 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody-Driven Privacy-Preserving Dementia Detection
Jul 03, 2024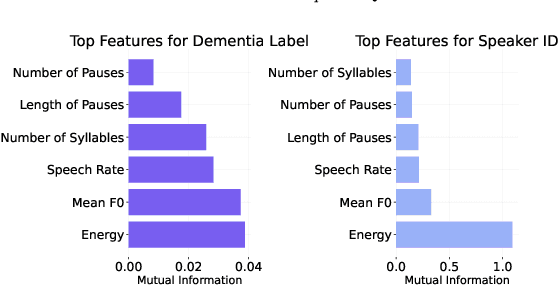
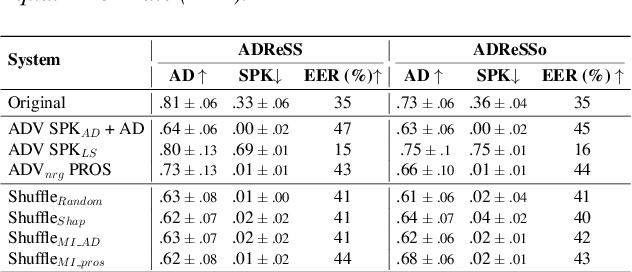
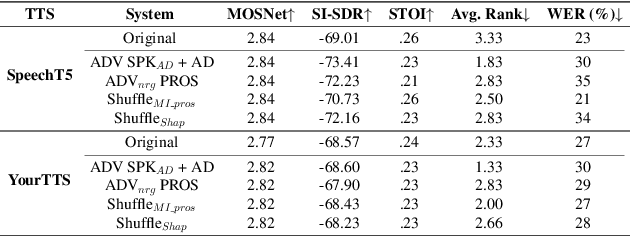
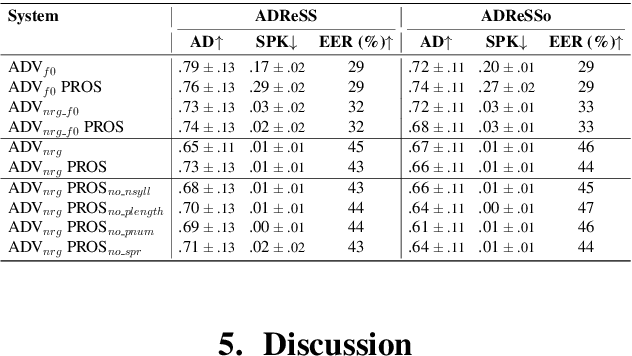
Speaker embeddings extracted from voice recordings have been proven valuable for dementia detection. However, by their nature, these embeddings contain identifiable information which raises privacy concerns. In this work, we aim to anonymize embeddings while preserving the diagnostic utility for dementia detection. Previous studies rely on adversarial learning and models trained on the target attribute and struggle in limited-resource settings. We propose a novel approach that leverages domain knowledge to disentangle prosody features relevant to dementia from speaker embeddings without relying on a dementia classifier. Our experiments show the effectiveness of our approach in preserving speaker privacy (speaker recognition F1-score .01%) while maintaining high dementia detection score F1-score of 74% on the ADReSS dataset. Our results are also on par with a more constrained classifier-dependent system on ADReSSo (.01% and .66%), and have no impact on synthesized speech naturalness.
