 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Ultra-Low-Power $μ$NPUs
Paper and Code
Mar 28, 2025
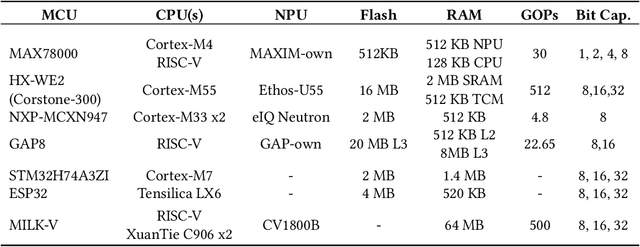


Efficient on-device neural network (NN) inference has various advantages over cloud-based processing, including predictable latency, enhanced privacy, greater reliability, and reduced operating costs for vendors. This has sparked the recent rapid development of microcontroller-scale NN accelerators, often referred to as neural processing units ($\mu$NPUs), designed specifically for ultra-low-power applications. In this paper we present the first comparative evaluation of a number of commercially-available $\mu$NPUs, as well as the first independent benchmarks for several of these platforms. We develop and open-source a model compilation framework to enable consistent benchmarking of quantized models across diverse $\mu$NPU hardware. Our benchmark targets end-to-end performance and includes model inference latency, power consumption, and memory overhead, alongside other factors. The resulting analysis uncovers both expected performance trends as well as surprising disparities between hardware specifications and actual performance, including $\mu$NPUs exhibiting unexpected scaling behaviors with increasing model complexity. Our framework provides a foundation for further evaluation of $\mu$NPU platforms alongside valuable insights for both hardware designers and software developers in this rapidly evolving space.