 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Treat Business Processes: Prescriptive Process Monitoring with Causal Inference and Reinforcement Learning
Mar 07, 2023



Increasing the success rate of a process, i.e. the percentage of cases that end in a positive outcome, is a recurrent process improvement goal. At runtime, there are often certain actions (a.k.a. treatments) that workers may execute to lift the probability that a case ends in a positive outcome. For example, in a loan origination process, a possible treatment is to issue multiple loan offers to increase the probability that the customer takes a loan. Each treatment has a cost. Thus, when defining policies for prescribing treatments to cases, managers need to consider the net gain of the treatments. Also, the effect of a treatment varies over time: treating a case earlier may be more effective than later in a case. This paper presents a prescriptive monitoring method that automates this decision-making task. The method combines causal inference and reinforcement learning to learn treatment policies that maximize the net gain. The method leverages a conformal prediction technique to speed up the convergence of the reinforcement learning mechanism by separating cases that are likely to end up in a positive or negative outcome, from uncertain cases. An evaluation on two real-life datasets shows that the proposed method outperforms a state-of-the-art baseline.
Generalization in Automated Process Discovery: A Framework based on Event Log Patterns
Mar 26, 2022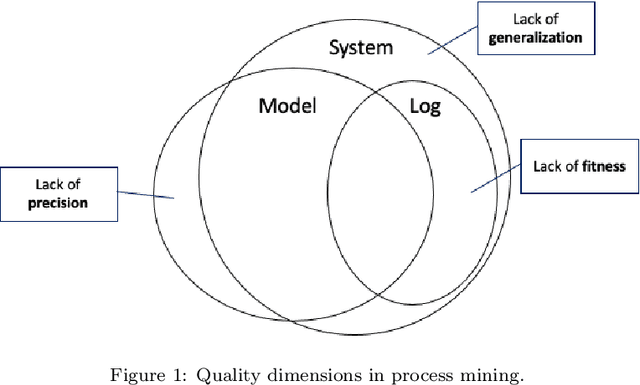



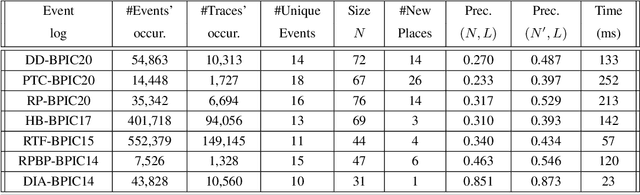
The importance of quality measures in process mining has increased. One of the key quality aspects, generalization, is concerned with measuring the degree of overfitting of a process model w.r.t. an event log, since the recorded behavior is just an example of the true behavior of the underlying business process. Existing generalization measures exhibit several shortcomings that severely hinder their applicability in practice. For example, they assume the event log fully fits the discovered process model, and cannot deal with large real-life event logs and complex process models. More significantly, current measures neglect generalizations for clear patterns that demand a certain construct in the model. For example, a repeating sequence in an event log should be generalized with a loop structure in the model. We address these shortcomings by proposing a framework of measures that generalize a set of patterns discovered from an event log with representative traces and check the corresponding control-flow structures in the process model via their trace alignment. We instantiate the framework with a generalization measure that uses tandem repeats to identify repetitive patterns that are compared to the loop structures and a concurrency oracle to identify concurrent patterns that are compared to the parallel structures of the process model. In an extensive qualitative and quantitative evaluation using 74 log-model pairs using against two baseline generalization measures, we show that the proposed generalization measure consistently ranks process models that fulfil the observed patterns with generalizing control-flow structures higher than those which do not, while the baseline measures disregard those patterns. Further, we show that our measure can be efficiently computed for datasets two orders of magnitude larger than the largest dataset the baseline generalization measures can handle.
Augmented Business Process Management Systems: A Research Manifesto
Feb 03, 2022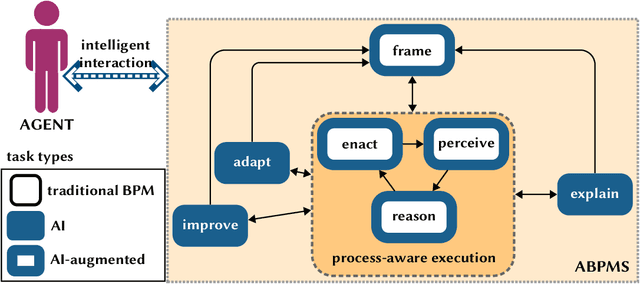
Augmented Business Process Management Systems (ABPMSs) are an emerging class of process-aware information systems that draws upon trustworthy AI technology. An ABPMS enhances the execution of business processes with the aim of making these processes more adaptable, proactive, explainable, and context-sensitive. This manifesto presents a vision for ABPMSs and discusses research challenges that need to be surmounted to realize this vision. To this end, we define the concept of ABPMS, we outline the lifecycle of processes within an ABPMS, we discuss core characteristics of an ABPMS, and we derive a set of challenges to realize systems with these characteristics.