MicroT: Low-Energy and Adaptive Models for MCUs
Mar 12, 2024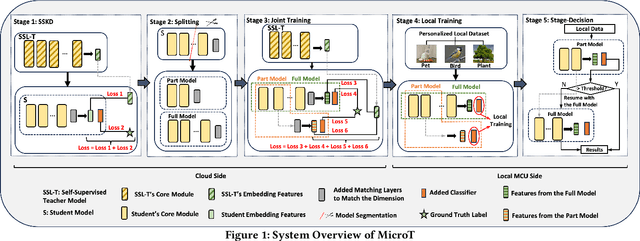


We propose MicroT, a low-energy, multi-task adaptive model framework for resource-constrained MCUs. We divide the original model into a feature extractor and a classifier. The feature extractor is obtained through self-supervised knowledge distillation and further optimized into part and full models through model splitting and joint training. These models are then deployed on MCUs, with classifiers added and trained on local tasks, ultimately performing stage-decision for joint inference. In this process, the part model initially processes the sample, and if the confidence score falls below the set threshold, the full model will resume and continue the inference. We evaluate MicroT on two models, three datasets, and two MCU boards. Our experimental evaluation shows that MicroT effectively improves model performance and reduces energy consumption when dealing with multiple local tasks. Compared to the unoptimized feature extractor, MicroT can improve accuracy by up to 9.87%. On MCUs, compared to the standard full model inference, MicroT can save up to about 29.13% in energy consumption. MicroT also allows users to adaptively adjust the stage-decision ratio as needed, better balancing model performance and energy consumption. Under the standard stage-decision ratio configuration, MicroT can increase accuracy by 5.91% and save about 14.47% of energy consumption.
A Study on the Reliability of Automatic Dysarthric Speech Assessments
Jun 07, 2023

Automating dysarthria assessments offers the opportunity to develop effective, low-cost tools that address the current limitations of manual and subjective assessments. Nonetheless, it is unclear whether current approaches rely on dysarthria-related speech patterns or external factors. We aim toward obtaining a clearer understanding of dysarthria patterns. To this extent, we study the effects of noise in recordings, both through addition and reduction. We design and implement a new method for visualizing and comparing feature extractors and models, at a patient level, in a more interpretable way. We use the UA-Speech dataset with a speaker-based split of the dataset. Results reported in the literature appear to have been done irrespective of such split, leading to models that may be overconfident due to data-leakage. We hope that these results raise awareness in the research community regarding the requirements for establishing reliable automatic dysarthria assessment systems.
Evaluating The Robustness of Self-Supervised Representations to Background/Foreground Removal
Jun 02, 2023Despite impressive empirical advances of SSL in solving various tasks, the problem of understanding and characterizing SSL representations learned from input data remains relatively under-explored. We provide a comparative analysis of how the representations produced by SSL models differ when masking parts of the input. Specifically, we considered state-of-the-art SSL pretrained models, such as DINOv2, MAE, and SwaV, and analyzed changes at the representation levels across 4 Image Classification datasets. First, we generate variations of the datasets by applying foreground and background segmentation. Then, we conduct statistical analysis using Canonical Correlation Analysis (CCA) and Centered Kernel Alignment (CKA) to evaluate the robustness of the representations learned in SSL models. Empirically, we show that not all models lead to representations that separate foreground, background, and complete images. Furthermore, we test different masking strategies by occluding the center regions of the images to address cases where foreground and background are difficult. For example, the DTD dataset that focuses on texture rather specific objects.
