 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Treat Business Processes: Prescriptive Process Monitoring with Causal Inference and Reinforcement Learning
Mar 07, 2023Increasing the success rate of a process, i.e. the percentage of cases that end in a positive outcome, is a recurrent process improvement goal. At runtime, there are often certain actions (a.k.a. treatments) that workers may execute to lift the probability that a case ends in a positive outcome. For example, in a loan origination process, a possible treatment is to issue multiple loan offers to increase the probability that the customer takes a loan. Each treatment has a cost. Thus, when defining policies for prescribing treatments to cases, managers need to consider the net gain of the treatments. Also, the effect of a treatment varies over time: treating a case earlier may be more effective than later in a case. This paper presents a prescriptive monitoring method that automates this decision-making task. The method combines causal inference and reinforcement learning to learn treatment policies that maximize the net gain. The method leverages a conformal prediction technique to speed up the convergence of the reinforcement learning mechanism by separating cases that are likely to end up in a positive or negative outcome, from uncertain cases. An evaluation on two real-life datasets shows that the proposed method outperforms a state-of-the-art baseline.
Prescriptive Process Monitoring for Cost-Aware Cycle Time Reduction
May 15, 2021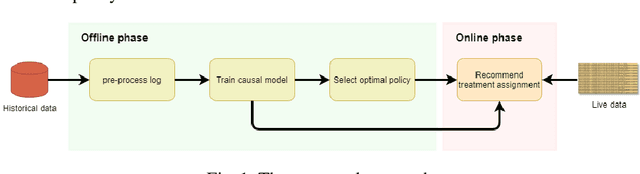


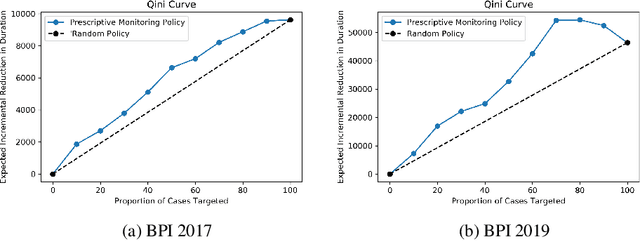
Reducing cycle time is a recurrent concern in the field of business process management. Depending on the process, various interventions may be triggered to reduce the cycle time of a case, for example, using a faster shipping service in an order-to-delivery process or giving a phone call to a customer to obtain missing information rather than waiting passively. Each of these interventions comes with a cost. This paper tackles the problem of determining if and when to trigger a time-reducing intervention in a way that maximizes the total net gain. The paper proposes a prescriptive process monitoring method that uses orthogonal random forest models to estimate the causal effect of triggering a time-reducing intervention for each ongoing case of a process. Based on this causal effect estimate, the method triggers interventions according to a user-defined policy. The method is evaluated on two real-life logs.
Process Mining Meets Causal Machine Learning: Discovering Causal Rules from Event Logs
Sep 03, 2020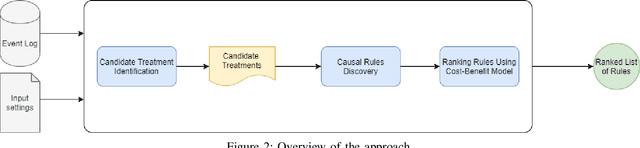
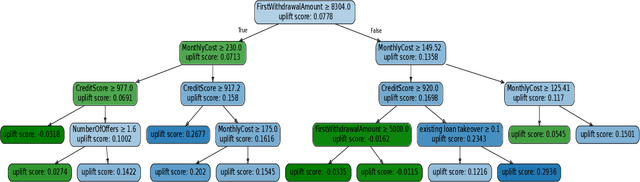
This paper proposes an approach to analyze an event log of a business process in order to generate case-level recommendations of treatments that maximize the probability of a given outcome. Users classify the attributes in the event log into controllable and non-controllable, where the former correspond to attributes that can be altered during an execution of the process (the possible treatments). We use an action rule mining technique to identify treatments that co-occur with the outcome under some conditions. Since action rules are generated based on correlation rather than causation, we then use a causal machine learning technique, specifically uplift trees, to discover subgroups of cases for which a treatment has a high causal effect on the outcome after adjusting for confounding variables. We test the relevance of this approach using an event log of a loan application process and compare our findings with recommendations manually produced by process mining experts.
