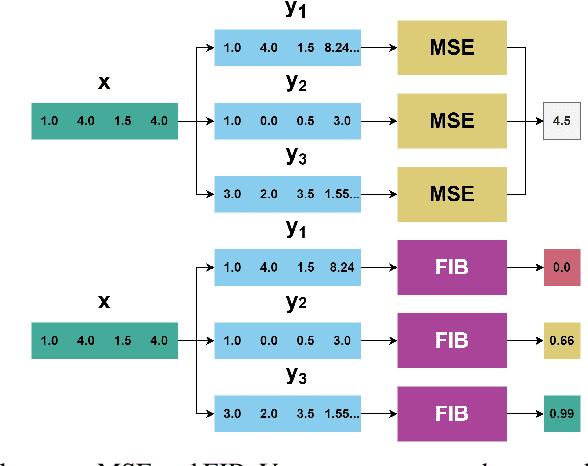

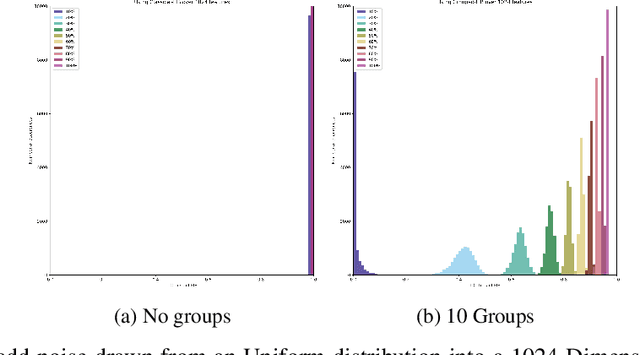

Errors might not have the same consequences depending on the task at hand. Nevertheless, there is limited research investigating the impact of imbalance in the contribution of different features in an error vector. Therefore, we propose the Feature Impact Balance (FIB) score. It measures whether there is a balanced impact of features in the discrepancies between two vectors. We designed the FIB score to lie in [0, 1]. Scores close to 0 indicate that a small number of features contribute to most of the error, and scores close to 1 indicate that most features contribute to the error equally. We experimentally study the FIB on different datasets, using AutoEncoders and Variational AutoEncoders. We show how the feature impact balance varies during training and showcase its usability to support model selection for single output and multi-output tasks.