 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointArena: Probing Multimodal Grounding Through Language-Guided Pointing
May 15, 2025Pointing serves as a fundamental and intuitive mechanism for grounding language within visual contexts, with applications spanning robotics, assistive technologies, and interactive AI systems. While recent multimodal models have started to support pointing capabilities, existing benchmarks typically focus only on referential object localization tasks. We introduce PointArena, a comprehensive platform for evaluating multimodal pointing across diverse reasoning scenarios. PointArena comprises three components: (1) Point-Bench, a curated dataset containing approximately 1,000 pointing tasks across five reasoning categories; (2) Point-Battle, an interactive, web-based arena facilitating blind, pairwise model comparisons, which has already gathered over 4,500 anonymized votes; and (3) Point-Act, a real-world robotic manipulation system allowing users to directly evaluate multimodal model pointing capabilities in practical settings. We conducted extensive evaluations of both state-of-the-art open-source and proprietary multimodal models. Results indicate that Molmo-72B consistently outperforms other models, though proprietary models increasingly demonstrate comparable performance. Additionally, we find that supervised training specifically targeting pointing tasks significantly enhances model performance. Across our multi-stage evaluation pipeline, we also observe strong correlations, underscoring the critical role of precise pointing capabilities in enabling multimodal models to effectively bridge abstract reasoning with concrete, real-world actions. Project page: https://pointarena.github.io/
Benchmarking Ultra-Low-Power $μ$NPUs
Mar 28, 2025
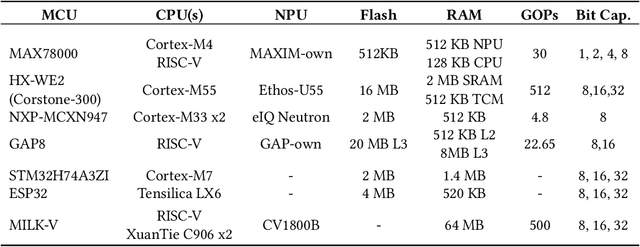


Efficient on-device neural network (NN) inference has various advantages over cloud-based processing, including predictable latency, enhanced privacy, greater reliability, and reduced operating costs for vendors. This has sparked the recent rapid development of microcontroller-scale NN accelerators, often referred to as neural processing units ($\mu$NPUs), designed specifically for ultra-low-power applications. In this paper we present the first comparative evaluation of a number of commercially-available $\mu$NPUs, as well as the first independent benchmarks for several of these platforms. We develop and open-source a model compilation framework to enable consistent benchmarking of quantized models across diverse $\mu$NPU hardware. Our benchmark targets end-to-end performance and includes model inference latency, power consumption, and memory overhead, alongside other factors. The resulting analysis uncovers both expected performance trends as well as surprising disparities between hardware specifications and actual performance, including $\mu$NPUs exhibiting unexpected scaling behaviors with increasing model complexity. Our framework provides a foundation for further evaluation of $\mu$NPU platforms alongside valuable insights for both hardware designers and software developers in this rapidly evolving space.
Towards Low-Energy Adaptive Personalization for Resource-Constrained Devices
Mar 29, 2024The personalization of machine learning (ML) models to address data drift is a significant challenge in the context of Internet of Things (IoT) applications. Presently, most approaches focus on fine-tuning either the full base model or its last few layers to adapt to new data, while often neglecting energy costs. However, various types of data drift exist, and fine-tuning the full base model or the last few layers may not result in optimal performance in certain scenarios. We propose Target Block Fine-Tuning (TBFT), a low-energy adaptive personalization framework designed for resource-constrained devices. We categorize data drift and personalization into three types: input-level, feature-level, and output-level. For each type, we fine-tune different blocks of the model to achieve optimal performance with reduced energy costs. Specifically, input-, feature-, and output-level correspond to fine-tuning the front, middle, and rear blocks of the model. We evaluate TBFT on a ResNet model, three datasets, three different training sizes, and a Raspberry Pi. Compared with the $Block Avg$, where each block is fine-tuned individually and their performance improvements are averaged, TBFT exhibits an improvement in model accuracy by an average of 15.30% whilst saving 41.57% energy consumption on average compared with full fine-tuning.
MicroT: Low-Energy and Adaptive Models for MCUs
Mar 12, 2024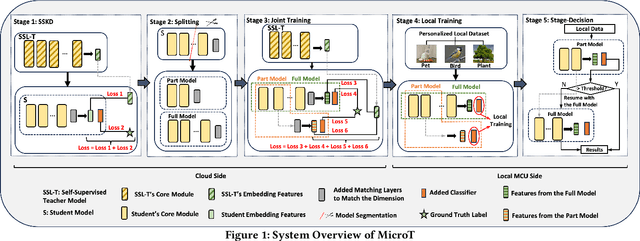