Fire Now, Fire Later: Alarm-Based Systems for Prescriptive Process Monitoring
May 23, 2019


Predictive process monitoring is a family of techniques to analyze events produced during the execution of a business process in order to predict the future state or the final outcome of running process instances. Existing techniques in this field are able to predict, at each step of a process instance, the likelihood that it will lead to an undesired outcome.These techniques, however, focus on generating predictions and do not prescribe when and how process workers should intervene to decrease the cost of undesired outcomes. This paper proposes a framework for prescriptive process monitoring, which extends predictive monitoring with the ability to generate alarms that trigger interventions to prevent an undesired outcome or mitigate its effect. The framework incorporates a parameterized cost model to assess the cost-benefit trade-off of generating alarms. We show how to optimize the generation of alarms given an event log of past process executions and a set of cost model parameters. The proposed approaches are empirically evaluated using a range of real-life event logs. The experimental results show that the net cost of undesired outcomes can be minimized by changing the threshold for generating alarms, as the process instance progresses. Moreover, introducing delays for triggering alarms, instead of triggering them as soon as the probability of an undesired outcome exceeds a threshold, leads to lower net costs.
An Interdisciplinary Comparison of Sequence Modeling Methods for Next-Element Prediction
Oct 31, 2018
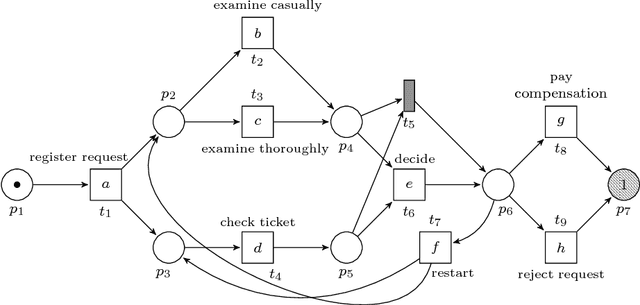

Data of sequential nature arise in many application domains in forms of, e.g. textual data, DNA sequences, and software execution traces. Different research disciplines have developed methods to learn sequence models from such datasets: (i) in the machine learning field methods such as (hidden) Markov models and recurrent neural networks have been developed and successfully applied to a wide-range of tasks, (ii) in process mining process discovery techniques aim to generate human-interpretable descriptive models, and (iii) in the grammar inference field the focus is on finding descriptive models in the form of formal grammars. Despite their different focuses, these fields share a common goal - learning a model that accurately describes the behavior in the underlying data. Those sequence models are generative, i.e, they can predict what elements are likely to occur after a given unfinished sequence. So far, these fields have developed mainly in isolation from each other and no comparison exists. This paper presents an interdisciplinary experimental evaluation that compares sequence modeling techniques on the task of next-element prediction on four real-life sequence datasets. The results indicate that machine learning techniques that generally have no aim at interpretability in terms of accuracy outperform techniques from the process mining and grammar inference fields that aim to yield interpretable models.
