 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin-Max Optimization Requires Exponentially Many Queries
May 13, 2026We study the query complexity of min-max optimization of a nonconvex-nonconcave function $f$ over $[0,1]^d \times [0,1]^d$. We show that, given oracle access to $f$ and to its gradient $\nabla f$, any algorithm that finds an $\varepsilon$-approximate stationary point must make a number of queries that is exponential in $1/\varepsilon$ or $d$.
Nonparametric Contextual Online Bilateral Trade
Feb 13, 2026We study the problem of contextual online bilateral trade. At each round, the learner faces a seller-buyer pair and must propose a trade price without observing their private valuations for the item being sold. The goal of the learner is to post prices to facilitate trades between the two parties. Before posting a price, the learner observes a $d$-dimensional context vector that influences the agent's valuations. Prior work in the contextual setting has focused on linear models. In this work, we tackle a general nonparametric setting in which the buyer's and seller's valuations behave according to arbitrary Lipschitz functions of the context. We design an algorithm that leverages contextual information through a hierarchical tree construction and guarantees regret $\widetilde{O}(T^{{(d-1)}/d})$. Remarkably, our algorithm operates under two stringent features of the setting: (1) one-bit feedback, where the learner only observes whether a trade occurred or not, and (2) strong budget balance, where the learner cannot subsidize or profit from the market participants. We further provide a matching lower bound in the full-feedback setting, demonstrating the tightness of our regret bound.
Optimal Rates for Feasible Payoff Set Estimation in Games
Feb 04, 2026We study a setting in which two players play a (possibly approximate) Nash equilibrium of a bimatrix game, while a learner observes only their actions and has no knowledge of the equilibrium or the underlying game. A natural question is whether the learner can rationalize the observed behavior by inferring the players' payoff functions. Rather than producing a single payoff estimate, inverse game theory aims to identify the entire set of payoffs consistent with observed behavior, enabling downstream use in, e.g., counterfactual analysis and mechanism design across applications like auctions, pricing, and security games. We focus on the problem of estimating the set of feasible payoffs with high probability and up to precision $ε$ on the Hausdorff metric. We provide the first minimax-optimal rates for both exact and approximate equilibrium play, in zero-sum as well as general-sum games. Our results provide learning-theoretic foundations for set-valued payoff inference in multi-agent environments.
Pure Exploration with Infinite Answers
May 28, 2025We study pure exploration problems where the set of correct answers is possibly infinite, e.g., the regression of any continuous function of the means of the bandit. We derive an instance-dependent lower bound for these problems. By analyzing it, we discuss why existing methods (i.e., Sticky Track-and-Stop) for finite answer problems fail at being asymptotically optimal in this more general setting. Finally, we present a framework, Sticky-Sequence Track-and-Stop, which generalizes both Track-and-Stop and Sticky Track-and-Stop, and that enjoys asymptotic optimality. Due to its generality, our analysis also highlights special cases where existing methods enjoy optimality.
Non-Asymptotic Analysis of (Sticky) Track-and-Stop
May 28, 2025In pure exploration problems, a statistician sequentially collects information to answer a question about some stochastic and unknown environment. The probability of returning a wrong answer should not exceed a maximum risk parameter $\delta$ and good algorithms make as few queries to the environment as possible. The Track-and-Stop algorithm is a pioneering method to solve these problems. Specifically, it is well-known that it enjoys asymptotic optimality sample complexity guarantees for $\delta\to 0$ whenever the map from the environment to its correct answers is single-valued (e.g., best-arm identification with a unique optimal arm). The Sticky Track-and-Stop algorithm extends these results to settings where, for each environment, there might exist multiple correct answers (e.g., $\epsilon$-optimal arm identification). Although both methods are optimal in the asymptotic regime, their non-asymptotic guarantees remain unknown. In this work, we fill this gap and provide non-asymptotic guarantees for both algorithms.
