 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticalibration yields better matchings
Nov 14, 2025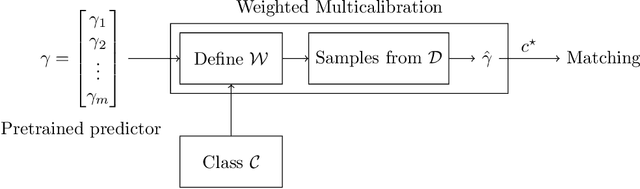
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
Nearly Tight Regret Bounds for Profit Maximization in Bilateral Trade
Sep 26, 2025Bilateral trade models the task of intermediating between two strategic agents, a seller and a buyer, willing to trade a good for which they hold private valuations. We study this problem from the perspective of a broker, in a regret minimization framework. At each time step, a new seller and buyer arrive, and the broker has to propose a mechanism that is incentive-compatible and individually rational, with the goal of maximizing profit. We propose a learning algorithm that guarantees a nearly tight $\tilde{O}(\sqrt{T})$ regret in the stochastic setting when seller and buyer valuations are drawn i.i.d. from a fixed and possibly correlated unknown distribution. We further show that it is impossible to achieve sublinear regret in the non-stationary scenario where valuations are generated upfront by an adversary. Our ambitious benchmark for these results is the best incentive-compatible and individually rational mechanism. This separates us from previous works on efficiency maximization in bilateral trade, where the benchmark is a single number: the best fixed price in hindsight. A particular challenge we face is that uniform convergence for all mechanisms' profits is impossible. We overcome this difficulty via a careful chaining analysis that proves convergence for a provably near-optimal mechanism at (essentially) optimal rate. We further showcase the broader applicability of our techniques by providing nearly optimal results for the joint ads problem.
The Cost of Consistency: Submodular Maximization with Constant Recourse
Dec 03, 2024



In this work, we study online submodular maximization, and how the requirement of maintaining a stable solution impacts the approximation. In particular, we seek bounds on the best-possible approximation ratio that is attainable when the algorithm is allowed to make at most a constant number of updates per step. We show a tight information-theoretic bound of $\tfrac{2}{3}$ for general monotone submodular functions, and an improved (also tight) bound of $\tfrac{3}{4}$ for coverage functions. Since both these bounds are attained by non poly-time algorithms, we also give a poly-time randomized algorithm that achieves a $0.51$-approximation. Combined with an information-theoretic hardness of $\tfrac{1}{2}$ for deterministic algorithms from prior work, our work thus shows a separation between deterministic and randomized algorithms, both information theoretically and for poly-time algorithms.
Selling Joint Ads: A Regret Minimization Perspective
Sep 12, 2024
Motivated by online retail, we consider the problem of selling one item (e.g., an ad slot) to two non-excludable buyers (say, a merchant and a brand). This problem captures, for example, situations where a merchant and a brand cooperatively bid in an auction to advertise a product, and both benefit from the ad being shown. A mechanism collects bids from the two and decides whether to allocate and which payments the two parties should make. This gives rise to intricate incentive compatibility constraints, e.g., on how to split payments between the two parties. We approach the problem of finding a revenue-maximizing incentive-compatible mechanism from an online learning perspective; this poses significant technical challenges. First, the action space (the class of all possible mechanisms) is huge; second, the function that maps mechanisms to revenue is highly irregular, ruling out standard discretization-based approaches. In the stochastic setting, we design an efficient learning algorithm achieving a regret bound of $O(T^{3/4})$. Our approach is based on an adaptive discretization scheme of the space of mechanisms, as any non-adaptive discretization fails to achieve sublinear regret. In the adversarial setting, we exploit the non-Lipschitzness of the problem to prove a strong negative result, namely that no learning algorithm can achieve more than half of the revenue of the best fixed mechanism in hindsight. We then consider the $\sigma$-smooth adversary; we construct an efficient learning algorithm that achieves a regret bound of $O(T^{2/3})$ and builds on a succinct encoding of exponentially many experts. Finally, we prove that no learning algorithm can achieve less than $\Omega(\sqrt T)$ regret in both the stochastic and the smooth setting, thus narrowing the range where the minimax regret rates for these two problems lie.
Online Learning with Sublinear Best-Action Queries
Jul 23, 2024In online learning, a decision maker repeatedly selects one of a set of actions, with the goal of minimizing the overall loss incurred. Following the recent line of research on algorithms endowed with additional predictive features, we revisit this problem by allowing the decision maker to acquire additional information on the actions to be selected. In particular, we study the power of \emph{best-action queries}, which reveal beforehand the identity of the best action at a given time step. In practice, predictive features may be expensive, so we allow the decision maker to issue at most $k$ such queries. We establish tight bounds on the performance any algorithm can achieve when given access to $k$ best-action queries for different types of feedback models. In particular, we prove that in the full feedback model, $k$ queries are enough to achieve an optimal regret of $\Theta\left(\min\left\{\sqrt T, \frac Tk\right\}\right)$. This finding highlights the significant multiplicative advantage in the regret rate achievable with even a modest (sublinear) number $k \in \Omega(\sqrt{T})$ of queries. Additionally, we study the challenging setting in which the only available feedback is obtained during the time steps corresponding to the $k$ best-action queries. There, we provide a tight regret rate of $\Theta\left(\min\left\{\frac{T}{\sqrt k},\frac{T^2}{k^2}\right\}\right)$, which improves over the standard $\Theta\left(\frac{T}{\sqrt k}\right)$ regret rate for label efficient prediction for $k \in \Omega(T^{2/3})$.
Consistent Submodular Maximization
May 30, 2024


