 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Regret is not enough! Bandits with General Constraints through Adaptive Regret Minimization
Paper and Code
May 10, 2024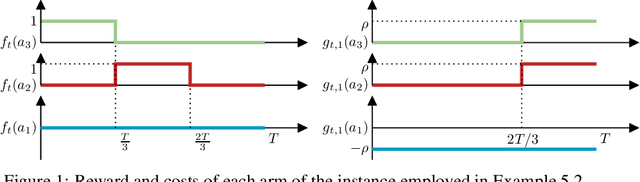
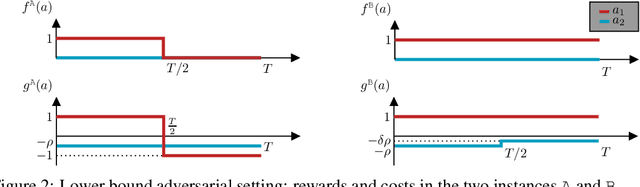
In the bandits with knapsacks framework (BwK) the learner has $m$ resource-consumption (packing) constraints. We focus on the generalization of BwK in which the learner has a set of general long-term constraints. The goal of the learner is to maximize their cumulative reward, while at the same time achieving small cumulative constraints violations. In this scenario, there exist simple instances where conventional methods for BwK fail to yield sublinear violations of constraints. We show that it is possible to circumvent this issue by requiring the primal and dual algorithm to be weakly adaptive. Indeed, even in absence on any information on the Slater's parameter $\rho$ characterizing the problem, the interplay between weakly adaptive primal and dual regret minimizers yields a "self-bounding" property of dual variables. In particular, their norm remains suitably upper bounded across the entire time horizon even without explicit projection steps. By exploiting this property, we provide best-of-both-worlds guarantees for stochastic and adversarial inputs. In the first case, we show that the algorithm guarantees sublinear regret. In the latter case, we establish a tight competitive ratio of $\rho/(1+\rho)$. In both settings, constraints violations are guaranteed to be sublinear in time. Finally, this results allow us to obtain new result for the problem of contextual bandits with linear constraints, providing the first no-$\alpha$-regret guarantees for adversarial contexts.