 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Fine-Tuning for Targeted and Robust Concept Unlearning
Feb 08, 2026Text guided diffusion models are used by millions of users, but can be easily exploited to produce harmful content. Concept unlearning methods aim at reducing the models' likelihood of generating harmful content. Traditionally, this has been tackled at an individual concept level, with only a handful of recent works considering more realistic concept combinations. However, state of the art methods depend on full finetuning, which is computationally expensive. Concept localisation methods can facilitate selective finetuning, but existing techniques are static, resulting in suboptimal utility. In order to tackle these challenges, we propose TRUST (Targeted Robust Selective fine Tuning), a novel approach for dynamically estimating target concept neurons and unlearning them through selective finetuning, empowered by a Hessian based regularization. We show experimentally, against a number of SOTA baselines, that TRUST is robust against adversarial prompts, preserves generation quality to a significant degree, and is also significantly faster than the SOTA. Our method achieves unlearning of not only individual concepts but also combinations of concepts and conditional concepts, without any specific regularization.
DiDOTS: Knowledge Distillation from Large-Language-Models for Dementia Obfuscation in Transcribed Speech
Oct 05, 2024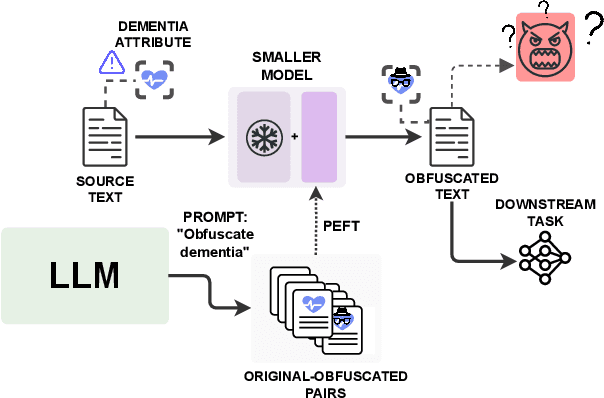
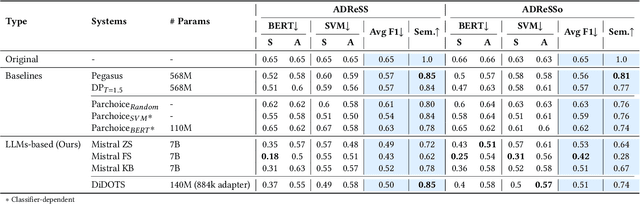

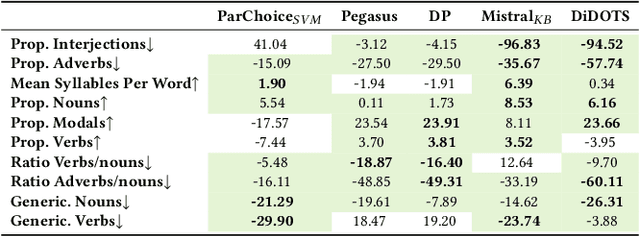
Dementia is a sensitive neurocognitive disorder affecting tens of millions of people worldwide and its cases are expected to triple by 2050. Alarmingly, recent advancements in dementia classification make it possible for adversaries to violate affected individuals' privacy and infer their sensitive condition from speech transcriptions. Existing obfuscation methods in text have never been applied for dementia and depend on the availability of large labeled datasets which are challenging to collect for sensitive medical attributes. In this work, we bridge this research gap and tackle the above issues by leveraging Large-Language-Models (LLMs) with diverse prompt designs (zero-shot, few-shot, and knowledge-based) to obfuscate dementia in speech transcripts. Our evaluation shows that LLMs are more effective dementia obfuscators compared to competing methods. However, they have billions of parameters which renders them hard to train, store and share, and they are also fragile suffering from hallucination, refusal and contradiction effects among others. To further mitigate these, we propose a novel method, DiDOTS. DiDOTS distills knowledge from LLMs using a teacher-student paradigm and parameter-efficient fine-tuning. DiDOTS has one order of magnitude fewer parameters compared to its teacher LLM and can be fine-tuned using three orders of magnitude less parameters compared to full fine-tuning. Our evaluation shows that compared to prior work DiDOTS retains the performance of LLMs achieving 1.3x and 2.2x improvement in privacy performance on two datasets, while humans rate it as better in preserving utility even when compared to state-of-the-art paraphrasing models.
