 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfit Maximization in Bilateral Trade against a Smooth Adversary
May 12, 2026Bilateral trade models the task of intermediating between two strategic agents, a seller and a buyer, who wish to trade a good. We study this problem from the perspective of a profit-maximizing broker within an online learning framework, where the agents' valuations are generated by a smooth adversary. We devise a learning algorithm that guarantees a $\tilde{O}(\sqrt{T})$ regret bound, which is tight in the time horizon $T$ up to poly-logarithmic factors. This matches the minimax rate for the stochastic i.i.d. case, and is also well separated from the adversarial setting, where sublinear-regret is unattainable. By extending the strong regret guarantees from the i.i.d. case to the smooth adversary, we significantly broaden the scope of settings where such fast rate is achievable, while closing an important gap in the regret landscape of this fundamental economic problem. To overcome the challenges posed by this adversary, we leverage a continuity property of smooth instances and combines this with a hierarchical net-construction of the broker's action space, which is analyzed via algorithmic chaining. We showcase the applicability of these techniques by deriving a similarly tight $\tilde{O}(\sqrt{T})$ regret bound for a related mechanism design model: the joint ads problem.
Nearly Tight Regret Bounds for Profit Maximization in Bilateral Trade
Sep 26, 2025Bilateral trade models the task of intermediating between two strategic agents, a seller and a buyer, willing to trade a good for which they hold private valuations. We study this problem from the perspective of a broker, in a regret minimization framework. At each time step, a new seller and buyer arrive, and the broker has to propose a mechanism that is incentive-compatible and individually rational, with the goal of maximizing profit. We propose a learning algorithm that guarantees a nearly tight $\tilde{O}(\sqrt{T})$ regret in the stochastic setting when seller and buyer valuations are drawn i.i.d. from a fixed and possibly correlated unknown distribution. We further show that it is impossible to achieve sublinear regret in the non-stationary scenario where valuations are generated upfront by an adversary. Our ambitious benchmark for these results is the best incentive-compatible and individually rational mechanism. This separates us from previous works on efficiency maximization in bilateral trade, where the benchmark is a single number: the best fixed price in hindsight. A particular challenge we face is that uniform convergence for all mechanisms' profits is impossible. We overcome this difficulty via a careful chaining analysis that proves convergence for a provably near-optimal mechanism at (essentially) optimal rate. We further showcase the broader applicability of our techniques by providing nearly optimal results for the joint ads problem.
Improved Learning via k-DTW: A Novel Dissimilarity Measure for Curves
May 29, 2025This paper introduces $k$-Dynamic Time Warping ($k$-DTW), a novel dissimilarity measure for polygonal curves. $k$-DTW has stronger metric properties than Dynamic Time Warping (DTW) and is more robust to outliers than the Fr\'{e}chet distance, which are the two gold standards of dissimilarity measures for polygonal curves. We show interesting properties of $k$-DTW and give an exact algorithm as well as a $(1+\varepsilon)$-approximation algorithm for $k$-DTW by a parametric search for the $k$-th largest matched distance. We prove the first dimension-free learning bounds for curves and further learning theoretic results. $k$-DTW not only admits smaller sample size than DTW for the problem of learning the median of curves, where some factors depending on the curves' complexity $m$ are replaced by $k$, but we also show a surprising separation on the associated Rademacher and Gaussian complexities: $k$-DTW admits strictly smaller bounds than DTW, by a factor $\tilde\Omega(\sqrt{m})$ when $k\ll m$. We complement our theoretical findings with an experimental illustration of the benefits of using $k$-DTW for clustering and nearest neighbor classification.
