 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Automated Process Discovery: A Framework based on Event Log Patterns
Mar 26, 2022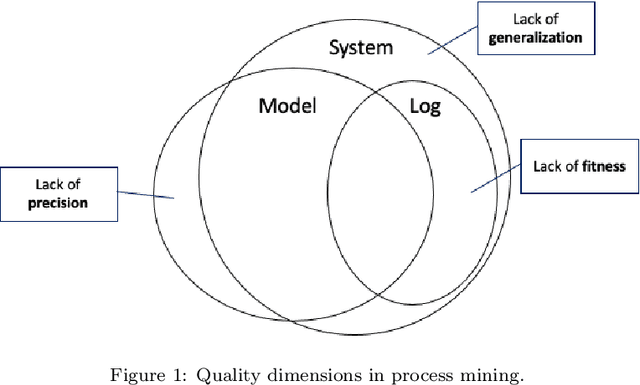



The importance of quality measures in process mining has increased. One of the key quality aspects, generalization, is concerned with measuring the degree of overfitting of a process model w.r.t. an event log, since the recorded behavior is just an example of the true behavior of the underlying business process. Existing generalization measures exhibit several shortcomings that severely hinder their applicability in practice. For example, they assume the event log fully fits the discovered process model, and cannot deal with large real-life event logs and complex process models. More significantly, current measures neglect generalizations for clear patterns that demand a certain construct in the model. For example, a repeating sequence in an event log should be generalized with a loop structure in the model. We address these shortcomings by proposing a framework of measures that generalize a set of patterns discovered from an event log with representative traces and check the corresponding control-flow structures in the process model via their trace alignment. We instantiate the framework with a generalization measure that uses tandem repeats to identify repetitive patterns that are compared to the loop structures and a concurrency oracle to identify concurrent patterns that are compared to the parallel structures of the process model. In an extensive qualitative and quantitative evaluation using 74 log-model pairs using against two baseline generalization measures, we show that the proposed generalization measure consistently ranks process models that fulfil the observed patterns with generalizing control-flow structures higher than those which do not, while the baseline measures disregard those patterns. Further, we show that our measure can be efficiently computed for datasets two orders of magnitude larger than the largest dataset the baseline generalization measures can handle.
Efficient Conformance Checking using Alignment Computation with Tandem Repeats
Apr 02, 2020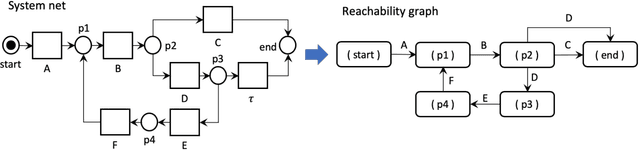
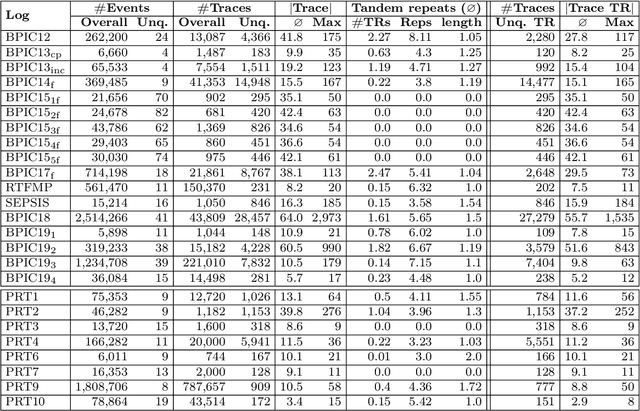

