 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management: A Research Manifesto
Mar 19, 2026This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
On the Convergence of Multicalibration Gradient Boosting
Feb 06, 2026Multicalibration gradient boosting has recently emerged as a scalable method that empirically produces approximately multicalibrated predictors and has been deployed at web scale. Despite this empirical success, its convergence properties are not well understood. In this paper, we bridge the gap by providing convergence guarantees for multicalibration gradient boosting in regression with squared-error loss. We show that the magnitude of successive prediction updates decays at $O(1/\sqrt{T})$, which implies the same convergence rate bound for the multicalibration error over rounds. Under additional smoothness assumptions on the weak learners, this rate improves to linear convergence. We further analyze adaptive variants, showing local quadratic convergence of the training loss, and we study rescaling schemes that preserve convergence. Experiments on real-world datasets support our theory and clarify the regimes in which the method achieves fast convergence and strong multicalibration.
Multicalibration yields better matchings
Nov 14, 2025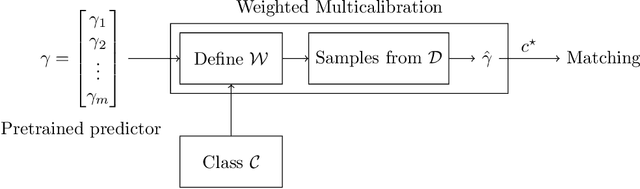
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
Measuring multi-calibration
Jun 12, 2025A suitable scalar metric can help measure multi-calibration, defined as follows. When the expected values of observed responses are equal to corresponding predicted probabilities, the probabilistic predictions are known as "perfectly calibrated." When the predicted probabilities are perfectly calibrated simultaneously across several subpopulations, the probabilistic predictions are known as "perfectly multi-calibrated." In practice, predicted probabilities are seldom perfectly multi-calibrated, so a statistic measuring the distance from perfect multi-calibration is informative. A recently proposed metric for calibration, based on the classical Kuiper statistic, is a natural basis for a new metric of multi-calibration and avoids well-known problems of metrics based on binning or kernel density estimation. The newly proposed metric weights the contributions of different subpopulations in proportion to their signal-to-noise ratios; data analyses' ablations demonstrate that the metric becomes noisy when omitting the signal-to-noise ratios from the metric. Numerical examples on benchmark data sets illustrate the new metric.
Online Learning with Sublinear Best-Action Queries
Jul 23, 2024In online learning, a decision maker repeatedly selects one of a set of actions, with the goal of minimizing the overall loss incurred. Following the recent line of research on algorithms endowed with additional predictive features, we revisit this problem by allowing the decision maker to acquire additional information on the actions to be selected. In particular, we study the power of \emph{best-action queries}, which reveal beforehand the identity of the best action at a given time step. In practice, predictive features may be expensive, so we allow the decision maker to issue at most $k$ such queries. We establish tight bounds on the performance any algorithm can achieve when given access to $k$ best-action queries for different types of feedback models. In particular, we prove that in the full feedback model, $k$ queries are enough to achieve an optimal regret of $\Theta\left(\min\left\{\sqrt T, \frac Tk\right\}\right)$. This finding highlights the significant multiplicative advantage in the regret rate achievable with even a modest (sublinear) number $k \in \Omega(\sqrt{T})$ of queries. Additionally, we study the challenging setting in which the only available feedback is obtained during the time steps corresponding to the $k$ best-action queries. There, we provide a tight regret rate of $\Theta\left(\min\left\{\frac{T}{\sqrt k},\frac{T^2}{k^2}\right\}\right)$, which improves over the standard $\Theta\left(\frac{T}{\sqrt k}\right)$ regret rate for label efficient prediction for $k \in \Omega(T^{2/3})$.
On the convergence of loss and uncertainty-based active learning algorithms
Dec 21, 2023We study convergence rates of loss and uncertainty-based active learning algorithms under various assumptions. First, we provide a set of conditions under which a convergence rate guarantee holds, and use this for linear classifiers and linearly separable datasets to show convergence rate guarantees for loss-based sampling and different loss functions. Second, we provide a framework that allows us to derive convergence rate bounds for loss-based sampling by deploying known convergence rate bounds for stochastic gradient descent algorithms. Third, and last, we propose an active learning algorithm that combines sampling of points and stochastic Polyak's step size. We show a condition on the sampling that ensures a convergence rate guarantee for this algorithm for smooth convex loss functions. Our numerical results demonstrate efficiency of our proposed algorithm.
Active learning with biased non-response to label requests
Dec 13, 2023Active learning can improve the efficiency of training prediction models by identifying the most informative new labels to acquire. However, non-response to label requests can impact active learning's effectiveness in real-world contexts. We conceptualise this degradation by considering the type of non-response present in the data, demonstrating that biased non-response is particularly detrimental to model performance. We argue that this sort of non-response is particularly likely in contexts where the labelling process, by nature, relies on user interactions. To mitigate the impact of biased non-response, we propose a cost-based correction to the sampling strategy--the Upper Confidence Bound of the Expected Utility (UCB-EU)--that can, plausibly, be applied to any active learning algorithm. Through experiments, we demonstrate that our method successfully reduces the harm from labelling non-response in many settings. However, we also characterise settings where the non-response bias in the annotations remains detrimental under UCB-EU for particular sampling methods and data generating processes. Finally, we evaluate our method on a real-world dataset from e-commerce platform Taobao. We show that UCB-EU yields substantial performance improvements to conversion models that are trained on clicked impressions. Most generally, this research serves to both better conceptualise the interplay between types of non-response and model improvements via active learning, and to provide a practical, easy to implement correction that helps mitigate model degradation.