Outcome-Oriented Predictive Process Monitoring: Review and Benchmark
Oct 23, 2018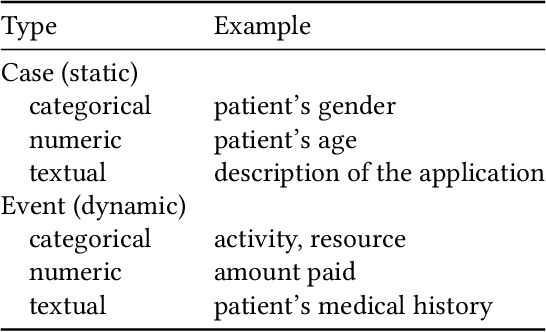

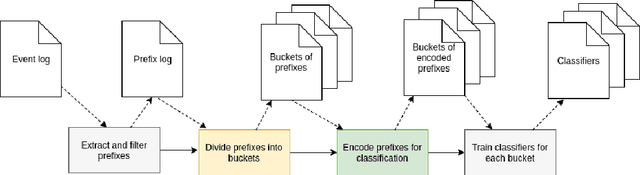
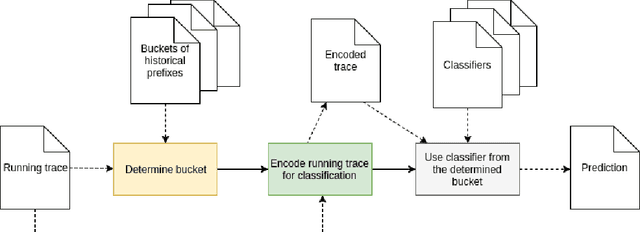
Predictive business process monitoring refers to the act of making predictions about the future state of ongoing cases of a business process, based on their incomplete execution traces and logs of historical (completed) traces. Motivated by the increasingly pervasive availability of fine-grained event data about business process executions, the problem of predictive process monitoring has received substantial attention in the past years. In particular, a considerable number of methods have been put forward to address the problem of outcome-oriented predictive process monitoring, which refers to classifying each ongoing case of a process according to a given set of possible categorical outcomes - e.g., Will the customer complain or not? Will an order be delivered, canceled or withdrawn? Unfortunately, different authors have used different datasets, experimental settings, evaluation measures and baselines to assess their proposals, resulting in poor comparability and an unclear picture of the relative merits and applicability of different methods. To address this gap, this article presents a systematic review and taxonomy of outcome-oriented predictive process monitoring methods, and a comparative experimental evaluation of eleven representative methods using a benchmark covering 24 predictive process monitoring tasks based on nine real-life event logs.
Alarm-Based Prescriptive Process Monitoring
Jun 19, 2018
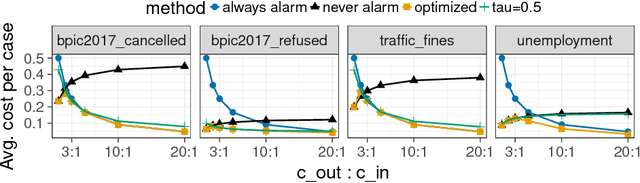
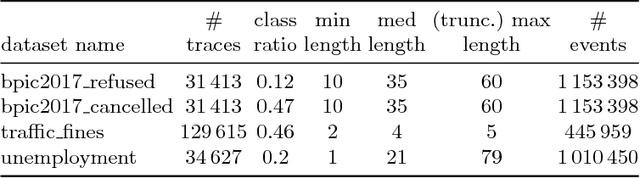
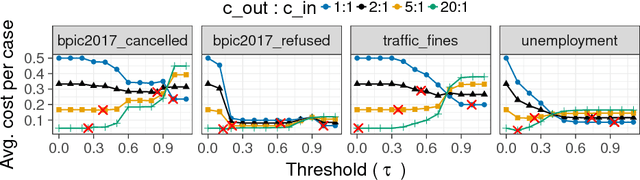
Predictive process monitoring is concerned with the analysis of events produced during the execution of a process in order to predict the future state of ongoing cases thereof. Existing techniques in this field are able to predict, at each step of a case, the likelihood that the case will end up in an undesired outcome. These techniques, however, do not take into account what process workers may do with the generated predictions in order to decrease the likelihood of undesired outcomes. This paper proposes a framework for prescriptive process monitoring, which extends predictive process monitoring approaches with the concepts of alarms, interventions, compensations, and mitigation effects. The framework incorporates a parameterized cost model to assess the cost-benefit tradeoffs of applying prescriptive process monitoring in a given setting. The paper also outlines an approach to optimize the generation of alarms given a dataset and a set of cost model parameters. The proposed approach is empirically evaluated using a range of real-life event logs.