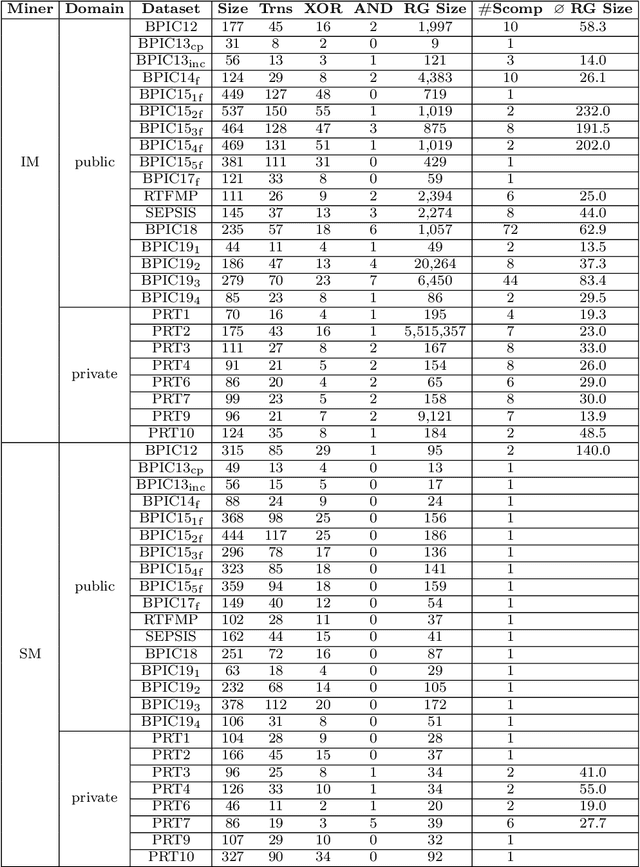
Conformance checking encompasses a body of process mining techniques which aim to find and describe the differences between a process model capturing the expected process behavior and a corresponding event log recording the observed behavior. Alignments are an established technique to compute the distance between a trace in the event log and the closest execution trace of a corresponding process model. Given a cost function, an alignment is optimal when it contains the least number of mismatches between a log trace and a model trace. Determining optimal alignments, however, is computationally expensive, especially in light of the growing size and complexity of event logs from practice, which can easily exceed one million events with traces of several hundred activities. A common limitation of existing alignment techniques is the inability to exploit repetitions in the log. By exploiting a specific form of sequential pattern in traces, namely tandem repeats, we propose a novel technique that uses pre- and post-processing steps to compress the length of a trace and recomputes the alignment cost while guaranteeing that the cost result never under-approximates the optimal cost. In an extensive empirical evaluation with 50 real-life model-log pairs and against five state-of-the-art alignment techniques, we show that the proposed compression approach systematically outperforms the baselines by up to an order of magnitude in the presence of traces with repetitions, and that the cost over-approximation, when it occurs, is negligible.
Discovering Process Maps from Event Streams
Apr 08, 2018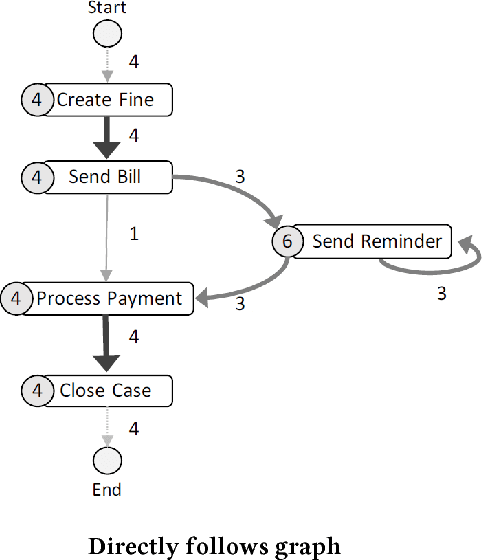

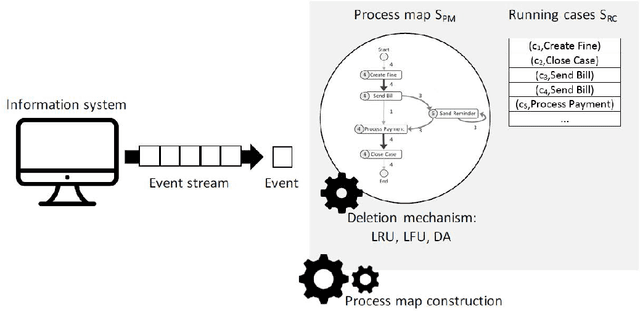
Automated process discovery is a class of process mining methods that allow analysts to extract business process models from event logs. Traditional process discovery methods extract process models from a snapshot of an event log stored in its entirety. In some scenarios, however, events keep coming with a high arrival rate to the extent that it is impractical to store the entire event log and to continuously re-discover a process model from scratch. Such scenarios require online process discovery approaches. Given an event stream produced by the execution of a business process, the goal of an online process discovery method is to maintain a continuously updated model of the process with a bounded amount of memory while at the same time achieving similar accuracy as offline methods. However, existing online discovery approaches require relatively large amounts of memory to achieve levels of accuracy comparable to that of offline methods. Therefore, this paper proposes an approach that addresses this limitation by mapping the problem of online process discovery to that of cache memory management, and applying well-known cache replacement policies to the problem of online process discovery. The approach has been implemented in .NET, experimentally integrated with the Minit process mining tool and comparatively evaluated against an existing baseline using real-life datasets.