Automated Repair of Process Models with Non-Local Constraints Using State-Based Region Theory
Jun 26, 2021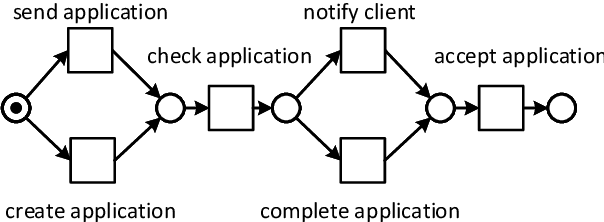
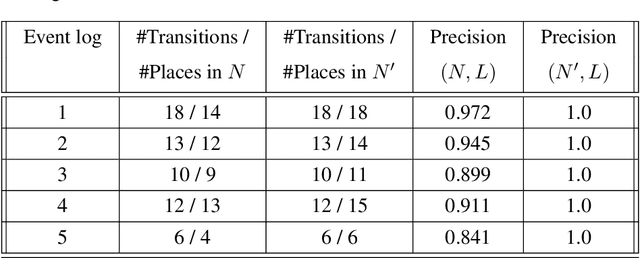
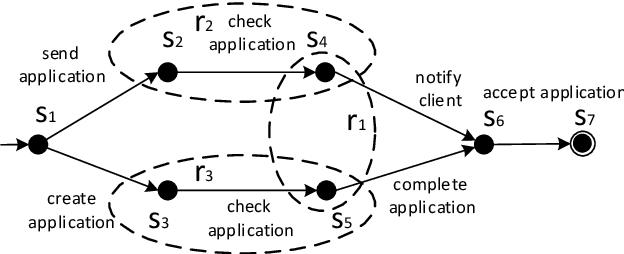
State-of-the-art process discovery methods construct free-choice process models from event logs. Consequently, the constructed models do not take into account indirect dependencies between events. Whenever the input behaviour is not free-choice, these methods fail to provide a precise model. In this paper, we propose a novel approach for enhancing free-choice process models by adding non-free-choice constructs discovered a-posteriori via region-based techniques. This allows us to benefit from the performance of existing process discovery methods and the accuracy of the employed fundamental synthesis techniques. We prove that the proposed approach preserves fitness with respect to the event log while improving the precision when indirect dependencies exist. The approach has been implemented and tested on both synthetic and real-life datasets. The results show its effectiveness in repairing models discovered from event logs.
Prescriptive Process Monitoring for Cost-Aware Cycle Time Reduction
May 15, 2021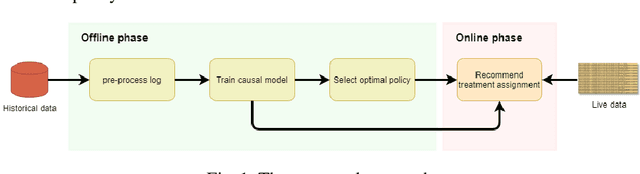


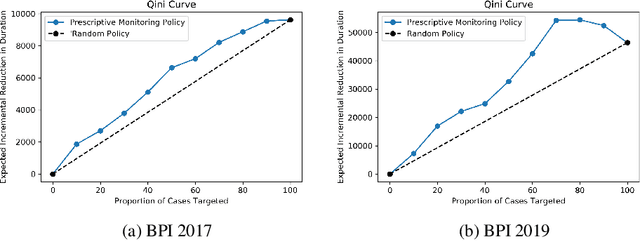
Reducing cycle time is a recurrent concern in the field of business process management. Depending on the process, various interventions may be triggered to reduce the cycle time of a case, for example, using a faster shipping service in an order-to-delivery process or giving a phone call to a customer to obtain missing information rather than waiting passively. Each of these interventions comes with a cost. This paper tackles the problem of determining if and when to trigger a time-reducing intervention in a way that maximizes the total net gain. The paper proposes a prescriptive process monitoring method that uses orthogonal random forest models to estimate the causal effect of triggering a time-reducing intervention for each ongoing case of a process. Based on this causal effect estimate, the method triggers interventions according to a user-defined policy. The method is evaluated on two real-life logs.
