 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJacobian Ensembles Improve Robustness Trade-offs to Adversarial Attacks
Apr 19, 2022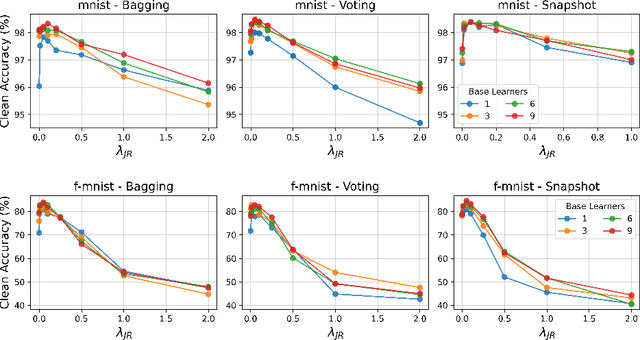

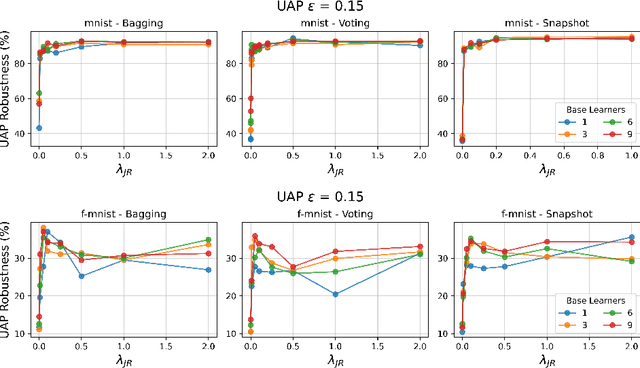

Deep neural networks have become an integral part of our software infrastructure and are being deployed in many widely-used and safety-critical applications. However, their integration into many systems also brings with it the vulnerability to test time attacks in the form of Universal Adversarial Perturbations (UAPs). UAPs are a class of perturbations that when applied to any input causes model misclassification. Although there is an ongoing effort to defend models against these adversarial attacks, it is often difficult to reconcile the trade-offs in model accuracy and robustness to adversarial attacks. Jacobian regularization has been shown to improve the robustness of models against UAPs, whilst model ensembles have been widely adopted to improve both predictive performance and model robustness. In this work, we propose a novel approach, Jacobian Ensembles-a combination of Jacobian regularization and model ensembles to significantly increase the robustness against UAPs whilst maintaining or improving model accuracy. Our results show that Jacobian Ensembles achieves previously unseen levels of accuracy and robustness, greatly improving over previous methods that tend to skew towards only either accuracy or robustness.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

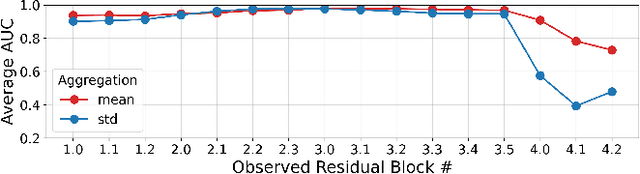
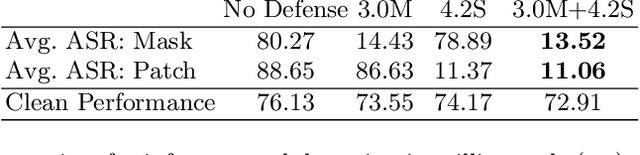
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Jacobian Regularization for Mitigating Universal Adversarial Perturbations
Apr 21, 2021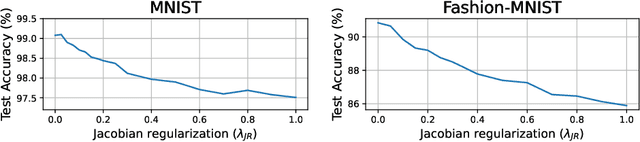
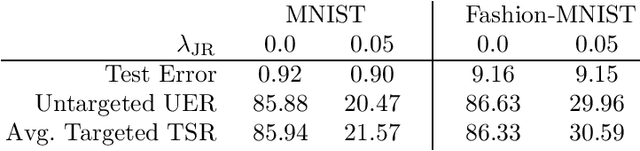
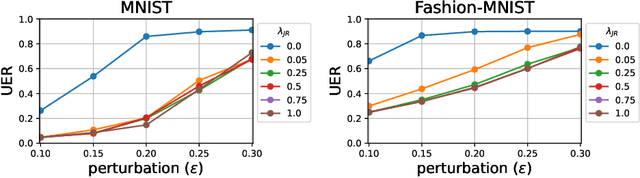
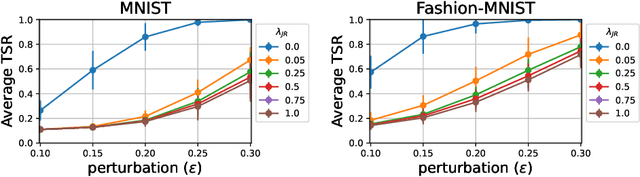
