 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Poisoning Attacks Bypass Defenses in Regression Settings
Jan 29, 2026Regression models are widely used in industrial processes, engineering and in natural and physical sciences, yet their robustness to poisoning has received less attention. When it has, studies often assume unrealistic threat models and are thus less useful in practice. In this paper, we propose a novel optimal stealthy attack formulation that considers different degrees of detectability and show that it bypasses state-of-the-art defenses. We further propose a new methodology based on normalization of objectives to evaluate different trade-offs between effectiveness and detectability. Finally, we develop a novel defense (BayesClean) against stealthy attacks. BayesClean improves on previous defenses when attacks are stealthy and the number of poisoning points is significant.
Nonideality-aware training makes memristive networks more robust to adversarial attacks
Sep 29, 2024Neural networks are now deployed in a wide number of areas from object classification to natural language systems. Implementations using analog devices like memristors promise better power efficiency, potentially bringing these applications to a greater number of environments. However, such systems suffer from more frequent device faults and overall, their exposure to adversarial attacks has not been studied extensively. In this work, we investigate how nonideality-aware training - a common technique to deal with physical nonidealities - affects adversarial robustness. We find that adversarial robustness is significantly improved, even with limited knowledge of what nonidealities will be encountered during test time.
Hyperparameter Learning under Data Poisoning: Analysis of the Influence of Regularization via Multiobjective Bilevel Optimization
Jun 02, 2023Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to deliberately degrade the algorithms' performance. Optimal attacks can be formulated as bilevel optimization problems and help to assess their robustness in worst-case scenarios. We show that current approaches, which typically assume that hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters and models the attack as a multiobjective bilevel optimization problem. This allows to formulate optimal attacks, learn hyperparameters and evaluate robustness under worst-case conditions. We apply this attack formulation to several ML classifiers using $L_2$ and $L_1$ regularization. Our evaluation on multiple datasets confirms the limitations of previous strategies and evidences the benefits of using $L_2$ and $L_1$ regularization to dampen the effect of poisoning attacks.
FedRAD: Federated Robust Adaptive Distillation
Dec 02, 2021
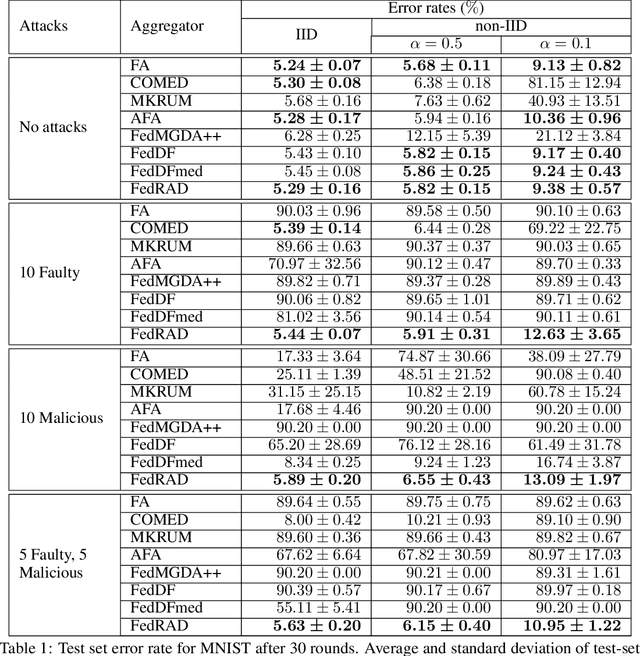
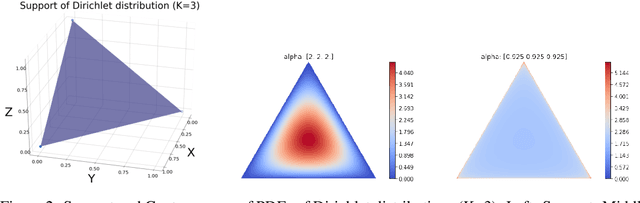
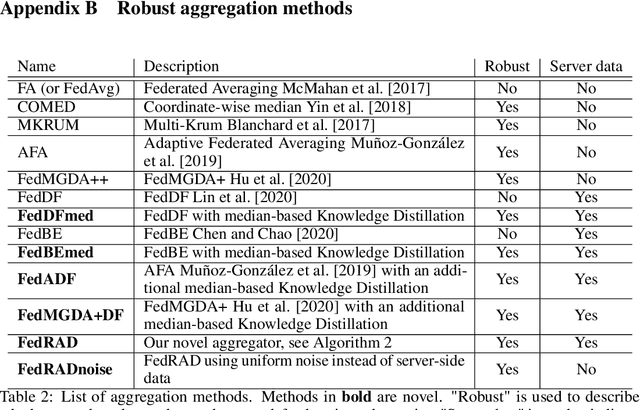
The robustness of federated learning (FL) is vital for the distributed training of an accurate global model that is shared among large number of clients. The collaborative learning framework by typically aggregating model updates is vulnerable to model poisoning attacks from adversarial clients. Since the shared information between the global server and participants are only limited to model parameters, it is challenging to detect bad model updates. Moreover, real-world datasets are usually heterogeneous and not independent and identically distributed (Non-IID) among participants, which makes the design of such robust FL pipeline more difficult. In this work, we propose a novel robust aggregation method, Federated Robust Adaptive Distillation (FedRAD), to detect adversaries and robustly aggregate local models based on properties of the median statistic, and then performing an adapted version of ensemble Knowledge Distillation. We run extensive experiments to evaluate the proposed method against recently published works. The results show that FedRAD outperforms all other aggregators in the presence of adversaries, as well as in heterogeneous data distributions.
