 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATRA: Modeling the Attack Surface of Agentic AI Systems -- OpenClaw Case Study
May 11, 2026LLMs are increasingly deployed as autonomous agents with access to tools, databases, and external services, yet practitioners (across different sectors) lack systematic methods to assess how known threat classes translate into concrete risks within a specific agentic deployment. We present MATRA, a pragmatic threat modeling framework for agentic AI systems that adapts established risk assessment methodology to systematically assess how known LLM threats translate into deployment-specific risks. MATRA begins with an asset-based impact assessment and utilizes attack trees to determine the likelihood of these impacts occurring within the system architecture. We demonstrate MATRA on a personal AI agent deployment using OpenClaw, quantifying how architectural controls such as network sandboxing and least-privilege access reduce risk by limiting the blast radius of successful injections.
Stealthy Poisoning Attacks Bypass Defenses in Regression Settings
Jan 29, 2026Regression models are widely used in industrial processes, engineering and in natural and physical sciences, yet their robustness to poisoning has received less attention. When it has, studies often assume unrealistic threat models and are thus less useful in practice. In this paper, we propose a novel optimal stealthy attack formulation that considers different degrees of detectability and show that it bypasses state-of-the-art defenses. We further propose a new methodology based on normalization of objectives to evaluate different trade-offs between effectiveness and detectability. Finally, we develop a novel defense (BayesClean) against stealthy attacks. BayesClean improves on previous defenses when attacks are stealthy and the number of poisoning points is significant.
FactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
Jan 16, 2026Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.
WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia
Jun 19, 2024
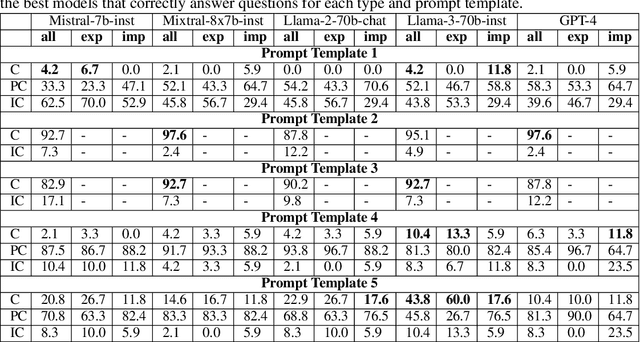
Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models struggle to generate answers that accurately reflect the conflicting nature of the context, especially for implicit conflicts requiring reasoning. Since human evaluation is costly, we also introduce an automated model that estimates LLM performance using a strong open-source language model, achieving an F-score of 0.8. Using this automated metric, we evaluate more than 1,500 answers from seven LLMs across all WikiContradict instances. To facilitate future work, we release WikiContradict on: https://ibm.biz/wikicontradict.
Hyperparameter Learning under Data Poisoning: Analysis of the Influence of Regularization via Multiobjective Bilevel Optimization
Jun 02, 2023



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to deliberately degrade the algorithms' performance. Optimal attacks can be formulated as bilevel optimization problems and help to assess their robustness in worst-case scenarios. We show that current approaches, which typically assume that hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters and models the attack as a multiobjective bilevel optimization problem. This allows to formulate optimal attacks, learn hyperparameters and evaluate robustness under worst-case conditions. We apply this attack formulation to several ML classifiers using $L_2$ and $L_1$ regularization. Our evaluation on multiple datasets confirms the limitations of previous strategies and evidences the benefits of using $L_2$ and $L_1$ regularization to dampen the effect of poisoning attacks.
Regularization Can Help Mitigate Poisoning Attacks... with the Right Hyperparameters
May 23, 2021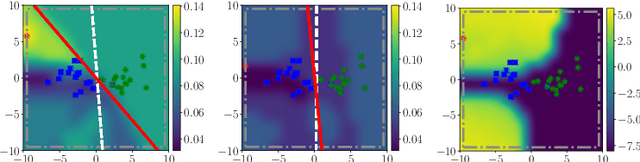