Beyond Primal-Dual Methods in Bandits with Stochastic and Adversarial Constraints
May 25, 2024We address a generalization of the bandit with knapsacks problem, where a learner aims to maximize rewards while satisfying an arbitrary set of long-term constraints. Our goal is to design best-of-both-worlds algorithms that perform optimally under both stochastic and adversarial constraints. Previous works address this problem via primal-dual methods, and require some stringent assumptions, namely the Slater's condition, and in adversarial settings, they either assume knowledge of a lower bound on the Slater's parameter, or impose strong requirements on the primal and dual regret minimizers such as requiring weak adaptivity. We propose an alternative and more natural approach based on optimistic estimations of the constraints. Surprisingly, we show that estimating the constraints with an UCB-like approach guarantees optimal performances. Our algorithm consists of two main components: (i) a regret minimizer working on \emph{moving strategy sets} and (ii) an estimate of the feasible set as an optimistic weighted empirical mean of previous samples. The key challenge in this approach is designing adaptive weights that meet the different requirements for stochastic and adversarial constraints. Our algorithm is significantly simpler than previous approaches, and has a cleaner analysis. Moreover, ours is the first best-of-both-worlds algorithm providing bounds logarithmic in the number of constraints. Additionally, in stochastic settings, it provides $\widetilde O(\sqrt{T})$ regret \emph{without} Slater's condition.
No-Regret is not enough! Bandits with General Constraints through Adaptive Regret Minimization
May 10, 2024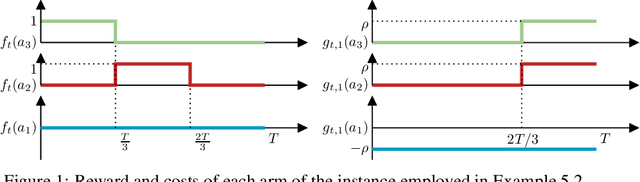
In the bandits with knapsacks framework (BwK) the learner has $m$ resource-consumption (packing) constraints. We focus on the generalization of BwK in which the learner has a set of general long-term constraints. The goal of the learner is to maximize their cumulative reward, while at the same time achieving small cumulative constraints violations. In this scenario, there exist simple instances where conventional methods for BwK fail to yield sublinear violations of constraints. We show that it is possible to circumvent this issue by requiring the primal and dual algorithm to be weakly adaptive. Indeed, even in absence on any information on the Slater's parameter $\rho$ characterizing the problem, the interplay between weakly adaptive primal and dual regret minimizers yields a "self-bounding" property of dual variables. In particular, their norm remains suitably upper bounded across the entire time horizon even without explicit projection steps. By exploiting this property, we provide best-of-both-worlds guarantees for stochastic and adversarial inputs. In the first case, we show that the algorithm guarantees sublinear regret. In the latter case, we establish a tight competitive ratio of $\rho/(1+\rho)$. In both settings, constraints violations are guaranteed to be sublinear in time. Finally, this results allow us to obtain new result for the problem of contextual bandits with linear constraints, providing the first no-$\alpha$-regret guarantees for adversarial contexts.
No-Regret Learning in Bilateral Trade via Global Budget Balance
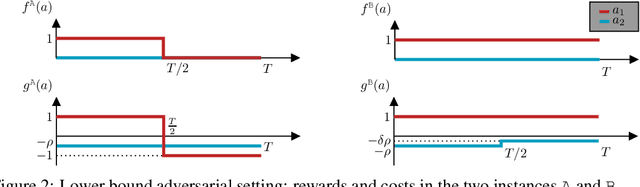
Oct 18, 2023Bilateral trade revolves around the challenge of facilitating transactions between two strategic agents -- a seller and a buyer -- both of whom have a private valuations for the item. We study the online version of the problem, in which at each time step a new seller and buyer arrive. The learner's task is to set a price for each agent, without any knowledge about their valuations. The sequence of sellers and buyers is chosen by an oblivious adversary. In this setting, known negative results rule out the possibility of designing algorithms with sublinear regret when the learner has to guarantee budget balance for each iteration. In this paper, we introduce the notion of global budget balance, which requires the agent to be budget balance only over the entire time horizon. By requiring global budget balance, we provide the first no-regret algorithms for bilateral trade with adversarial inputs under various feedback models. First, we show that in the full-feedback model the learner can guarantee $\tilde{O}(\sqrt{T})$ regret against the best fixed prices in hindsight, which is order-wise optimal. Then, in the case of partial feedback models, we provide an algorithm guaranteeing a $\tilde{O}(T^{3/4})$ regret upper bound with one-bit feedback, which we complement with a nearly-matching lower bound. Finally, we investigate how these results vary when measuring regret using an alternative benchmark.