Universal Adversarial Perturbations (UAPs) are input perturbations that can fool a neural network on large sets of data. They are a class of attacks that represents a significant threat as they facilitate realistic, practical, and low-cost attacks on neural networks. In this work, we derive upper bounds for the effectiveness of UAPs based on norms of data-dependent Jacobians. We empirically verify that Jacobian regularization greatly increases model robustness to UAPs by up to four times whilst maintaining clean performance. Our theoretical analysis also allows us to formulate a metric for the strength of shared adversarial perturbations between pairs of inputs. We apply this metric to benchmark datasets and show that it is highly correlated with the actual observed robustness. This suggests that realistic and practical universal attacks can be reliably mitigated without sacrificing clean accuracy, which shows promise for the robustness of machine learning systems.
Object Removal Attacks on LiDAR-based 3D Object Detectors
Feb 07, 2021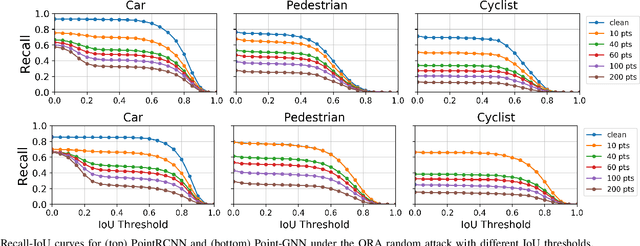
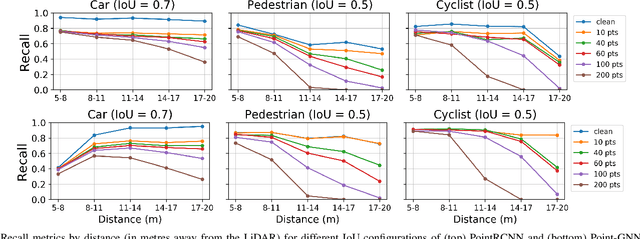
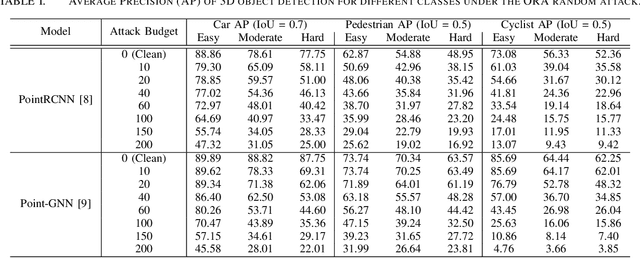
LiDARs play a critical role in Autonomous Vehicles' (AVs) perception and their safe operations. Recent works have demonstrated that it is possible to spoof LiDAR return signals to elicit fake objects. In this work we demonstrate how the same physical capabilities can be used to mount a new, even more dangerous class of attacks, namely Object Removal Attacks (ORAs). ORAs aim to force 3D object detectors to fail. We leverage the default setting of LiDARs that record a single return signal per direction to perturb point clouds in the region of interest (RoI) of 3D objects. By injecting illegitimate points behind the target object, we effectively shift points away from the target objects' RoIs. Our initial results using a simple random point selection strategy show that the attack is effective in degrading the performance of commonly used 3D object detection models.