A Tandem Framework Balancing Privacy and Security for Voice User Interfaces
Jul 21, 2021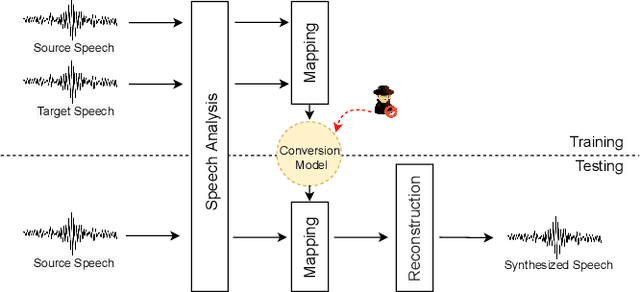

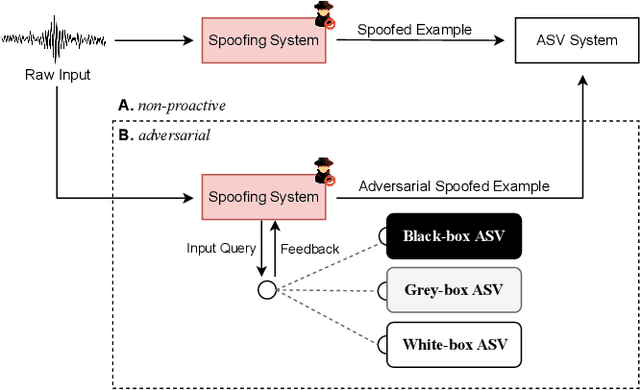
Speech synthesis, voice cloning, and voice conversion techniques present severe privacy and security threats to users of voice user interfaces (VUIs). These techniques transform one or more elements of a speech signal, e.g., identity and emotion, while preserving linguistic information. Adversaries may use advanced transformation tools to trigger a spoofing attack using fraudulent biometrics for a legitimate speaker. Conversely, such techniques have been used to generate privacy-transformed speech by suppressing personally identifiable attributes in the voice signals, achieving anonymization. Prior works have studied the security and privacy vectors in parallel, and thus it raises alarm that if a benign user can achieve privacy by a transformation, it also means that a malicious user can break security by bypassing the anti-spoofing mechanism. In this paper, we take a step towards balancing two seemingly conflicting requirements: security and privacy. It remains unclear what the vulnerabilities in one domain imply for the other, and what dynamic interactions exist between them. A better understanding of these aspects is crucial for assessing and mitigating vulnerabilities inherent with VUIs and building effective defenses. In this paper,(i) we investigate the applicability of the current voice anonymization methods by deploying a tandem framework that jointly combines anti-spoofing and authentication models, and evaluate the performance of these methods;(ii) examining analytical and empirical evidence, we reveal a duality between the two mechanisms as they offer different ways to achieve the same objective, and we show that leveraging one vector significantly amplifies the effectiveness of the other;(iii) we demonstrate that to effectively defend from potential attacks against VUIs, it is necessary to investigate the attacks from multiple complementary perspectives(security and privacy).
Configurable Privacy-Preserving Automatic Speech Recognition
Apr 01, 2021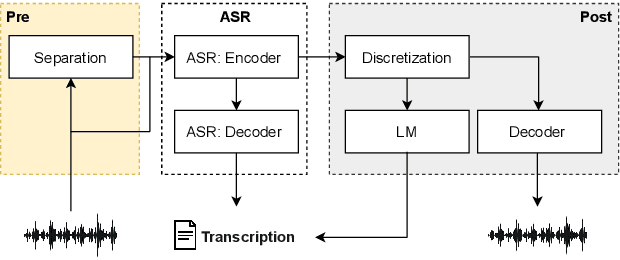


Voice assistive technologies have given rise to far-reaching privacy and security concerns. In this paper we investigate whether modular automatic speech recognition (ASR) can improve privacy in voice assistive systems by combining independently trained separation, recognition, and discretization modules to design configurable privacy-preserving ASR systems. We evaluate privacy concerns and the effects of applying various state-of-the-art techniques at each stage of the system, and report results using task-specific metrics (i.e. WER, ABX, and accuracy). We show that overlapping speech inputs to ASR systems present further privacy concerns, and how these may be mitigated using speech separation and optimization techniques. Our discretization module is shown to minimize paralinguistics privacy leakage from ASR acoustic models to levels commensurate with random guessing. We show that voice privacy can be configurable, and argue this presents new opportunities for privacy-preserving applications incorporating ASR.