A Tight VC-Dimension Analysis of Clustering Coresets with Applications
Jan 11, 2025


We consider coresets for $k$-clustering problems, where the goal is to assign points to centers minimizing powers of distances. A popular example is the $k$-median objective $\sum_{p}\min_{c\in C}dist(p,C)$. Given a point set $P$, a coreset $\Omega$ is a small weighted subset that approximates the cost of $P$ for all candidate solutions $C$ up to a $(1\pm\varepsilon )$ multiplicative factor. In this paper, we give a sharp VC-dimension based analysis for coreset construction. As a consequence, we obtain improved $k$-median coreset bounds for the following metrics: Coresets of size $\tilde{O}\left(k\varepsilon^{-2}\right)$ for shortest path metrics in planar graphs, improving over the bounds $\tilde{O}\left(k\varepsilon^{-6}\right)$ by [Cohen-Addad, Saulpic, Schwiegelshohn, STOC'21] and $\tilde{O}\left(k^2\varepsilon^{-4}\right)$ by [Braverman, Jiang, Krauthgamer, Wu, SODA'21]. Coresets of size $\tilde{O}\left(kd\ell\varepsilon^{-2}\log m\right)$ for clustering $d$-dimensional polygonal curves of length at most $m$ with curves of length at most $\ell$ with respect to Frechet metrics, improving over the bounds $\tilde{O}\left(k^3d\ell\varepsilon^{-3}\log m\right)$ by [Braverman, Cohen-Addad, Jiang, Krauthgamer, Schwiegelshohn, Toftrup, and Wu, FOCS'22] and $\tilde{O}\left(k^2d\ell\varepsilon^{-2}\log m \log |P|\right)$ by [Conradi, Kolbe, Psarros, Rohde, SoCG'24].
On Approximability of $\ell_2^2$ Min-Sum Clustering
Dec 04, 2024



The $\ell_2^2$ min-sum $k$-clustering problem is to partition an input set into clusters $C_1,\ldots,C_k$ to minimize $\sum_{i=1}^k\sum_{p,q\in C_i}\|p-q\|_2^2$. Although $\ell_2^2$ min-sum $k$-clustering is NP-hard, it is not known whether it is NP-hard to approximate $\ell_2^2$ min-sum $k$-clustering beyond a certain factor. In this paper, we give the first hardness-of-approximation result for the $\ell_2^2$ min-sum $k$-clustering problem. We show that it is NP-hard to approximate the objective to a factor better than $1.056$ and moreover, assuming a balanced variant of the Johnson Coverage Hypothesis, it is NP-hard to approximate the objective to a factor better than 1.327. We then complement our hardness result by giving the first $(1+\varepsilon)$-coreset construction for $\ell_2^2$ min-sum $k$-clustering. Our coreset uses $\mathcal{O}\left(k^{\varepsilon^{-4}}\right)$ space and can be leveraged to achieve a polynomial-time approximation scheme with runtime $nd\cdot f(k,\varepsilon^{-1})$, where $d$ is the underlying dimension of the input dataset and $f$ is a fixed function. Finally, we consider a learning-augmented setting, where the algorithm has access to an oracle that outputs a label $i\in[k]$ for input point, thereby implicitly partitioning the input dataset into $k$ clusters that induce an approximately optimal solution, up to some amount of adversarial error $\alpha\in\left[0,\frac{1}{2}\right)$. We give a polynomial-time algorithm that outputs a $\frac{1+\gamma\alpha}{(1-\alpha)^2}$-approximation to $\ell_2^2$ min-sum $k$-clustering, for a fixed constant $\gamma>0$.
Distributed Differentially Private Data Analytics via Secure Sketching
Nov 30, 2024We explore the use of distributed differentially private computations across multiple servers, balancing the tradeoff between the error introduced by the differentially private mechanism and the computational efficiency of the resulting distributed algorithm. We introduce the linear-transformation model, where clients have access to a trusted platform capable of applying a public matrix to their inputs. Such computations can be securely distributed across multiple servers using simple and efficient secure multiparty computation techniques. The linear-transformation model serves as an intermediate model between the highly expressive central model and the minimal local model. In the central model, clients have access to a trusted platform capable of applying any function to their inputs. However, this expressiveness comes at a cost, as it is often expensive to distribute such computations, leading to the central model typically being implemented by a single trusted server. In contrast, the local model assumes no trusted platform, which forces clients to add significant noise to their data. The linear-transformation model avoids the single point of failure for privacy present in the central model, while also mitigating the high noise required in the local model. We demonstrate that linear transformations are very useful for differential privacy, allowing for the computation of linear sketches of input data. These sketches largely preserve utility for tasks such as private low-rank approximation and private ridge regression, while introducing only minimal error, critically independent of the number of clients. Previously, such accuracy had only been achieved in the more expressive central model.