Regularization Can Help Mitigate Poisoning Attacks... with the Right Hyperparameters
May 23, 2021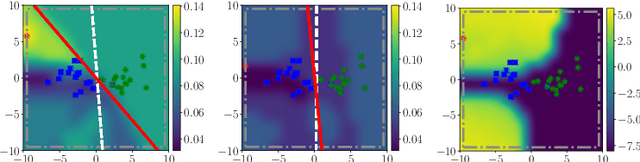

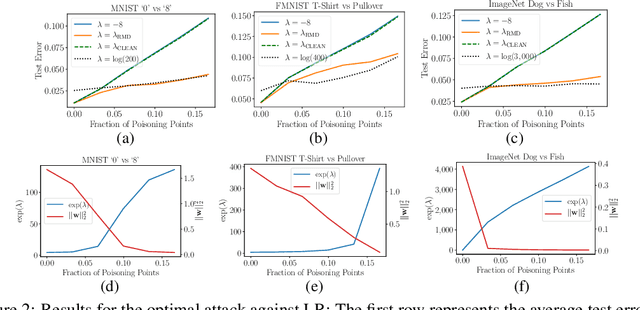
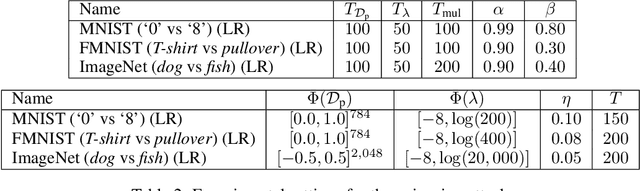
Machine learning algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to degrade the algorithms' performance. We show that current approaches, which typically assume that regularization hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters, modelling the attack as a \emph{minimax bilevel optimization problem}. This allows to formulate optimal attacks, select hyperparameters and evaluate robustness under worst case conditions. We apply this formulation to logistic regression using $L_2$ regularization, empirically show the limitations of previous strategies and evidence the benefits of using $L_2$ regularization to dampen the effect of poisoning attacks.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

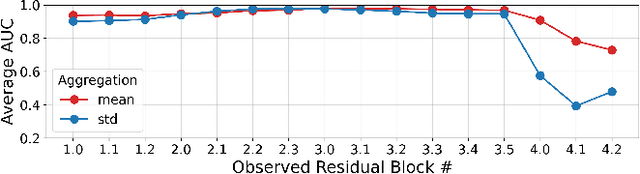
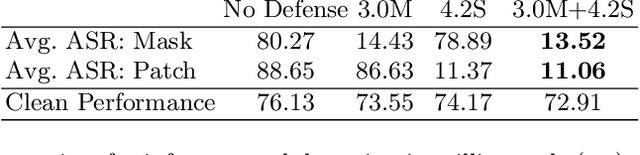
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Universal Adversarial Perturbations for Malware
Feb 12, 2021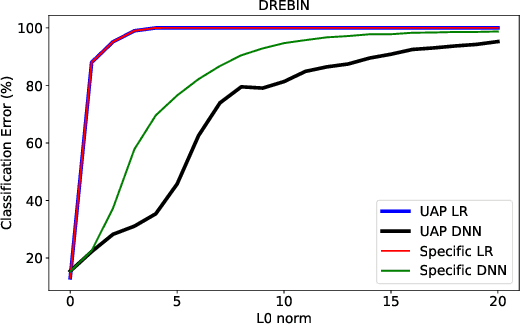

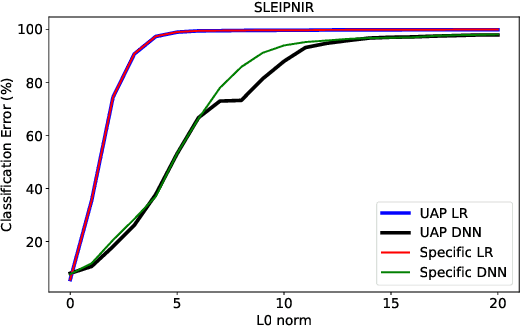
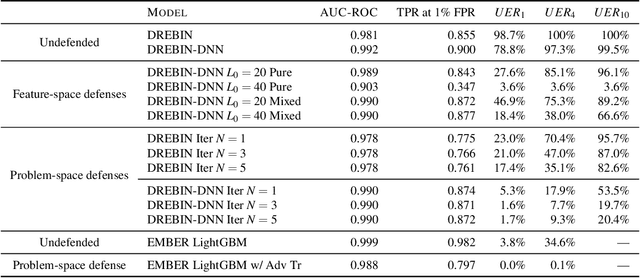
Machine learning classification models are vulnerable to adversarial examples -- effective input-specific perturbations that can manipulate the model's output. Universal Adversarial Perturbations (UAPs), which identify noisy patterns that generalize across the input space, allow the attacker to greatly scale up the generation of these adversarial examples. Although UAPs have been explored in application domains beyond computer vision, little is known about their properties and implications in the specific context of realizable attacks, such as malware, where attackers must reason about satisfying challenging problem-space constraints. In this paper, we explore the challenges and strengths of UAPs in the context of malware classification. We generate sequences of problem-space transformations that induce UAPs in the corresponding feature-space embedding and evaluate their effectiveness across threat models that consider a varying degree of realistic attacker knowledge. Additionally, we propose adversarial training-based mitigations using knowledge derived from the problem-space transformations, and compare against alternative feature-space