A Deep Adversarial Model for Suffix and Remaining Time Prediction of Event Sequences
Feb 15, 2021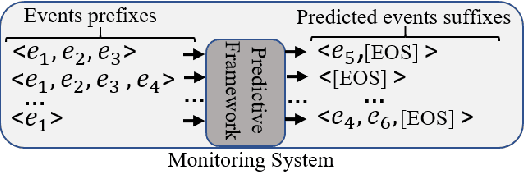


Event suffix and remaining time prediction are sequence to sequence learning tasks. They have wide applications in different areas such as economics, digital health, business process management and IT infrastructure monitoring. Timestamped event sequences contain ordered events which carry at least two attributes: the event's label and its timestamp. Suffix and remaining time prediction are about obtaining the most likely continuation of event labels and the remaining time until the sequence finishes, respectively. Recent deep learning-based works for such predictions are prone to potentially large prediction errors because of closed-loop training (i.e., the next event is conditioned on the ground truth of previous events) and open-loop inference (i.e., the next event is conditioned on previously predicted events). In this work, we propose an encoder-decoder architecture for open-loop training to advance the suffix and remaining time prediction of event sequences. To capture the joint temporal dynamics of events, we harness the power of adversarial learning techniques to boost prediction performance. We consider four real-life datasets and three baselines in our experiments. The results show improvements up to four times compared to the state of the art in suffix and remaining time prediction of event sequences, specifically in the realm of business process executions. We also show that the obtained improvements of adversarial training are superior compared to standard training under the same experimental setup.
Process Mining Meets Causal Machine Learning: Discovering Causal Rules from Event Logs
Sep 03, 2020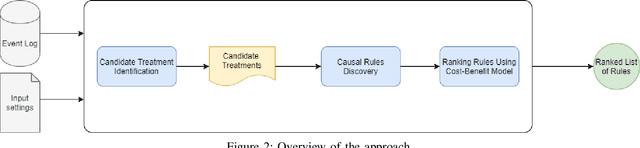
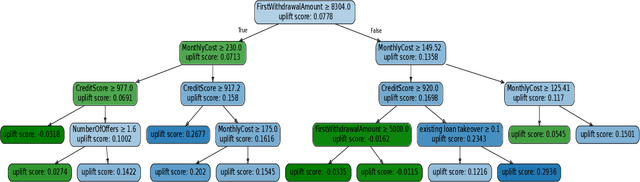
This paper proposes an approach to analyze an event log of a business process in order to generate case-level recommendations of treatments that maximize the probability of a given outcome. Users classify the attributes in the event log into controllable and non-controllable, where the former correspond to attributes that can be altered during an execution of the process (the possible treatments). We use an action rule mining technique to identify treatments that co-occur with the outcome under some conditions. Since action rules are generated based on correlation rather than causation, we then use a causal machine learning technique, specifically uplift trees, to discover subgroups of cases for which a treatment has a high causal effect on the outcome after adjusting for confounding variables. We test the relevance of this approach using an event log of a loan application process and compare our findings with recommendations manually produced by process mining experts.
