 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Process Maps from Event Streams
Paper and Code
Apr 08, 2018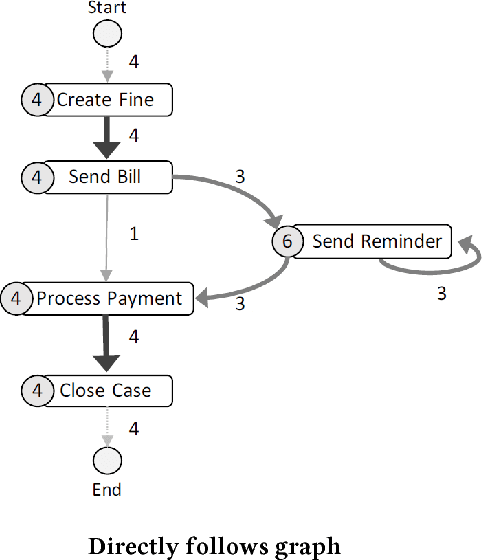

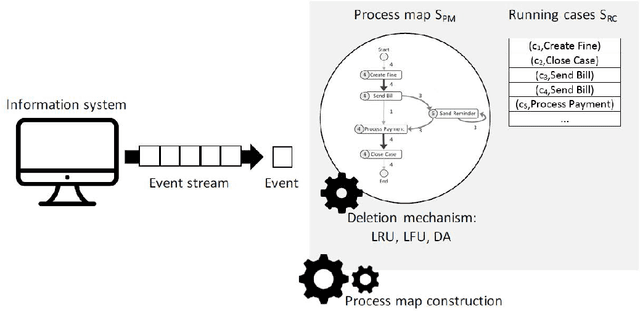
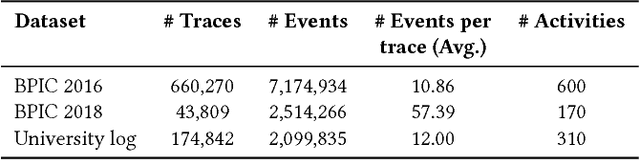
Automated process discovery is a class of process mining methods that allow analysts to extract business process models from event logs. Traditional process discovery methods extract process models from a snapshot of an event log stored in its entirety. In some scenarios, however, events keep coming with a high arrival rate to the extent that it is impractical to store the entire event log and to continuously re-discover a process model from scratch. Such scenarios require online process discovery approaches. Given an event stream produced by the execution of a business process, the goal of an online process discovery method is to maintain a continuously updated model of the process with a bounded amount of memory while at the same time achieving similar accuracy as offline methods. However, existing online discovery approaches require relatively large amounts of memory to achieve levels of accuracy comparable to that of offline methods. Therefore, this paper proposes an approach that addresses this limitation by mapping the problem of online process discovery to that of cache memory management, and applying well-known cache replacement policies to the problem of online process discovery. The approach has been implemented in .NET, experimentally integrated with the Minit process mining tool and comparatively evaluated against an existing baseline using real-life datasets.