We propose MicroT, a low-energy, multi-task adaptive model framework for resource-constrained MCUs. We divide the original model into a feature extractor and a classifier. The feature extractor is obtained through self-supervised knowledge distillation and further optimized into part and full models through model splitting and joint training. These models are then deployed on MCUs, with classifiers added and trained on local tasks, ultimately performing stage-decision for joint inference. In this process, the part model initially processes the sample, and if the confidence score falls below the set threshold, the full model will resume and continue the inference. We evaluate MicroT on two models, three datasets, and two MCU boards. Our experimental evaluation shows that MicroT effectively improves model performance and reduces energy consumption when dealing with multiple local tasks. Compared to the unoptimized feature extractor, MicroT can improve accuracy by up to 9.87%. On MCUs, compared to the standard full model inference, MicroT can save up to about 29.13% in energy consumption. MicroT also allows users to adaptively adjust the stage-decision ratio as needed, better balancing model performance and energy consumption. Under the standard stage-decision ratio configuration, MicroT can increase accuracy by 5.91% and save about 14.47% of energy consumption.
Towards Machine Learning and Inference for Resource-constrained MCUs
May 30, 2023


Machine learning (ML) is moving towards edge devices. However, ML models with high computational demands and energy consumption pose challenges for ML inference in resource-constrained environments, such as the deep sea. To address these challenges, we propose a battery-free ML inference and model personalization pipeline for microcontroller units (MCUs). As an example, we performed fish image recognition in the ocean. We evaluated and compared the accuracy, runtime, power, and energy consumption of the model before and after optimization. The results demonstrate that, our pipeline can achieve 97.78% accuracy with 483.82 KB Flash, 70.32 KB RAM, 118 ms runtime, 4.83 mW power, and 0.57 mJ energy consumption on MCUs, reducing by 64.17%, 12.31%, 52.42%, 63.74%, and 82.67%, compared to the baseline. The results indicate the feasibility of battery-free ML inference on MCUs.
Information Theory Inspired Pattern Analysis for Time-series Data
Feb 22, 2023



Current methods for pattern analysis in time series mainly rely on statistical features or probabilistic learning and inference methods to identify patterns and trends in the data. Such methods do not generalize well when applied to multivariate, multi-source, state-varying, and noisy time-series data. To address these issues, we propose a highly generalizable method that uses information theory-based features to identify and learn from patterns in multivariate time-series data. To demonstrate the proposed approach, we analyze pattern changes in human activity data. For applications with stochastic state transitions, features are developed based on Shannon's entropy of Markov chains, entropy rates of Markov chains, entropy production of Markov chains, and von Neumann entropy of Markov chains. For applications where state modeling is not applicable, we utilize five entropy variants, including approximate entropy, increment entropy, dispersion entropy, phase entropy, and slope entropy. The results show the proposed information theory-based features improve the recall rate, F1 score, and accuracy on average by up to 23.01\% compared with the baseline models and a simpler model structure, with an average reduction of 18.75 times in the number of model parameters.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022

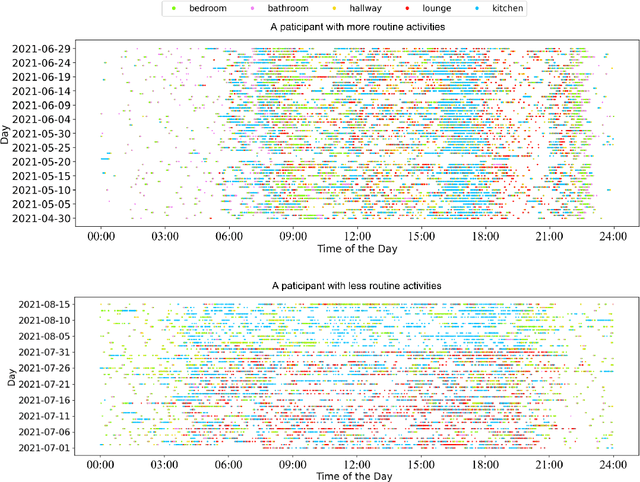

In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.