Maximizing monotone submodular functions under cardinality constraints is a classic optimization task with several applications in data mining and machine learning. In this paper we study this problem in a dynamic environment with consistency constraints: elements arrive in a streaming fashion and the goal is maintaining a constant approximation to the optimal solution while having a stable solution (i.e., the number of changes between two consecutive solutions is bounded). We provide algorithms in this setting with different trade-offs between consistency and approximation quality. We also complement our theoretical results with an experimental analysis showing the effectiveness of our algorithms in real-world instances.
Beyond Primal-Dual Methods in Bandits with Stochastic and Adversarial Constraints
May 25, 2024We address a generalization of the bandit with knapsacks problem, where a learner aims to maximize rewards while satisfying an arbitrary set of long-term constraints. Our goal is to design best-of-both-worlds algorithms that perform optimally under both stochastic and adversarial constraints. Previous works address this problem via primal-dual methods, and require some stringent assumptions, namely the Slater's condition, and in adversarial settings, they either assume knowledge of a lower bound on the Slater's parameter, or impose strong requirements on the primal and dual regret minimizers such as requiring weak adaptivity. We propose an alternative and more natural approach based on optimistic estimations of the constraints. Surprisingly, we show that estimating the constraints with an UCB-like approach guarantees optimal performances. Our algorithm consists of two main components: (i) a regret minimizer working on \emph{moving strategy sets} and (ii) an estimate of the feasible set as an optimistic weighted empirical mean of previous samples. The key challenge in this approach is designing adaptive weights that meet the different requirements for stochastic and adversarial constraints. Our algorithm is significantly simpler than previous approaches, and has a cleaner analysis. Moreover, ours is the first best-of-both-worlds algorithm providing bounds logarithmic in the number of constraints. Additionally, in stochastic settings, it provides $\widetilde O(\sqrt{T})$ regret \emph{without} Slater's condition.
No-Regret Learning in Bilateral Trade via Global Budget Balance
Oct 18, 2023Bilateral trade revolves around the challenge of facilitating transactions between two strategic agents -- a seller and a buyer -- both of whom have a private valuations for the item. We study the online version of the problem, in which at each time step a new seller and buyer arrive. The learner's task is to set a price for each agent, without any knowledge about their valuations. The sequence of sellers and buyers is chosen by an oblivious adversary. In this setting, known negative results rule out the possibility of designing algorithms with sublinear regret when the learner has to guarantee budget balance for each iteration. In this paper, we introduce the notion of global budget balance, which requires the agent to be budget balance only over the entire time horizon. By requiring global budget balance, we provide the first no-regret algorithms for bilateral trade with adversarial inputs under various feedback models. First, we show that in the full-feedback model the learner can guarantee $\tilde{O}(\sqrt{T})$ regret against the best fixed prices in hindsight, which is order-wise optimal. Then, in the case of partial feedback models, we provide an algorithm guaranteeing a $\tilde{O}(T^{3/4})$ regret upper bound with one-bit feedback, which we complement with a nearly-matching lower bound. Finally, we investigate how these results vary when measuring regret using an alternative benchmark.
The Role of Transparency in Repeated First-Price Auctions with Unknown Valuations
Jul 14, 2023



We study the problem of regret minimization for a single bidder in a sequence of first-price auctions where the bidder knows the item's value only if the auction is won. Our main contribution is a complete characterization, up to logarithmic factors, of the minimax regret in terms of the auction's transparency, which regulates the amount of information on competing bids disclosed by the auctioneer at the end of each auction. Our results hold under different assumptions (stochastic, adversarial, and their smoothed variants) on the environment generating the bidder's valuations and competing bids. These minimax rates reveal how the interplay between transparency and the nature of the environment affects how fast one can learn to bid optimally in first-price auctions.
Bandits with Replenishable Knapsacks: the Best of both Worlds
Jun 14, 2023The bandits with knapsack (BwK) framework models online decision-making problems in which an agent makes a sequence of decisions subject to resource consumption constraints. The traditional model assumes that each action consumes a non-negative amount of resources and the process ends when the initial budgets are fully depleted. We study a natural generalization of the BwK framework which allows non-monotonic resource utilization, i.e., resources can be replenished by a positive amount. We propose a best-of-both-worlds primal-dual template that can handle any online learning problem with replenishment for which a suitable primal regret minimizer exists. In particular, we provide the first positive results for the case of adversarial inputs by showing that our framework guarantees a constant competitive ratio $\alpha$ when $B=\Omega(T)$ or when the possible per-round replenishment is a positive constant. Moreover, under a stochastic input model, our algorithm yields an instance-independent $\tilde{O}(T^{1/2})$ regret bound which complements existing instance-dependent bounds for the same setting. Finally, we provide applications of our framework to some economic problems of practical relevance.