Paralinguistic Privacy Protection at the Edge
Nov 04, 2020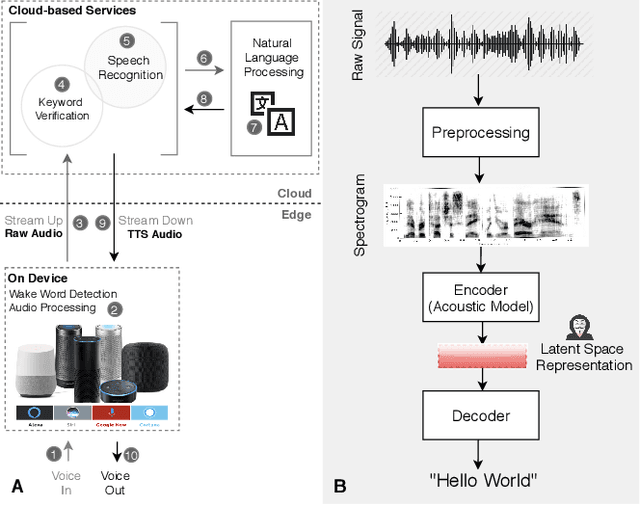
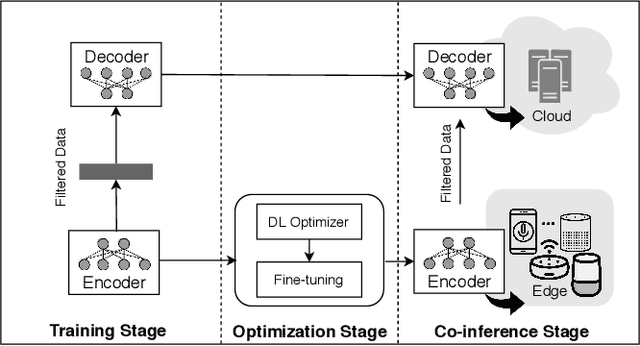
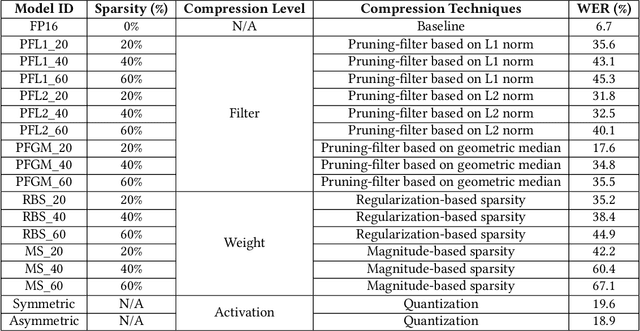
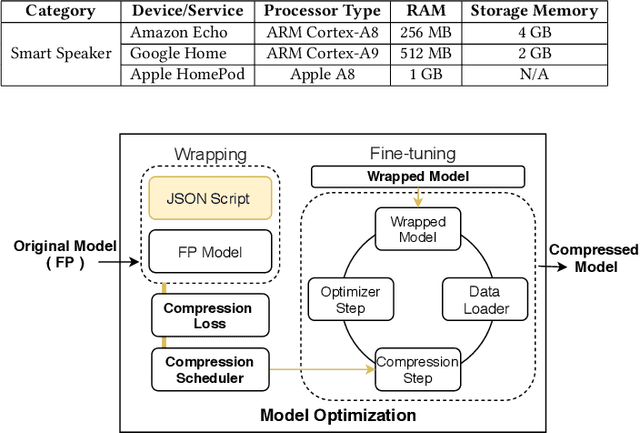
Voice user interfaces and digital assistants are rapidly entering our homes and becoming integrated with all our devices. These always-on services capture and transmit our audio data to powerful cloud services for further processing and subsequent actions. Our voices and raw audio signals collected through these devices contain a host of sensitive paralinguistic information that is transmitted to service providers regardless of deliberate or false triggers. As sensitive attributes like our identity, gender, indicators of mental health status, alongside moods, emotions and their temporal patterns, are easily inferred using deep acoustic models, we encounter a new generation of privacy risks by using these services. One approach to mitigate the risk of paralinguistic-based privacy breaches is to exploit a combination of cloud-based processing with privacy-preserving on-device paralinguistic information filtering prior to transmitting voice data. In this paper we introduce EDGY, a new lightweight disentangled representation learning model that transforms and filters high-dimensional voice data to remove sensitive attributes at the edge prior to offloading to the cloud. We evaluate EDGY's on-device performance, and explore optimization techniques, including model pruning and quantization, to enable private, accurate and efficient representation learning on resource-constrained devices. Our experimental results show that EDGY runs in tens of milliseconds with minimal performance penalties or accuracy losses in speech recognition using only a CPU and a single core ARM device without specialized hardware.