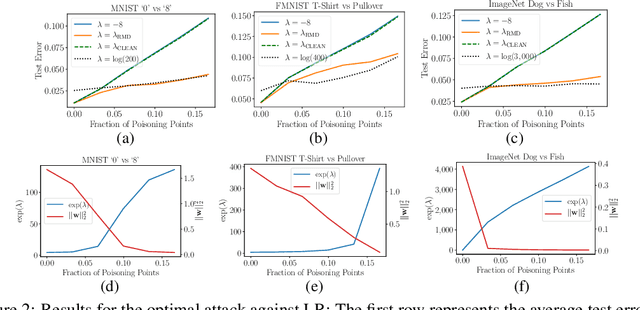
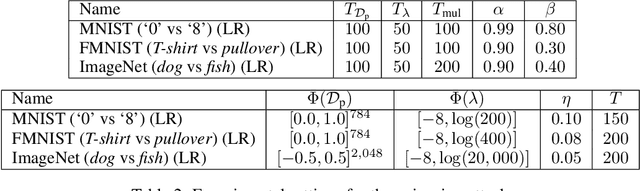
Machine learning algorithms are vulnerable to poisoning attacks, where a fraction of the training data is manipulated to degrade the algorithms' performance. We show that current approaches, which typically assume that regularization hyperparameters remain constant, lead to an overly pessimistic view of the algorithms' robustness and of the impact of regularization. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters, modelling the attack as a \emph{minimax bilevel optimization problem}. This allows to formulate optimal attacks, select hyperparameters and evaluate robustness under worst case conditions. We apply this formulation to logistic regression using $L_2$ regularization, empirically show the limitations of previous strategies and evidence the benefits of using $L_2$ regularization to dampen the effect of poisoning attacks.
Regularisation Can Mitigate Poisoning Attacks: A Novel Analysis Based on Multiobjective Bilevel Optimisation
Feb 28, 2020



Machine Learning (ML) algorithms are vulnerable to poisoning attacks, where a fraction of the training data can be manipulated to deliberately degrade the algorithms' performance. Optimal poisoning attacks, which can be formulated as bilevel optimisation problems, help to assess the robustness of learning algorithms in worst-case scenarios. However, current attacks against algorithms with hyperparameters typically assume that these hyperparameters are constant and thus ignore the effect the attack has on them. In this paper, we show that this approach leads to an overly pessimistic view of the robustness of the learning algorithms tested. We propose a novel optimal attack formulation that considers the effect of the attack on the hyperparameters by modelling the attack as a multiobjective bilevel optimisation problem. We apply this novel attack formulation to ML classifiers using $L_2$ regularisation and show that, in contrast to results previously reported in the literature, $L_2$ regularisation enhances the stability of the learning algorithms and helps to partially mitigate poisoning attacks. Our empirical evaluation on different datasets confirms the limitations of previous poisoning attack strategies, evidences the benefits of using $L_2$ regularisation to dampen the effect of poisoning attacks and shows that the regularisation hyperparameter increases as more malicious data points are injected in the training dataset.
Poisoning Attacks with Generative Adversarial Nets
Jun 18, 2019
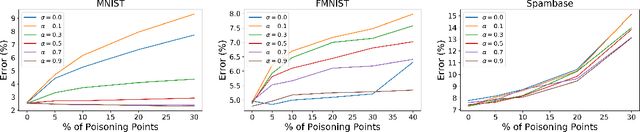


Machine learning algorithms are vulnerable to poisoning attacks: An adversary can inject malicious points in the training dataset to influence the learning process and degrade its performance. Optimal poisoning attacks have already been proposed to evaluate worst-case scenarios, modelling attacks as a bi-level optimisation problem. Solving these problems is computationally demanding and has limited applicability for some models such as deep networks. In this paper we introduce a novel generative model to craft systematic poisoning attacks against machine learning classifiers generating adversarial training examples, i.e. samples that look like genuine data points but that degrade the classifier's accuracy when used for training. We propose a Generative Adversarial Net with three components: generator, discriminator, and the target classifier. This approach allows us to model naturally the detectability constrains that can be expected in realistic attacks and to identify the regions of the underlying data distribution that can be more vulnerable to data poisoning. Our experimental evaluation shows the effectiveness of our attack to compromise machine learning classifiers, including deep networks.