Prosody-Driven Privacy-Preserving Dementia Detection
Jul 03, 2024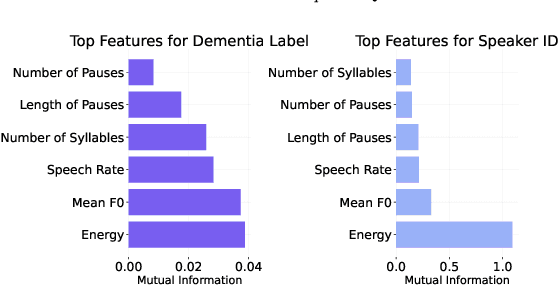
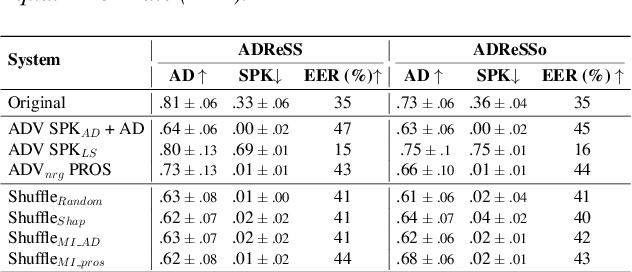
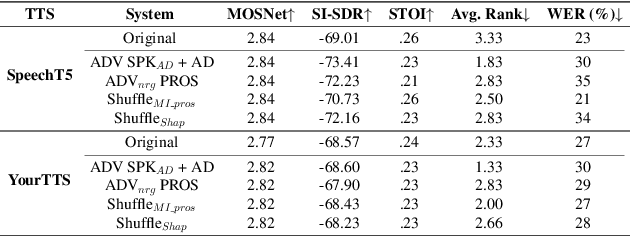
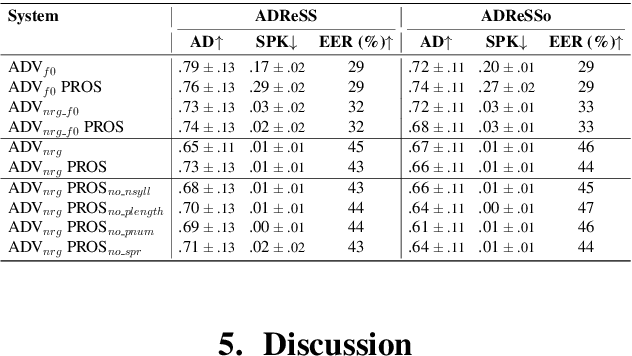
Speaker embeddings extracted from voice recordings have been proven valuable for dementia detection. However, by their nature, these embeddings contain identifiable information which raises privacy concerns. In this work, we aim to anonymize embeddings while preserving the diagnostic utility for dementia detection. Previous studies rely on adversarial learning and models trained on the target attribute and struggle in limited-resource settings. We propose a novel approach that leverages domain knowledge to disentangle prosody features relevant to dementia from speaker embeddings without relying on a dementia classifier. Our experiments show the effectiveness of our approach in preserving speaker privacy (speaker recognition F1-score .01%) while maintaining high dementia detection score F1-score of 74% on the ADReSS dataset. Our results are also on par with a more constrained classifier-dependent system on ADReSSo (.01% and .66%), and have no impact on synthesized speech naturalness.