Settling Time vs. Accuracy Tradeoffs for Clustering Big Data
Apr 02, 2024


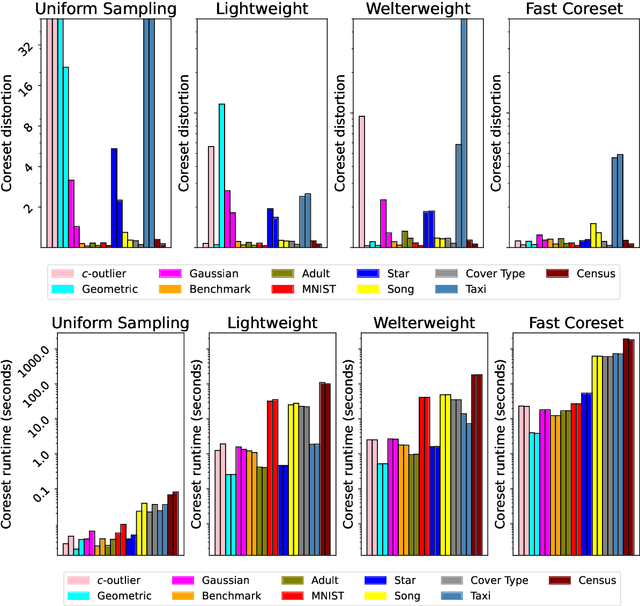
We study the theoretical and practical runtime limits of k-means and k-median clustering on large datasets. Since effectively all clustering methods are slower than the time it takes to read the dataset, the fastest approach is to quickly compress the data and perform the clustering on the compressed representation. Unfortunately, there is no universal best choice for compressing the number of points - while random sampling runs in sublinear time and coresets provide theoretical guarantees, the former does not enforce accuracy while the latter is too slow as the numbers of points and clusters grow. Indeed, it has been conjectured that any sensitivity-based coreset construction requires super-linear time in the dataset size. We examine this relationship by first showing that there does exist an algorithm that obtains coresets via sensitivity sampling in effectively linear time - within log-factors of the time it takes to read the data. Any approach that significantly improves on this must then resort to practical heuristics, leading us to consider the spectrum of sampling strategies across both real and artificial datasets in the static and streaming settings. Through this, we show the conditions in which coresets are necessary for preserving cluster validity as well as the settings in which faster, cruder sampling strategies are sufficient. As a result, we provide a comprehensive theoretical and practical blueprint for effective clustering regardless of data size. Our code is publicly available and has scripts to recreate the experiments.
On Generalization Bounds for Projective Clustering
Oct 13, 2023



Given a set of points, clustering consists of finding a partition of a point set into $k$ clusters such that the center to which a point is assigned is as close as possible. Most commonly, centers are points themselves, which leads to the famous $k$-median and $k$-means objectives. One may also choose centers to be $j$ dimensional subspaces, which gives rise to subspace clustering. In this paper, we consider learning bounds for these problems. That is, given a set of $n$ samples $P$ drawn independently from some unknown, but fixed distribution $\mathcal{D}$, how quickly does a solution computed on $P$ converge to the optimal clustering of $\mathcal{D}$? We give several near optimal results. In particular, For center-based objectives, we show a convergence rate of $\tilde{O}\left(\sqrt{{k}/{n}}\right)$. This matches the known optimal bounds of [Fefferman, Mitter, and Narayanan, Journal of the Mathematical Society 2016] and [Bartlett, Linder, and Lugosi, IEEE Trans. Inf. Theory 1998] for $k$-means and extends it to other important objectives such as $k$-median. For subspace clustering with $j$-dimensional subspaces, we show a convergence rate of $\tilde{O}\left(\sqrt{\frac{kj^2}{n}}\right)$. These are the first provable bounds for most of these problems. For the specific case of projective clustering, which generalizes $k$-means, we show a convergence rate of $\Omega\left(\sqrt{\frac{kj}{n}}\right)$ is necessary, thereby proving that the bounds from [Fefferman, Mitter, and Narayanan, Journal of the Mathematical Society 2016] are essentially optimal.