TCE: A Test-Based Approach to Measuring Calibration Error
Jun 25, 2023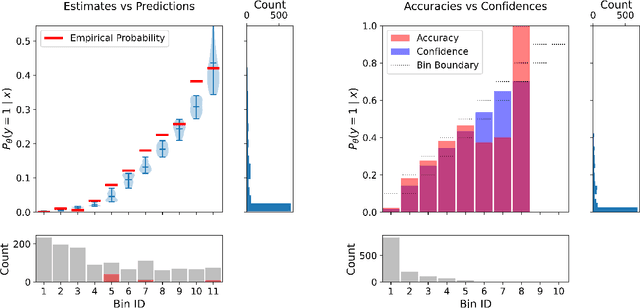

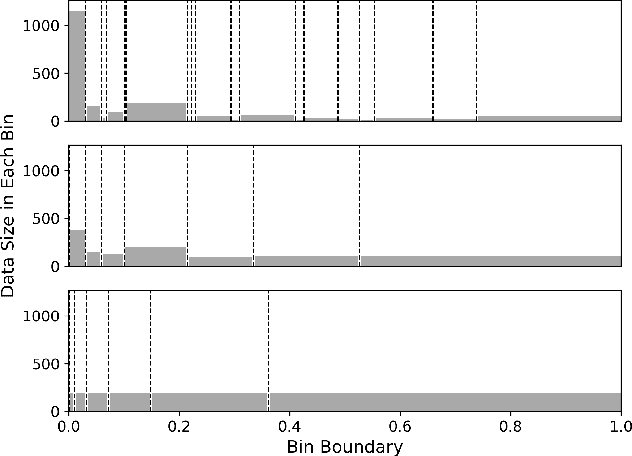
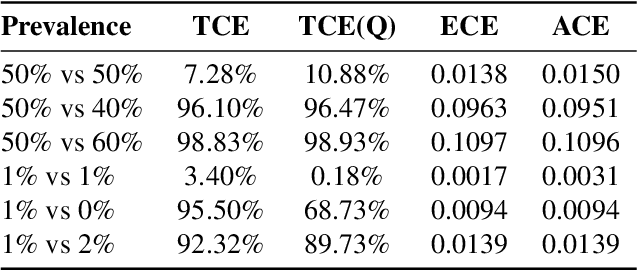
This paper proposes a new metric to measure the calibration error of probabilistic binary classifiers, called test-based calibration error (TCE). TCE incorporates a novel loss function based on a statistical test to examine the extent to which model predictions differ from probabilities estimated from data. It offers (i) a clear interpretation, (ii) a consistent scale that is unaffected by class imbalance, and (iii) an enhanced visual representation with repect to the standard reliability diagram. In addition, we introduce an optimality criterion for the binning procedure of calibration error metrics based on a minimal estimation error of the empirical probabilities. We provide a novel computational algorithm for optimal bins under bin-size constraints. We demonstrate properties of TCE through a range of experiments, including multiple real-world imbalanced datasets and ImageNet 1000.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
Jun 09, 2023Researchers in explainable artificial intelligence have developed numerous methods for helping users understand the predictions of complex supervised learning models. By contrast, explaining the $\textit{uncertainty}$ of model outputs has received relatively little attention. We adapt the popular Shapley value framework to explain various types of predictive uncertainty, quantifying each feature's contribution to the conditional entropy of individual model outputs. We consider games with modified characteristic functions and find deep connections between the resulting Shapley values and fundamental quantities from information theory and conditional independence testing. We outline inference procedures for finite sample error rate control with provable guarantees, and implement an efficient algorithm that performs well in a range of experiments on real and simulated data. Our method has applications to covariate shift detection, active learning, feature selection, and active feature-value acquisition.
Machine Learning for Fraud Detection in E-Commerce: A Research Agenda
Jul 05, 2021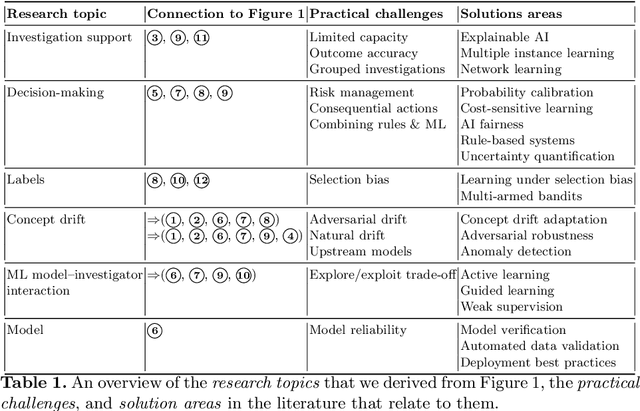
Fraud detection and prevention play an important part in ensuring the sustained operation of any e-commerce business. Machine learning (ML) often plays an important role in these anti-fraud operations, but the organizational context in which these ML models operate cannot be ignored. In this paper, we take an organization-centric view on the topic of fraud detection by formulating an operational model of the anti-fraud departments in e-commerce organizations. We derive 6 research topics and 12 practical challenges for fraud detection from this operational model. We summarize the state of the literature for each research topic, discuss potential solutions to the practical challenges, and identify 22 open research challenges.