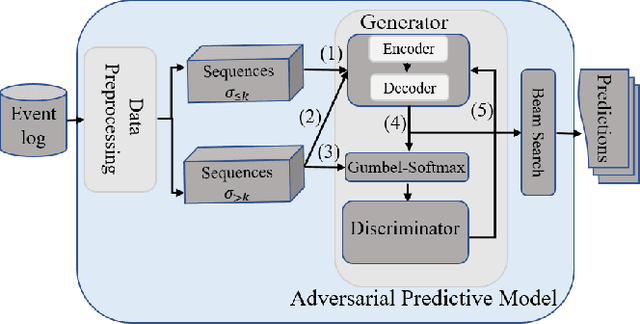
Encoder-Decoder Generative Adversarial Nets for Suffix Generation and Remaining Time Predication of Business Process Models
Jul 30, 2020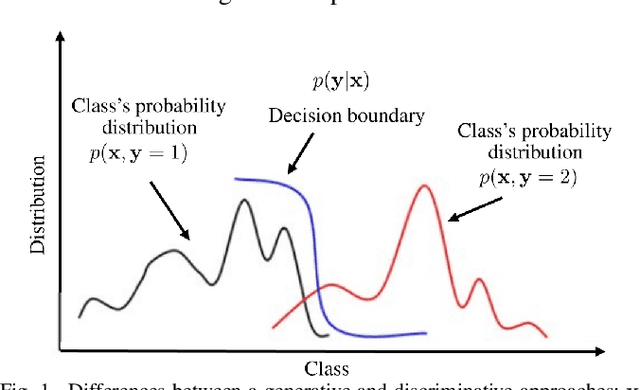
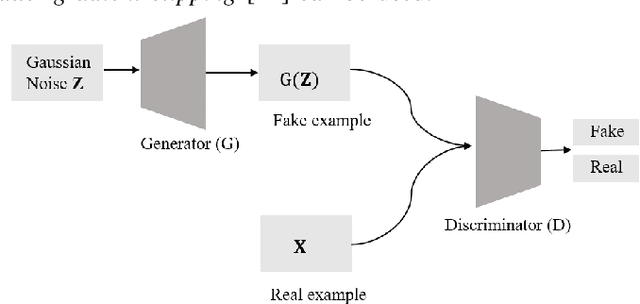
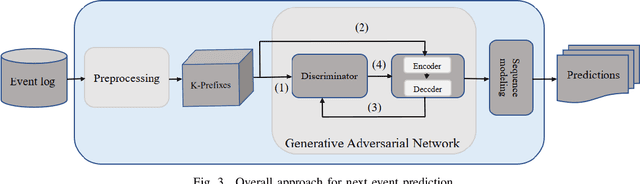
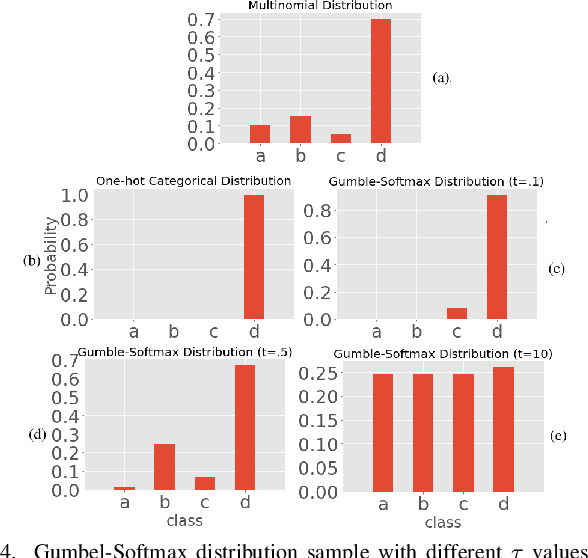
This paper proposes an encoder-decoder architecture grounded on Generative Adversarial Networks (GANs), that generates a sequence of activities and their timestamps in an end-to-end way. GANs work well with differentiable data such as images. However, a suffix is a sequence of categorical items. To this end, we use the Gumbel-Softmax distribution to get a differentiable continuous approximation. The training works by putting one neural network against the other in a two-player game (hence the "adversarial" nature), which leads to generating suffixes close to the ground truth. From the experimental evaluation it emerges that the approach is superior to the baselines in terms of the accuracy of the predicted suffixes and corresponding remaining times, despite using a naive feature encoding and only engineering features based on control flow and events completion time.
Detecting sudden and gradual drifts in business processes from execution traces
May 07, 2020


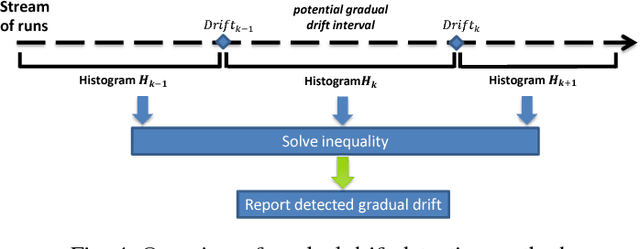
Business processes are prone to unexpected changes, as process workers may suddenly or gradually start executing a process differently in order to adjust to changes in workload, season, or other external factors. Early detection of business process changes enables managers to identify and act upon changes that may otherwise affect process performance. Business process drift detection refers to a family of methods to detect changes in a business process by analyzing event logs extracted from the systems that support the execution of the process. Existing methods for business process drift detection are based on an explorative analysis of a potentially large feature space and in some cases they require users to manually identify specific features that characterize the drift. Depending on the explored feature space, these methods miss various types of changes. Moreover, they are either designed to detect sudden drifts or gradual drifts but not both. This paper proposes an automated and statistically grounded method for detecting sudden and gradual business process drifts under a unified framework. An empirical evaluation shows that the method detects typical change patterns with significantly higher accuracy and lower detection delay than existing methods, while accurately distinguishing between sudden and gradual drifts.