defenses. Our experiments limit the effectiveness of a white box Android evasion attack to ~20 % at the cost of 3 % TPR at 1 % FPR. We additionally show how our method can be adapted to more restrictive application domains such as Windows malware. We observe that while adversarial training in the feature space must deal with large and often unconstrained regions, UAPs in the problem space identify specific vulnerabilities that allow us to harden a classifier more effectively, shifting the challenges and associated cost of identifying new universal adversarial transformations back to the attacker.
Robustness and Transferability of Universal Attacks on Compressed Models
Dec 10, 2020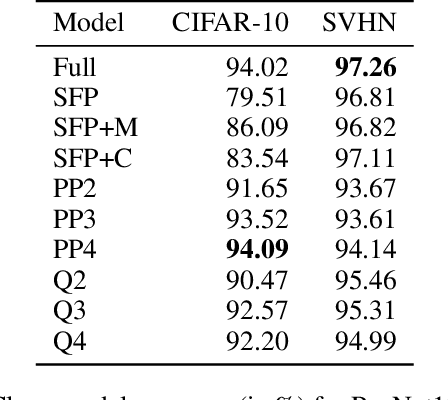
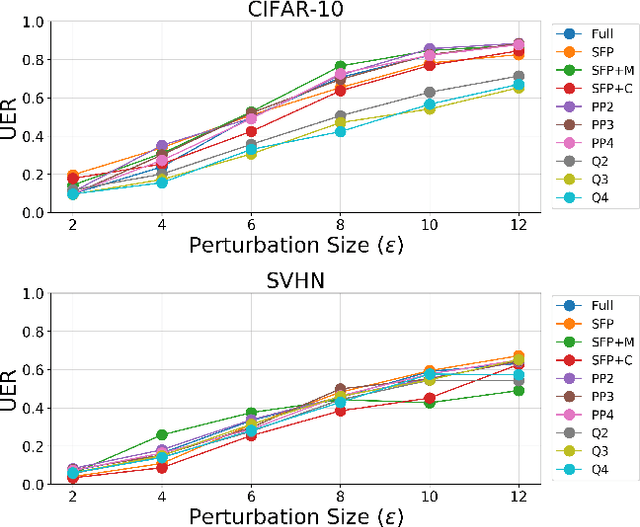

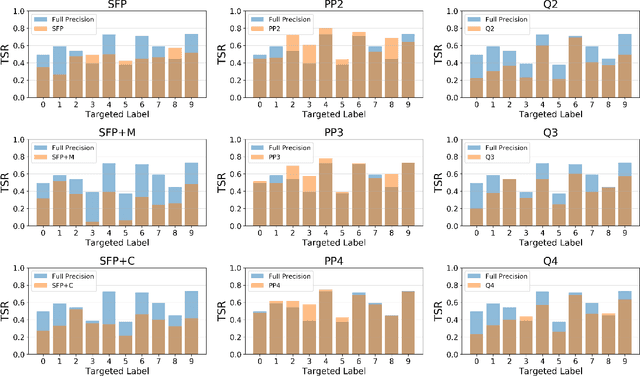
Neural network compression methods like pruning and quantization are very effective at efficiently deploying Deep Neural Networks (DNNs) on edge devices. However, DNNs remain vulnerable to adversarial examples-inconspicuous inputs that are specifically designed to fool these models. In particular, Universal Adversarial Perturbations (UAPs), are a powerful class of adversarial attacks which create adversarial perturbations that can generalize across a large set of inputs. In this work, we analyze the effect of various compression techniques to UAP attacks, including different forms of pruning and quantization. We test the robustness of compressed models to white-box and transfer attacks, comparing them with their uncompressed counterparts on CIFAR-10 and SVHN datasets. Our evaluations reveal clear differences between pruning methods, including Soft Filter and Post-training Pruning. We observe that UAP transfer attacks between pruned and full models are limited, suggesting that the systemic vulnerabilities across these models are different. This finding has practical implications as using different compression techniques can blunt the effectiveness of black-box transfer attacks. We show that, in some scenarios, quantization can produce gradient-masking, giving a false sense of security. Finally, our results suggest that conclusions about the robustness of compressed models to UAP attacks is application dependent, observing different phenomena in the two datasets used in our experiments.
Regularisation Can Mitigate Poisoning Attacks: A Novel Analysis Based on Multiobjective Bilevel Optimisation