Temporal Stability in Predictive Process Monitoring
Jun 15, 2018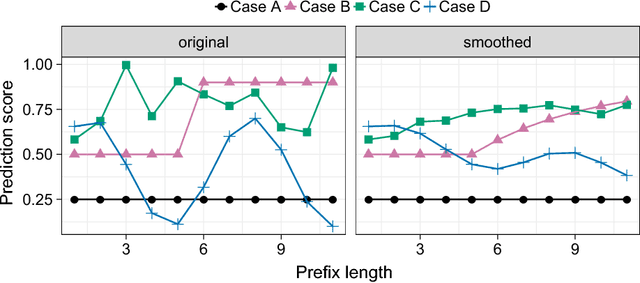

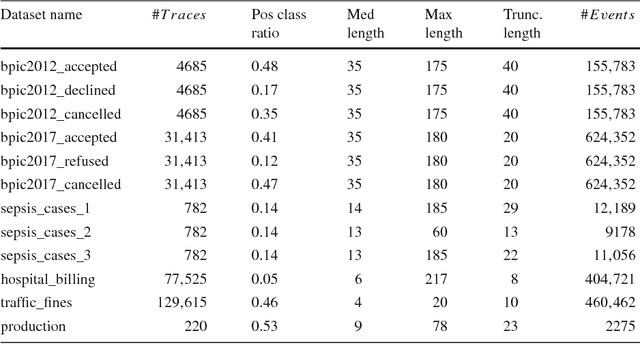
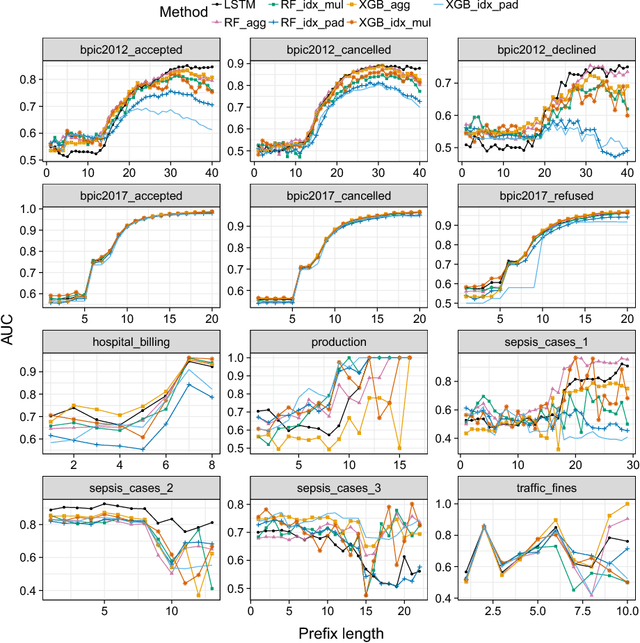
Predictive process monitoring is concerned with the analysis of events produced during the execution of a business process in order to predict as early as possible the final outcome of an ongoing case. Traditionally, predictive process monitoring methods are optimized with respect to accuracy. However, in environments where users make decisions and take actions in response to the predictions they receive, it is equally important to optimize the stability of the successive predictions made for each case. To this end, this paper defines a notion of temporal stability for binary classification tasks in predictive process monitoring and evaluates existing methods with respect to both temporal stability and accuracy. We find that methods based on XGBoost and LSTM neural networks exhibit the highest temporal stability. We then show that temporal stability can be enhanced by hyperparameter-optimizing random forests and XGBoost classifiers with respect to inter-run stability. Finally, we show that time series smoothing techniques can further enhance temporal stability at the expense of slightly lower accuracy.
Survey and cross-benchmark comparison of remaining time prediction methods in business process monitoring
May 10, 2018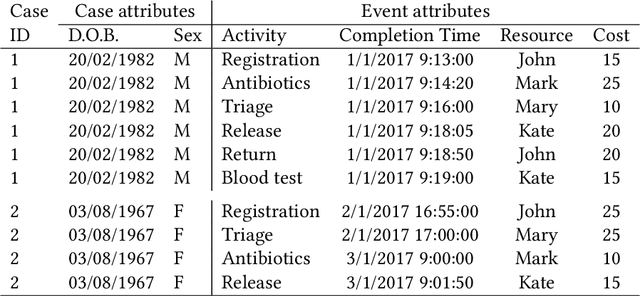

Predictive business process monitoring methods exploit historical process execution logs to generate predictions about running instances (called cases) of a business process, such as the prediction of the outcome, next activity or remaining cycle time of a given process case. These insights could be used to support operational managers in taking remedial actions as business processes unfold, e.g. shifting resources from one case onto another to ensure this latter is completed on time. A number of methods to tackle the remaining cycle time prediction problem have been proposed in the literature. However, due to differences in their experimental setup, choice of datasets, evaluation measures and baselines, the relative merits of each method remain unclear. This article presents a systematic literature review and taxonomy of methods for remaining time prediction in the context of business processes, as well as a cross-benchmark comparison of 16 such methods based on 16 real-life datasets originating from different industry domains.