Adversarial 3D Virtual Patches using Integrated Gradients
Jun 01, 2024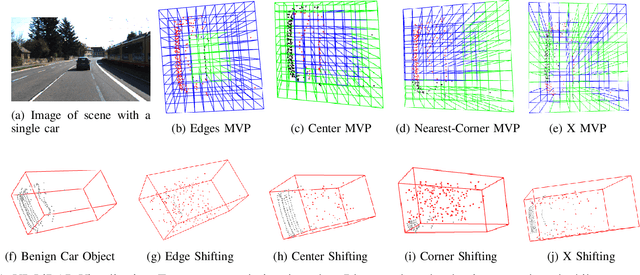
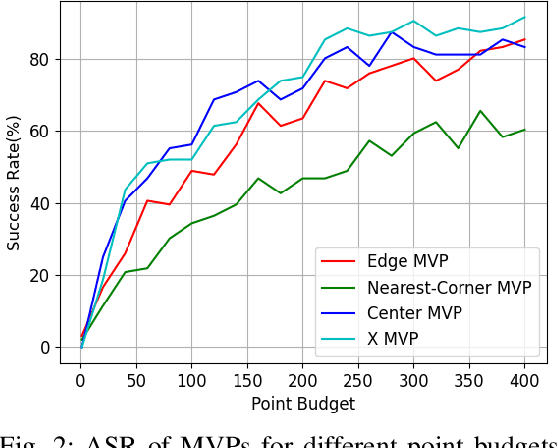
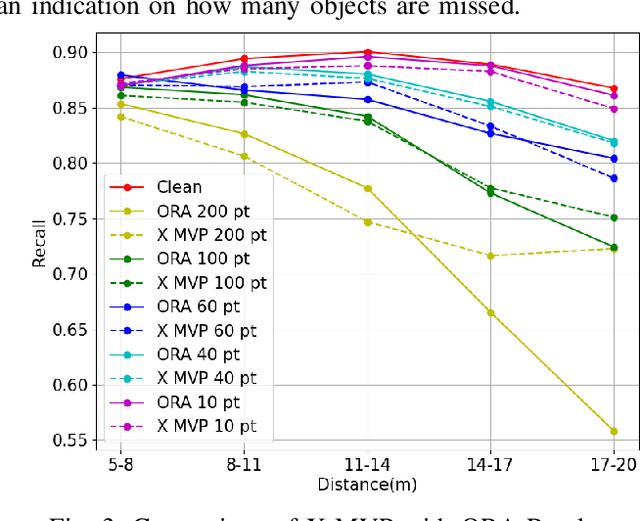
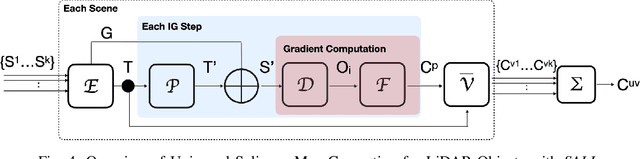
LiDAR sensors are widely used in autonomous vehicles to better perceive the environment. However, prior works have shown that LiDAR signals can be spoofed to hide real objects from 3D object detectors. This study explores the feasibility of reducing the required spoofing area through a novel object-hiding strategy based on virtual patches (VPs). We first manually design VPs (MVPs) and show that VP-focused attacks can achieve similar success rates with prior work but with a fraction of the required spoofing area. Then we design a framework Saliency-LiDAR (SALL), which can identify critical regions for LiDAR objects using Integrated Gradients. VPs crafted on critical regions (CVPs) reduce object detection recall by at least 15% compared to our baseline with an approximate 50% reduction in the spoofing area for vehicles of average size.
Data Augmentation for Dementia Detection in Spoken Language
Jun 26, 2022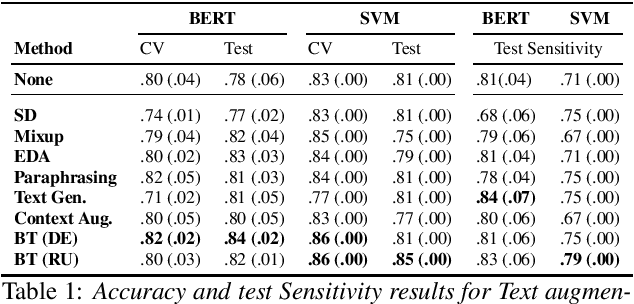
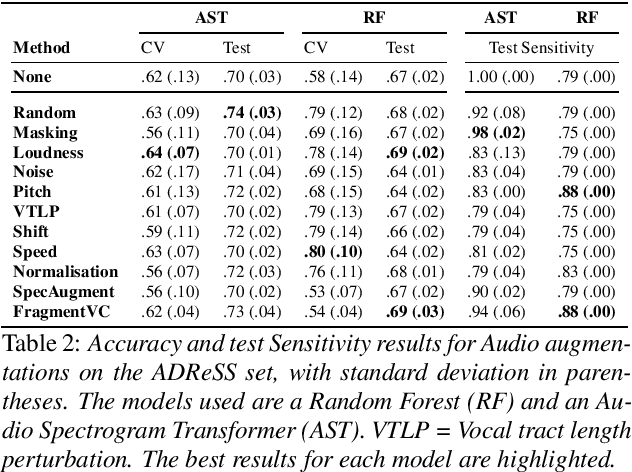

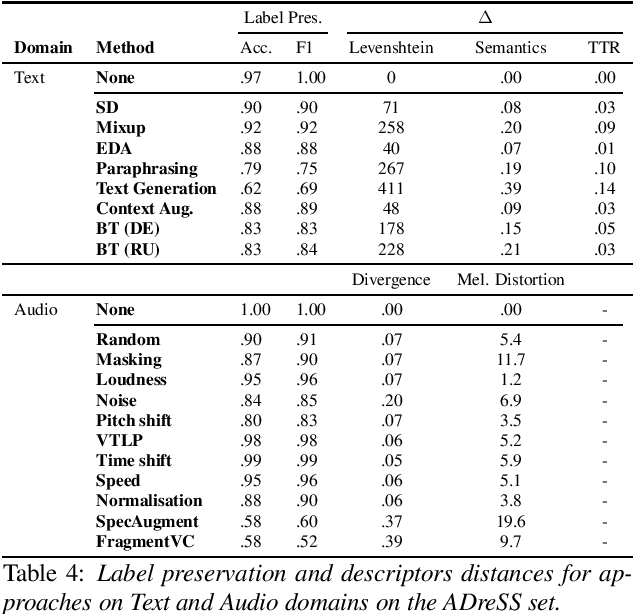
Dementia is a growing problem as our society ages, and detection methods are often invasive and expensive. Recent deep-learning techniques can offer a faster diagnosis and have shown promising results. However, they require large amounts of labelled data which is not easily available for the task of dementia detection. One effective solution to sparse data problems is data augmentation, though the exact methods need to be selected carefully. To date, there has been no empirical study of data augmentation on Alzheimer's disease (AD) datasets for NLP and speech processing. In this work, we investigate data augmentation techniques