Bandits with Replenishable Knapsacks: the Best of both Worlds
Jun 14, 2023The bandits with knapsack (BwK) framework models online decision-making problems in which an agent makes a sequence of decisions subject to resource consumption constraints. The traditional model assumes that each action consumes a non-negative amount of resources and the process ends when the initial budgets are fully depleted. We study a natural generalization of the BwK framework which allows non-monotonic resource utilization, i.e., resources can be replenished by a positive amount. We propose a best-of-both-worlds primal-dual template that can handle any online learning problem with replenishment for which a suitable primal regret minimizer exists. In particular, we provide the first positive results for the case of adversarial inputs by showing that our framework guarantees a constant competitive ratio $\alpha$ when $B=\Omega(T)$ or when the possible per-round replenishment is a positive constant. Moreover, under a stochastic input model, our algorithm yields an instance-independent $\tilde{O}(T^{1/2})$ regret bound which complements existing instance-dependent bounds for the same setting. Finally, we provide applications of our framework to some economic problems of practical relevance.
Sequential Information Design: Learning to Persuade in the Dark
Sep 08, 2022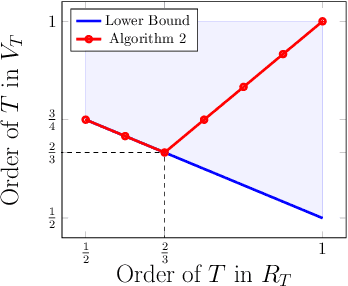
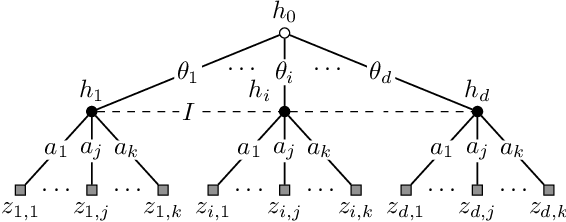
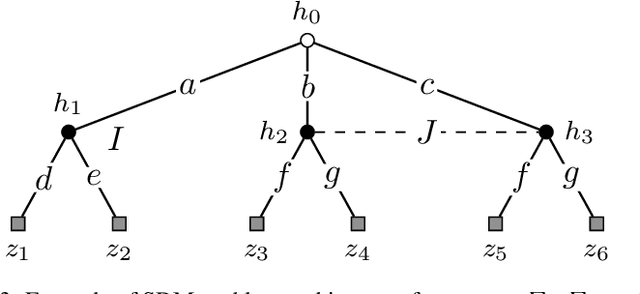
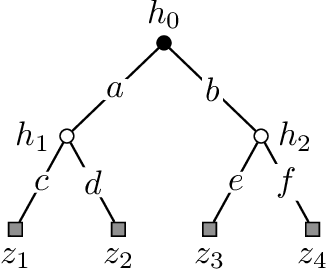
We study a repeated information design problem faced by an informed sender who tries to influence the behavior of a self-interested receiver. We consider settings where the receiver faces a sequential decision making (SDM) problem. At each round, the sender observes the realizations of random events in the SDM problem. This begets the challenge of how to incrementally disclose such information to the receiver to persuade them to follow (desirable) action recommendations. We study the case in which the sender does not know random events probabilities, and, thus, they have to gradually learn them while persuading the receiver. We start by providing a non-trivial polytopal approximation of the set of sender's persuasive information structures. This is crucial to design efficient learning algorithms. Next, we prove a negative result: no learning algorithm can be persuasive. Thus, we relax persuasiveness requirements by focusing on algorithms that guarantee that the receiver's regret in following recommendations grows sub-linearly. In the full-feedback setting -- where the sender observes all random events realizations -- , we provide an algorithm with $\tilde{O}(\sqrt{T})$ regret for both the sender and the receiver. Instead, in the bandit-feedback setting -- where the sender only observes the realizations of random events actually occurring in the SDM problem -- , we design an algorithm that, given an $\alpha \in [1/2, 1]$ as input, ensures $\tilde{O}({T^\alpha})$ and $\tilde{O}( T^{\max \{ \alpha, 1-\frac{\alpha}{2} \} })$ regrets, for the sender and the receiver respectively. This result is complemented by a lower bound showing that such a regrets trade-off is essentially tight.