 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticalibration yields better matchings
Nov 14, 2025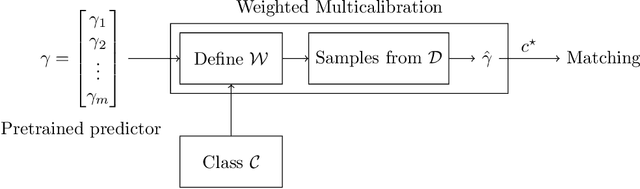
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
A Tight VC-Dimension Analysis of Clustering Coresets with Applications
Jan 11, 2025


We consider coresets for $k$-clustering problems, where the goal is to assign points to centers minimizing powers of distances. A popular example is the $k$-median objective $\sum_{p}\min_{c\in C}dist(p,C)$. Given a point set $P$, a coreset $\Omega$ is a small weighted subset that approximates the cost of $P$ for all candidate solutions $C$ up to a $(1\pm\varepsilon )$ multiplicative factor. In this paper, we give a sharp VC-dimension based analysis for coreset construction. As a consequence, we obtain improved $k$-median coreset bounds for the following metrics: Coresets of size $\tilde{O}\left(k\varepsilon^{-2}\right)$ for shortest path metrics in planar graphs, improving over the bounds $\tilde{O}\left(k\varepsilon^{-6}\right)$ by [Cohen-Addad, Saulpic, Schwiegelshohn, STOC'21] and $\tilde{O}\left(k^2\varepsilon^{-4}\right)$ by [Braverman, Jiang, Krauthgamer, Wu, SODA'21]. Coresets of size $\tilde{O}\left(kd\ell\varepsilon^{-2}\log m\right)$ for clustering $d$-dimensional polygonal curves of length at most $m$ with curves of length at most $\ell$ with respect to Frechet metrics, improving over the bounds $\tilde{O}\left(k^3d\ell\varepsilon^{-3}\log m\right)$ by [Braverman, Cohen-Addad, Jiang, Krauthgamer, Schwiegelshohn, Toftrup, and Wu, FOCS'22] and $\tilde{O}\left(k^2d\ell\varepsilon^{-2}\log m \log |P|\right)$ by [Conradi, Kolbe, Psarros, Rohde, SoCG'24].
Online Learning with Sublinear Best-Action Queries
Jul 23, 2024In online learning, a decision maker repeatedly selects one of a set of actions, with the goal of minimizing the overall loss incurred. Following the recent line of research on algorithms endowed with additional predictive features, we revisit this problem by allowing the decision maker to acquire additional information on the actions to be selected. In particular, we study the power of \emph{best-action queries}, which reveal beforehand the identity of the best action at a given time step. In practice, predictive features may be expensive, so we allow the decision maker to issue at most $k$ such queries. We establish tight bounds on the performance any algorithm can achieve when given access to $k$ best-action queries for different types of feedback models. In particular, we prove that in the full feedback model, $k$ queries are enough to achieve an optimal regret of $\Theta\left(\min\left\{\sqrt T, \frac Tk\right\}\right)$. This finding highlights the significant multiplicative advantage in the regret rate achievable with even a modest (sublinear) number $k \in \Omega(\sqrt{T})$ of queries. Additionally, we study the challenging setting in which the only available feedback is obtained during the time steps corresponding to the $k$ best-action queries. There, we provide a tight regret rate of $\Theta\left(\min\left\{\frac{T}{\sqrt k},\frac{T^2}{k^2}\right\}\right)$, which improves over the standard $\Theta\left(\frac{T}{\sqrt k}\right)$ regret rate for label efficient prediction for $k \in \Omega(T^{2/3})$.
Fully Dynamic Online Selection through Online Contention Resolution Schemes
Jan 08, 2023
We study fully dynamic online selection problems in an adversarial/stochastic setting that includes Bayesian online selection, prophet inequalities, posted price mechanisms, and stochastic probing problems subject to combinatorial constraints. In the classical ``incremental'' version of the problem, selected elements remain active until the end of the input sequence. On the other hand, in the fully dynamic version of the problem, elements stay active for a limited time interval, and then leave. This models, for example, the online matching of tasks to workers with task/worker-dependent working times, and sequential posted pricing of perishable goods. A successful approach to online selection problems in the adversarial setting is given by the notion of Online Contention Resolution Scheme (OCRS), that uses a priori information to formulate a linear relaxation of the underlying optimization problem, whose optimal fractional solution is rounded online for any adversarial order of the input sequence. Our main contribution is providing a general method for constructing an OCRS for fully dynamic online selection problems. Then, we show how to employ such OCRS to construct no-regret algorithms in a partial information model with semi-bandit feedback and adversarial inputs.
Poisoning Attacks with Generative Adversarial Nets
Jun 18, 2019
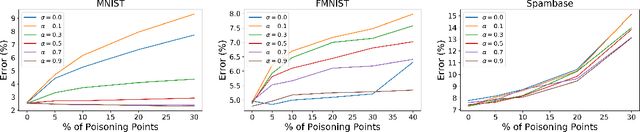


Machine learning algorithms are vulnerable to poisoning attacks: An adversary can inject malicious points in the training dataset to influence the learning process and degrade its performance. Optimal poisoning attacks have already been proposed to evaluate worst-case scenarios, modelling attacks as a bi-level optimisation problem. Solving these problems is computationally demanding and has limited applicability for some models such as deep networks. In this paper we introduce a novel generative model to craft systematic poisoning attacks against machine learning classifiers generating adversarial training examples, i.e. samples that look like genuine data points but that degrade the classifier's accuracy when used for training. We propose a Generative Adversarial Net with three components: generator, discriminator, and the target classifier. This approach allows us to model naturally the detectability constrains that can be expected in realistic attacks and to identify the regions of the underlying data distribution that can be more vulnerable to data poisoning. Our experimental evaluation shows the effectiveness of our attack to compromise machine learning classifiers, including deep networks.