for the task of AD detection and perform an empirical evaluation of the different approaches on two kinds of models for both the text and audio domains. We use a transformer-based model for both domains, and SVM and Random Forest models for the text and audio domains, respectively. We generate additional samples using traditional as well as deep learning based methods and show that data augmentation improves performance for both the text- and audio-based models and that such results are comparable to state-of-the-art results on the popular ADReSS set, with carefully crafted architectures and features.
Using 3D Shadows to Detect Object Hiding Attacks on Autonomous Vehicle Perception
Apr 29, 2022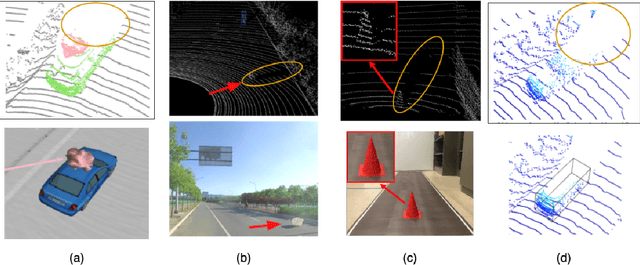

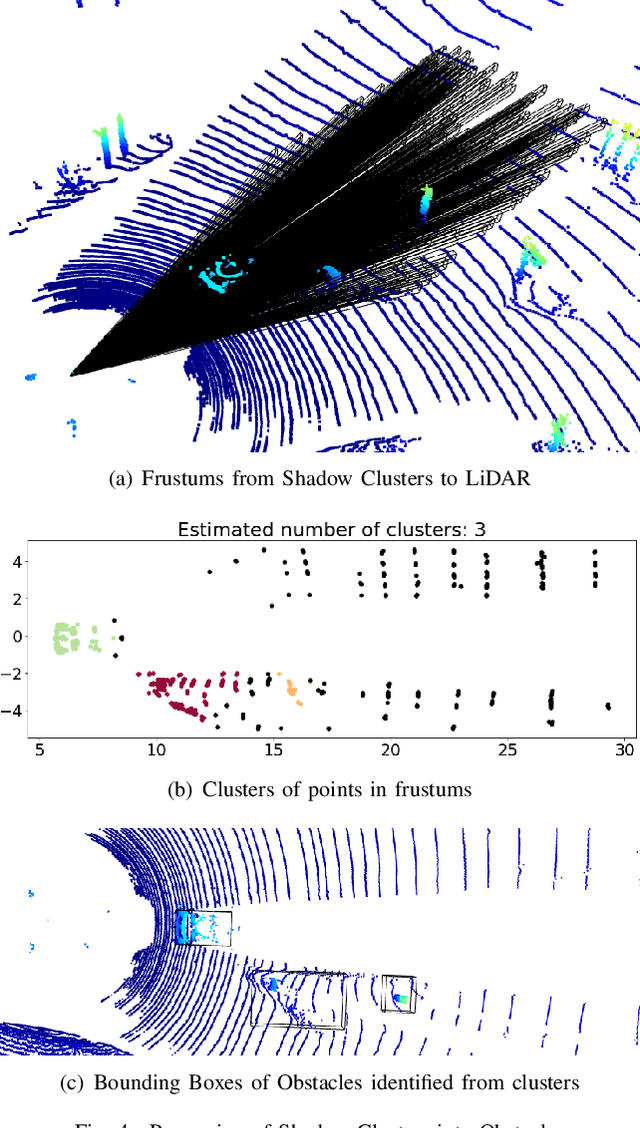
Autonomous Vehicles (AVs) are mostly reliant on LiDAR sensors which enable spatial perception of their surroundings and help make driving decisions. Recent works demonstrated attacks that aim to hide objects from AV perception, which can result in severe consequences. 3D shadows, are regions void of measurements in 3D point clouds which arise from occlusions of objects in a scene. 3D shadows were proposed as a physical invariant valuable for detecting spoofed or fake objects. In this work, we leverage 3D shadows to locate obstacles that are hidden from object detectors. We achieve this by searching for void regions and locating the obstacles that cause these shadows. Our proposed methodology can be used to detect an object that has been hidden by an adversary as these objects, while hidden from 3D object detectors, still induce shadow artifacts in 3D point clouds, which we use for obstacle detection. We show that using 3D shadows for obstacle detection can achieve high accuracy in matching shadows to their object and provide precise prediction of an obstacle's distance from the ego-vehicle.