Robustness and Transferability of Universal Attacks on Compressed Models
Dec 10, 2020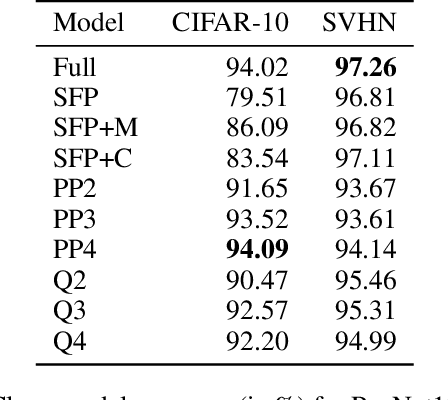
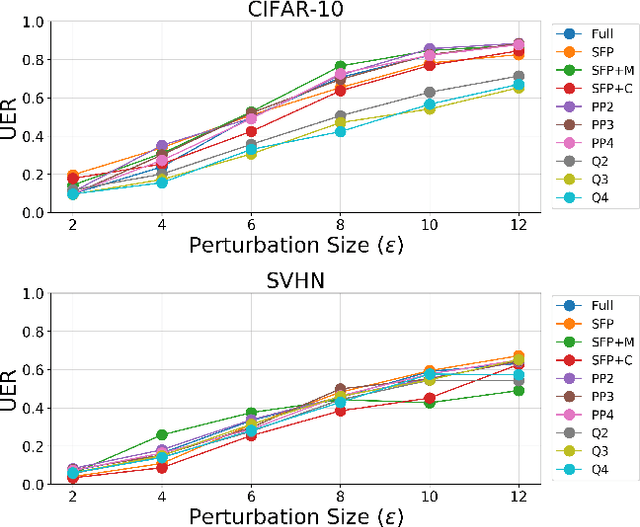

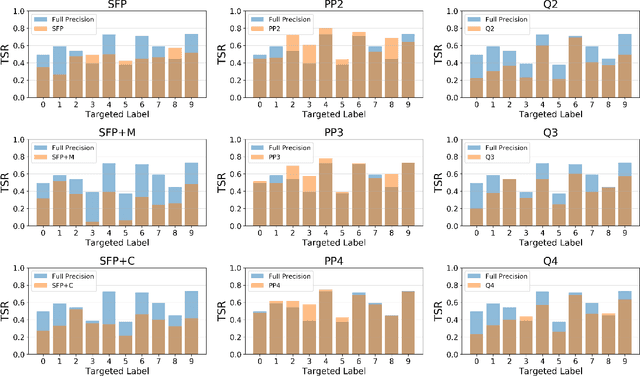
Neural network compression methods like pruning and quantization are very effective at efficiently deploying Deep Neural Networks (DNNs) on edge devices. However, DNNs remain vulnerable to adversarial examples-inconspicuous inputs that are specifically designed to fool these models. In particular, Universal Adversarial Perturbations (UAPs), are a powerful class of adversarial attacks which create adversarial perturbations that can generalize across a large set of inputs. In this work, we analyze the effect of various compression techniques to UAP attacks, including different forms of pruning and quantization. We test the robustness of compressed models to white-box and transfer attacks, comparing them with their uncompressed counterparts on CIFAR-10 and SVHN datasets. Our evaluations reveal clear differences between pruning methods, including Soft Filter and Post-training Pruning. We observe that UAP transfer attacks between pruned and full models are limited, suggesting that the systemic vulnerabilities across these models are different. This finding has practical implications as using different compression techniques can blunt the effectiveness of black-box transfer attacks. We show that, in some scenarios, quantization can produce gradient-masking, giving a false sense of security. Finally, our results suggest that conclusions about the robustness of compressed models to UAP attacks is application dependent, observing different phenomena in the two datasets used in our experiments.