Feb 28, 2020



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data can be manipulated to deliberately degrade the algorithms' performance. Optimal poisoning attacks, which can be formulated as bilevel optimisation problems, help to assess the robustness of learning algorithms in worst-case scenarios. However, current attacks against algorithms with hyperparameters typically assume that these hyperparameters are constant and thus ignore the effect the attack has on them. In this paper, we show that this approach leads to an overly pessimistic view of the robustness of the learning algorithms tested. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters by modelling the attack as a multiobjective bilevel optimisation problem. We apply this novel attack formulation to ML classifiers using $L_2$ regularisation and show that, in contrast to results previously reported in the literature, $L_2$ regularisation enhances the stability of the learning algorithms and helps to partially mitigate poisoning attacks. Our empirical evaluation on different datasets confirms the limitations of previous poisoning attack strategies, evidences the benefits of using $L_2$ regularisation to dampen the effect of poisoning attacks and shows that the regularisation hyperparameter increases as more malicious data points are injected in the training dataset.
Universal Adversarial Perturbations to Understand Robustness of Texture vs. Shape-biased Training
Nov 23, 2019
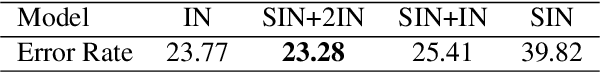
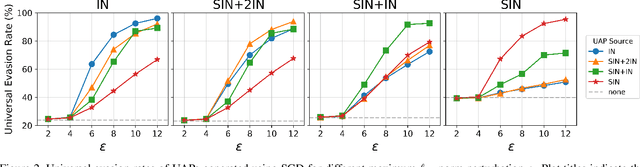
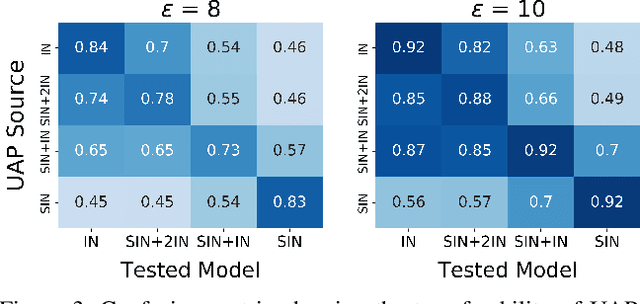
Convolutional Neural Networks (CNNs) used on image classification tasks such as ImageNet have been shown to be biased towards recognizing textures rather than shapes. Recent work has attempted to alleviate this by augmenting the training dataset with shape-based examples to create Stylized-ImageNet. However, in this paper we show that models trained on this dataset remain vulnerable to Universal Adversarial Perturbations (UAPs). We use UAPs to evaluate and compare the robustness of CNN models with varying degrees of shape-based training. We also find that a posteriori fine-tuning on ImageNet negates features learned from training on Stylized-ImageNet. This study reveals an important limitation and reiterates the need for further research into understanding the robustness of CNNs for visual recognition.