Temporal Consistency Checks to Detect LiDAR Spoofing Attacks on Autonomous Vehicle Perception
Jun 15, 2021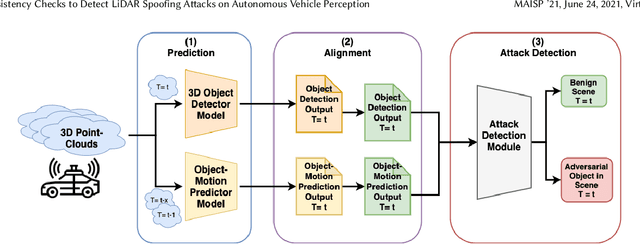

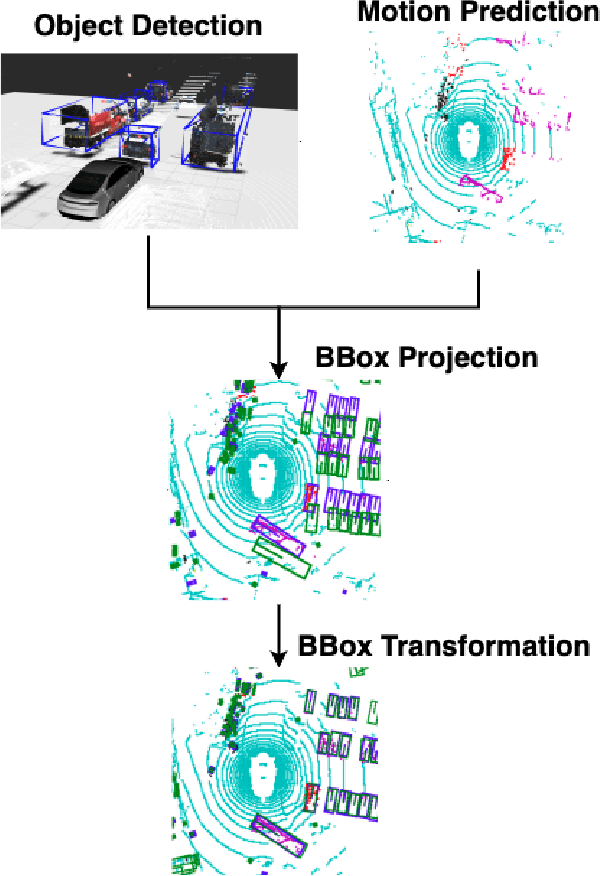
LiDAR sensors are used widely in Autonomous Vehicles for better perceiving the environment which enables safer driving decisions. Recent work has demonstrated serious LiDAR spoofing attacks with alarming consequences. In particular, model-level LiDAR spoofing attacks aim to inject fake depth measurements to elicit ghost objects that are erroneously detected by 3D Object Detectors, resulting in hazardous driving decisions. In this work, we explore the use of motion as a physical invariant of genuine objects for detecting such attacks. Based on this, we propose a general methodology, 3D Temporal Consistency Check (3D-TC2), which leverages spatio-temporal information from motion prediction to verify objects detected by 3D Object Detectors. Our preliminary design and implementation of a 3D-TC2 prototype demonstrates very promising performance, providing more than 98% attack detection rate with a recall of 91% for detecting spoofed Vehicle (Car) objects, and is able to achieve real-time detection at 41Hz
Quantifying Information Leakage from Gradients
May 28, 2021
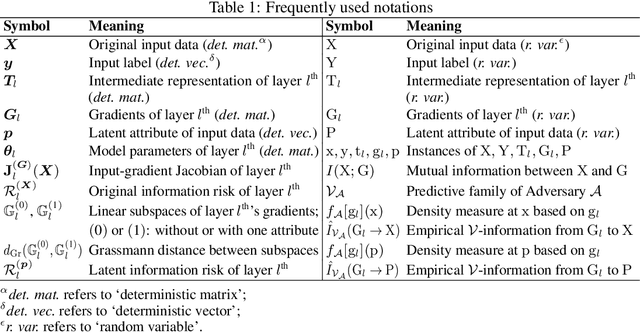
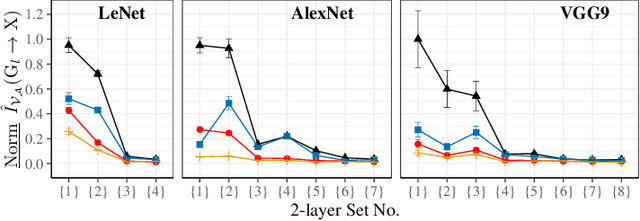

Sharing deep neural networks' gradients instead of training data could facilitate data privacy in collaborative learning. In practice however, gradients can disclose both private latent attributes and original data. Mathematical metrics are needed to quantify both original and latent information leakages from gradients computed over the training data. In this work, we first use an adaptation of the empirical $\mathcal{V}$-information to present an information-theoretic justification for the attack success rates in a layer-wise manner. We then move towards a