Universal Adversarial Perturbations to Understand Robustness of Texture vs. Shape-biased Training
Nov 23, 2019
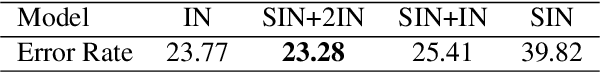
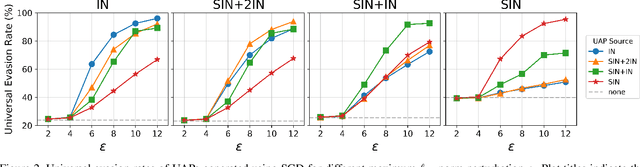
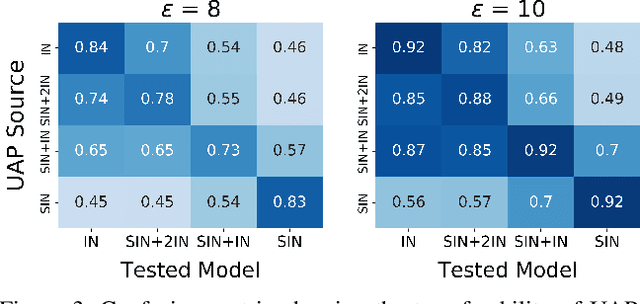
Convolutional Neural Networks (CNNs) used on image classification tasks such as ImageNet have been shown to be biased towards recognizing textures rather than shapes. Recent work has attempted to alleviate this by augmenting the training dataset with shape-based examples to create Stylized-ImageNet. However, in this paper we show that models trained on this dataset remain vulnerable to Universal Adversarial Perturbations (UAPs). We use UAPs to evaluate and compare the robustness of CNN models with varying degrees of shape-based training. We also find that a posteriori fine-tuning on ImageNet negates features learned from training on Stylized-ImageNet. This study reveals an important limitation and reiterates the need for further research into understanding the robustness of CNNs for visual recognition.
Byzantine-Robust Federated Machine Learning through Adaptive Model Averaging
Sep 11, 2019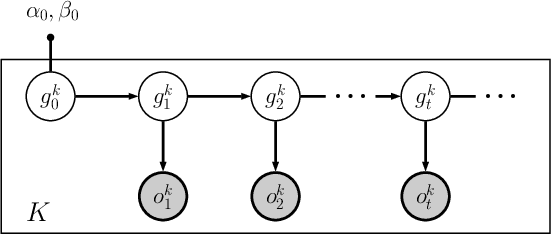
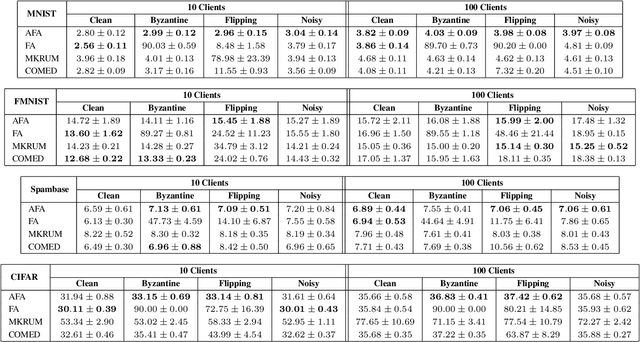

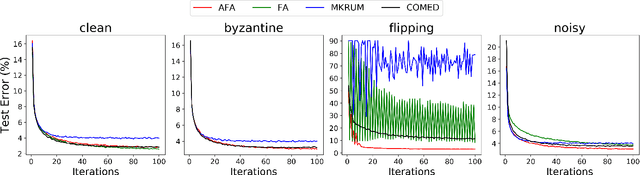
Federated learning enables training collaborative machine learning models at scale with many participants whilst preserving the privacy of their datasets. Standard federated learning techniques are vulnerable to Byzantine failures, biased local datasets, and poisoning attacks. In this paper we introduce Adaptive Federated Averaging, a novel algorithm for robust federated learning that is designed to detect failures, attacks, and bad updates provided by participants in a collaborative model. We propose a Hidden Markov Model to model and learn the quality of model updates provided by each participant during training. In contrast to existing robust federated learning schemes, we propose a robust aggregation rule that detects and discards bad or malicious local model updates at each training iteration. This includes a mechanism that blocks unwanted participants, which also increases the computational and communication efficiency. Our experimental evaluation on 4 real datasets show that our algorithm is significantly more robust to faulty, noisy and malicious participants, whilst being computationally more efficient than other state-of-the-art robust federated learning methods such as Multi-KRUM and coordinate-wise median.