Emotionless: Privacy-Preserving Speech Analysis for Voice Assistants
Aug 09, 2019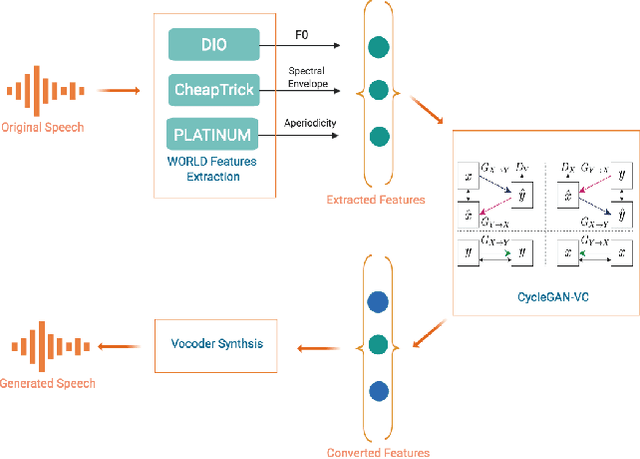
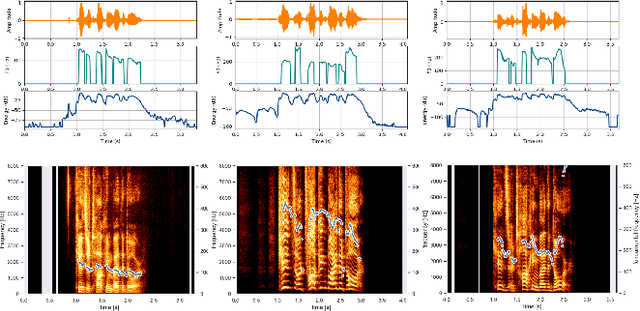
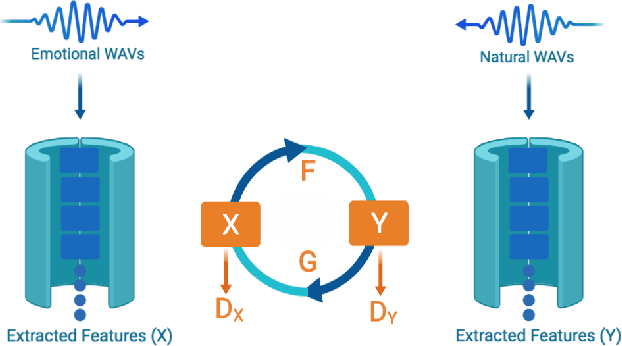
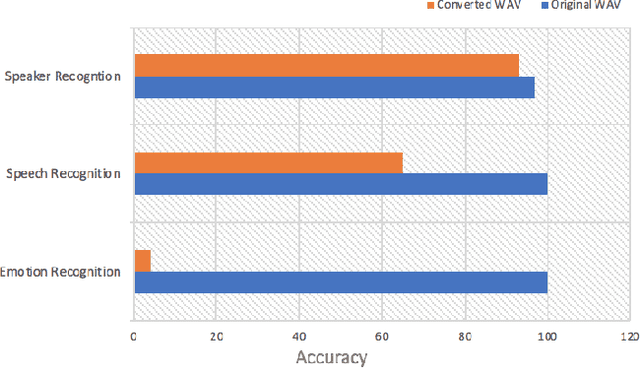
Voice-enabled interactions provide more human-like experiences in many popular IoT systems. Cloud-based speech analysis services extract useful information from voice input using speech recognition techniques. The voice signal is a rich resource that discloses several possible states of a speaker, such as emotional state, confidence and stress levels, physical condition, age, gender, and personal traits. Service providers can build a very accurate profile of a user's demographic category, personal preferences, and may compromise privacy. To address this problem, a privacy-preserving intermediate layer between users and cloud services is proposed to sanitize the voice input. It aims to maintain utility while preserving user privacy. It achieves this by collecting real time speech data and analyzes the signal to ensure privacy protection prior to sharing of this data with services providers. Precisely, the sensitive representations are extracted from the raw signal by using transformation functions and then wrapped it via voice conversion technology. Experimental evaluation based on emotion recognition to assess the efficacy of the proposed method shows that identification of sensitive emotional state of the speaker is reduced by ~96 %.