deeper understanding of gradient leakages and propose more general and efficient metrics, using sensitivity and subspace distance to quantify the gradient changes w.r.t. original and latent information, respectively. Our empirical results, on six datasets and four models, reveal that gradients of the first layers contain the highest amount of original information, while the classifier/fully-connected layers placed after the feature extractor contain the highest latent information. Further, we show how training hyperparameters such as gradient aggregation can decrease information leakages. Our characterization provides a new understanding on gradient-based information leakages using the gradients' sensitivity w.r.t. changes in private information, and portends possible defenses such as layer-based protection or strong aggregation.
Object Removal Attacks on LiDAR-based 3D Object Detectors
Feb 07, 2021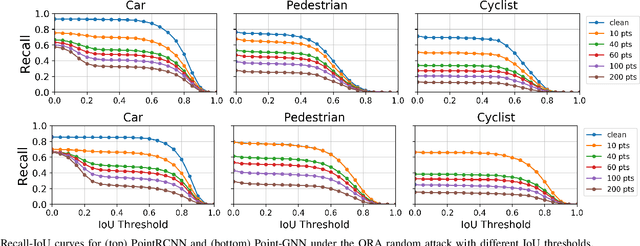
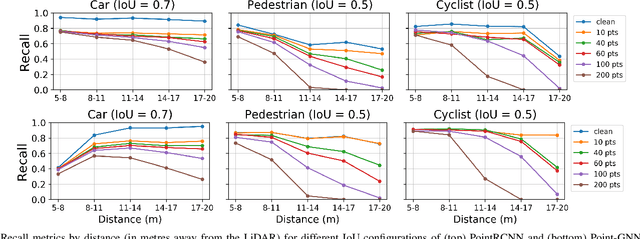
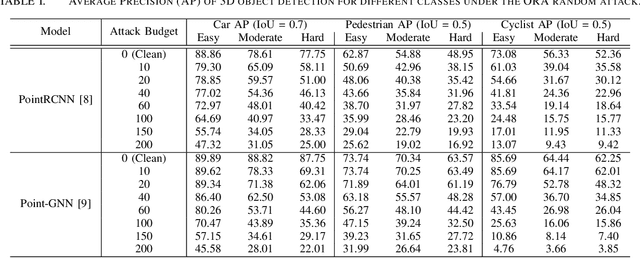
LiDARs play a critical role in Autonomous Vehicles' (AVs) perception and their safe operations. Recent works have demonstrated that it is possible to spoof LiDAR return signals to elicit fake objects. In this work we demonstrate how the same physical capabilities can be used to mount a new, even more dangerous class of attacks, namely Object Removal Attacks (ORAs). ORAs aim to force 3D object detectors to fail. We leverage the default setting of LiDARs that record a single return signal per direction to perturb point clouds in the region of interest (RoI) of 3D objects. By injecting illegitimate points behind the target object, we effectively shift points away from the target objects' RoIs. Our initial results using a simple random point selection strategy show that the attack is effective in degrading the performance of commonly used 3D object detection models.