Sensitivity of Deep Convolutional Networks to Gabor Noise
Jun 11, 2019

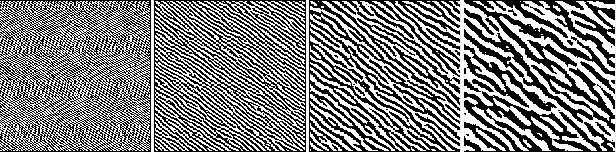

Deep Convolutional Networks (DCNs) have been shown to be sensitive to Universal Adversarial Perturbations (UAPs): input-agnostic perturbations that fool a model on large portions of a dataset. These UAPs exhibit interesting visual patterns, but this phenomena is, as yet, poorly understood. Our work shows that visually similar procedural noise patterns also act as UAPs. In particular, we demonstrate that different DCN architectures are sensitive to Gabor noise patterns. This behaviour, its causes, and implications deserve further in-depth study.
Procedural Noise Adversarial Examples for Black-Box Attacks on Deep Neural Networks
Sep 30, 2018
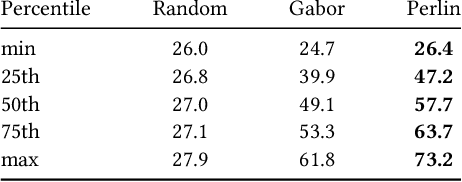

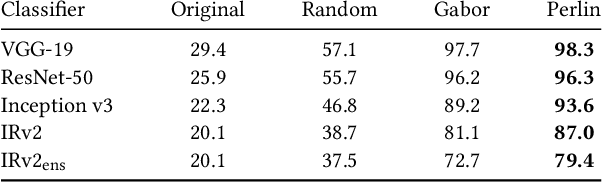
Deep neural networks have been shown to be vulnerable to adversarial examples, perturbed inputs that are designed specifically to produce intentional errors in the learning algorithms. However, existing attacks are either computationally expensive or require extensive knowledge of the target model and its dataset to succeed. Hence, these methods are not practical in a deployed adversarial setting. In this paper we introduce an exploratory approach for generating adversarial examples using procedural noise. We show that it is possible to construct practical black-box attacks with low computational cost against robust neural network architectures such as Inception v3 and Inception ResNet v2 on the ImageNet dataset. We show that these attacks successfully cause misclassification with a low number of queries, significantly outperforming state-of-the-art black box attacks. Our attack demonstrates the fragility of these neural networks to Perlin noise, a type of procedural noise used for generating realistic textures. Perlin noise attacks achieve at least 90% top 1 error across all classifiers. More worryingly, we show that most Perlin noise perturbations are "universal" in that they generalize, as adversarial examples, across large portions of the dataset, with up to 73% of images misclassified using a single perturbation. These findings suggest a systemic fragility of DNNs that needs to be explored further. We also show the limitations of adversarial training, a technique used to enhance the robustness against adversarial examples. Thus, the attacker just needs to change the perspective to generate the adversarial examples to craft successful attacks and, for the defender, it is difficult to foresee a priori all possible types of adversarial perturbations.