Optimal Sketching Bounds for Sparse Linear Regression
Apr 05, 2023
We study oblivious sketching for $k$-sparse linear regression under various loss functions such as an $\ell_p$ norm, or from a broad class of hinge-like loss functions, which includes the logistic and ReLU losses. We show that for sparse $\ell_2$ norm regression, there is a distribution over oblivious sketches with $\Theta(k\log(d/k)/\varepsilon^2)$ rows, which is tight up to a constant factor. This extends to $\ell_p$ loss with an additional additive $O(k\log(k/\varepsilon)/\varepsilon^2)$ term in the upper bound. This establishes a surprising separation from the related sparse recovery problem, which is an important special case of sparse regression. For this problem, under the $\ell_2$ norm, we observe an upper bound of $O(k \log (d)/\varepsilon + k\log(k/\varepsilon)/\varepsilon^2)$ rows, showing that sparse recovery is strictly easier to sketch than sparse regression. For sparse regression under hinge-like loss functions including sparse logistic and sparse ReLU regression, we give the first known sketching bounds that achieve $o(d)$ rows showing that $O(\mu^2 k\log(\mu n d/\varepsilon)/\varepsilon^2)$ rows suffice, where $\mu$ is a natural complexity parameter needed to obtain relative error bounds for these loss functions. We again show that this dimension is tight, up to lower order terms and the dependence on $\mu$. Finally, we show that similar sketching bounds can be achieved for LASSO regression, a popular convex relaxation of sparse regression, where one aims to minimize $\|Ax-b\|_2^2+\lambda\|x\|_1$ over $x\in\mathbb{R}^d$. We show that sketching dimension $O(\log(d)/(\lambda \varepsilon)^2)$ suffices and that the dependence on $d$ and $\lambda$ is tight.
Sparse Dimensionality Reduction Revisited
Feb 13, 2023The sparse Johnson-Lindenstrauss transform is one of the central techniques in dimensionality reduction. It supports embedding a set of $n$ points in $\mathbb{R}^d$ into $m=O(\varepsilon^{-2} \lg n)$ dimensions while preserving all pairwise distances to within $1 \pm \varepsilon$. Each input point $x$ is embedded to $Ax$, where $A$ is an $m \times d$ matrix having $s$ non-zeros per column, allowing for an embedding time of $O(s \|x\|_0)$. Since the sparsity of $A$ governs the embedding time, much work has gone into improving the sparsity $s$. The current state-of-the-art by Kane and Nelson (JACM'14) shows that $s = O(\varepsilon ^{-1} \lg n)$ suffices. This is almost matched by a lower bound of $s = \Omega(\varepsilon ^{-1} \lg n/\lg(1/\varepsilon))$ by Nelson and Nguyen (STOC'13). Previous work thus suggests that we have near-optimal embeddings. In this work, we revisit sparse embeddings and identify a loophole in the lower bound. Concretely, it requires $d \geq n$, which in many applications is unrealistic. We exploit this loophole to give a sparser embedding when $d = o(n)$, achieving $s = O(\varepsilon^{-1}(\lg n/\lg(1/\varepsilon)+\lg^{2/3}n \lg^{1/3} d))$. We also complement our analysis by strengthening the lower bound of Nelson and Nguyen to hold also when $d \ll n$, thereby matching the first term in our new sparsity upper bound. Finally, we also improve the sparsity of the best oblivious subspace embeddings for optimal embedding dimensionality.