Layer-wise Characterization of Latent Information Leakage in Federated Learning
Oct 17, 2020

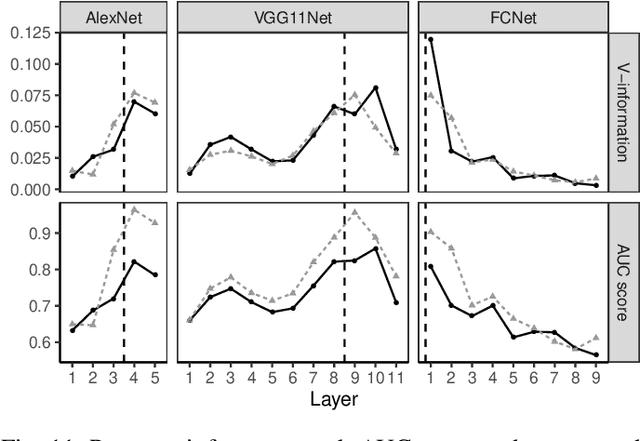
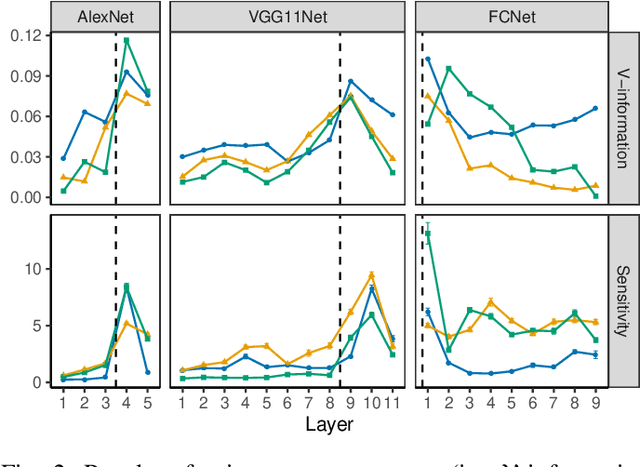
Training a deep neural network (DNN) via federated learning allows participants to share model updates (gradients), instead of the data itself. However, recent studies show that unintended latent information (e.g. gender or race) carried by the gradients can be discovered by attackers, compromising the promised privacy guarantee of federated learning. Existing privacy-preserving techniques (e.g. differential privacy) either have limited defensive capacity against the potential attacks, or suffer from considerable model utility loss. Moreover, characterizing the latent information carried by the gradients and the consequent privacy leakage has been a major theoretical and practical challenge. In this paper, we propose two new metrics to address these challenges: the empirical $\mathcal{V}$-information, a theoretically grounded notion of information which measures the amount of gradient information that is usable for an attacker, and the sensitivity analysis that utilizes the Jacobian matrix to measure the amount of changes in the gradients with respect to latent information which further quantifies private risk. We show that these metrics can localize the private information in each layer of a DNN and quantify the leakage depending on how sensitive the gradients are with respect to the latent information. As a practical application, we design LatenTZ: a federated learning framework that lets the most sensitive layers to run in the clients' Trusted Execution Environments (TEE). The implementation evaluation of LatenTZ shows that TEE-based approaches are promising for defending against powerful property inference attacks without a significant overhead in the clients' computing resources nor trading off the model's utility.