Efficient Conformance Checking using Alignment Computation with Tandem Repeats
Apr 02, 2020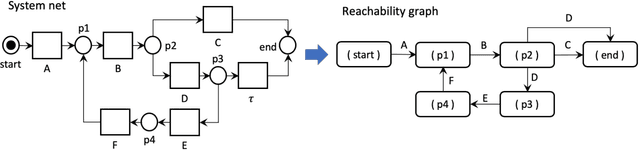
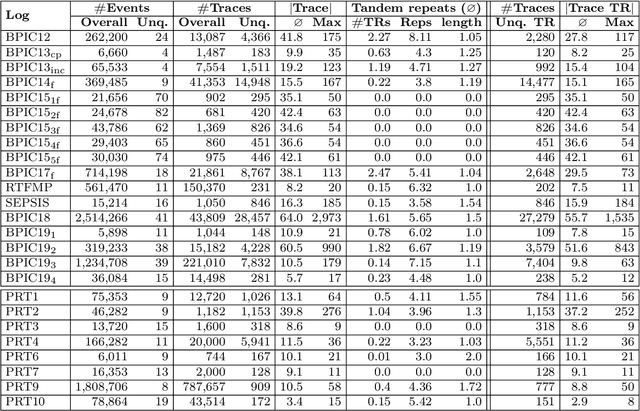

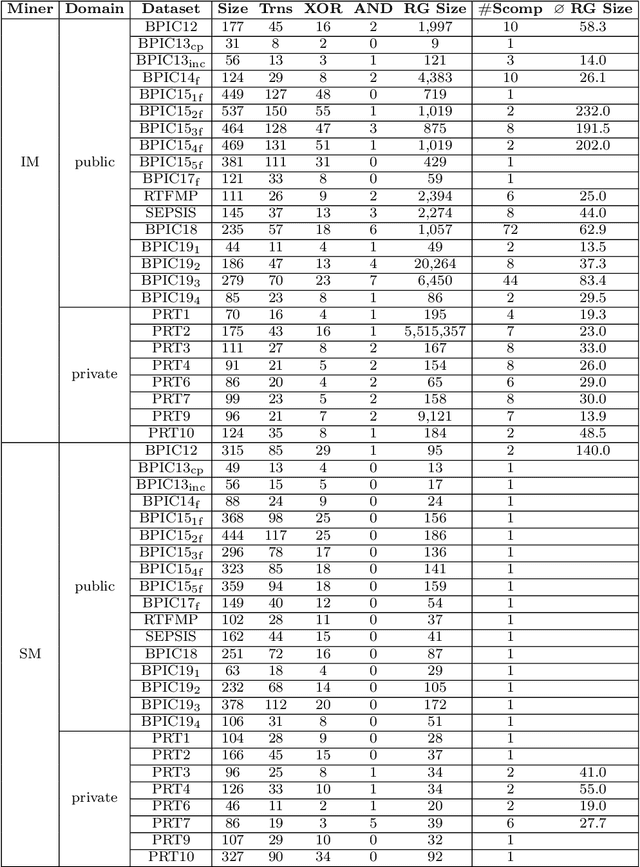
Conformance checking encompasses a body of process mining techniques which aim to find and describe the differences between a process model capturing the expected process behavior and a corresponding event log recording the observed behavior. Alignments are an established technique to compute the distance between a trace in the event log and the closest execution trace of a corresponding process model. Given a cost function, an alignment is optimal when it contains the least number of mismatches between a log trace and a model trace. Determining optimal alignments, however, is computationally expensive, especially in light of the growing size and complexity of event logs from practice, which can easily exceed one million events with traces of several hundred activities. A common limitation of existing alignment techniques is the inability to exploit repetitions in the log. By exploiting a specific form of sequential pattern in traces, namely tandem repeats, we propose a novel technique that uses pre- and post-processing steps to compress the length of a trace and recomputes the alignment cost while guaranteeing that the cost result never under-approximates the optimal cost. In an extensive empirical evaluation with 50 real-life model-log pairs and against five state-of-the-art alignment techniques, we show that the proposed compression approach systematically outperforms the baselines by up to an order of magnitude in the presence of traces with repetitions, and that the cost over-approximation, when it occurs, is negligible.