 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Information Design: Learning to Persuade in the Dark
Sep 08, 2022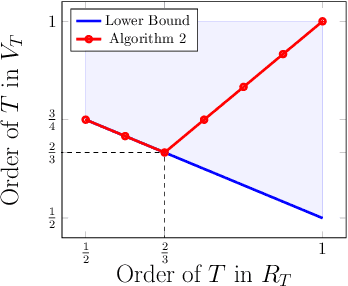
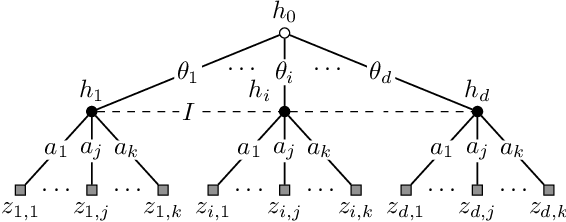
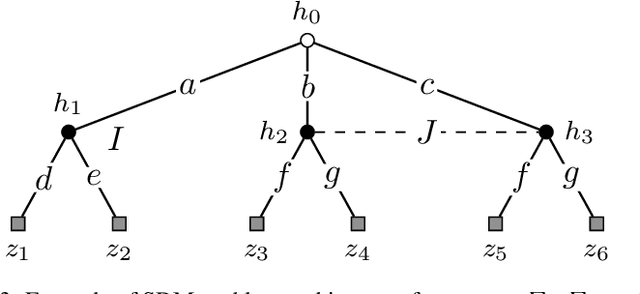
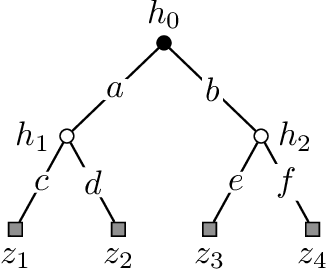
We study a repeated information design problem faced by an informed sender who tries to influence the behavior of a self-interested receiver. We consider settings where the receiver faces a sequential decision making (SDM) problem. At each round, the sender observes the realizations of random events in the SDM problem. This begets the challenge of how to incrementally disclose such information to the receiver to persuade them to follow (desirable) action recommendations. We study the case in which the sender does not know random events probabilities, and, thus, they have to gradually learn them while persuading the receiver. We start by providing a non-trivial polytopal approximation of the set of sender's persuasive information structures. This is crucial to design efficient learning algorithms. Next, we prove a negative result: no learning algorithm can be persuasive. Thus, we relax persuasiveness requirements by focusing on algorithms that guarantee that the receiver's regret in following recommendations grows sub-linearly. In the full-feedback setting -- where the sender observes all random events realizations -- , we provide an algorithm with $\tilde{O}(\sqrt{T})$ regret for both the sender and the receiver. Instead, in the bandit-feedback setting -- where the sender only observes the realizations of random events actually occurring in the SDM problem -- , we design an algorithm that, given an $\alpha \in [1/2, 1]$ as input, ensures $\tilde{O}({T^\alpha})$ and $\tilde{O}( T^{\max \{ \alpha, 1-\frac{\alpha}{2} \} })$ regrets, for the sender and the receiver respectively. This result is complemented by a lower bound showing that such a regrets trade-off is essentially tight.