 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management Systems
Jan 25, 2026Since the early 90s, the evolution of the Business Process Management (BPM) discipline has been punctuated by successive waves of automation technologies. Some of these technologies enable the automation of individual tasks, while others focus on orchestrating the execution of end-to-end processes. The rise of Generative and Agentic Artificial Intelligence (AI) is opening the way for another such wave. However, this wave is poised to be different because it shifts the focus from automation to autonomy and from design-driven management of business processes to data-driven management, leveraging process mining techniques. This position paper, based on a keynote talk at the 2025 Workshop on AI for BPM, outlines how process mining has laid the foundations on top of which agents can sense process states, reason about improvement opportunities, and act to maintain and optimize performance. The paper proposes an architectural vision for Agentic Business Process Management Systems (A-BPMS): a new class of platforms that integrate autonomy, reasoning, and learning into process management and execution. The paper contends that such systems must support a continuum of processes, spanning from human-driven to fully autonomous, thus redefining the boundaries of process automation and governance.
Exploring LLM Features in Predictive Process Monitoring for Small-Scale Event-Logs
Jan 16, 2026Predictive Process Monitoring is a branch of process mining that aims to predict the outcome of an ongoing process. Recently, it leveraged machine-and-deep learning architectures. In this paper, we extend our prior LLM-based Predictive Process Monitoring framework, which was initially focused on total time prediction via prompting. The extension consists of comprehensively evaluating its generality, semantic leverage, and reasoning mechanisms, also across multiple Key Performance Indicators. Empirical evaluations conducted on three distinct event logs and across the Key Performance Indicators of Total Time and Activity Occurrence prediction indicate that, in data-scarce settings with only 100 traces, the LLM surpasses the benchmark methods. Furthermore, the experiments also show that the LLM exploits both its embodied prior knowledge and the internal correlations among training traces. Finally, we examine the reasoning strategies employed by the model, demonstrating that the LLM does not merely replicate existing predictive methods but performs higher-order reasoning to generate the predictions.
Predicting Case Suffixes With Activity Start and End Times: A Sweep-Line Based Approach
Sep 18, 2025Predictive process monitoring techniques support the operational decision making by predicting future states of ongoing cases of a business process. A subset of these techniques predict the remaining sequence of activities of an ongoing case (case suffix prediction). Existing approaches for case suffix prediction generate sequences of activities with a single timestamp (e.g. the end timestamp). This output is insufficient for resource capacity planning, where we need to reason about the periods of time when resources will be busy performing work. This paper introduces a technique for predicting case suffixes consisting of activities with start and end timestamps. In other words, the proposed technique predicts both the waiting time and the processing time of each activity. Since the waiting time of an activity in a case depends on how busy resources are in other cases, the technique adopts a sweep-line approach, wherein the suffixes of all ongoing cases in the process are predicted in lockstep, rather than predictions being made for each case in isolation. An evaluation on real-life and synthetic datasets compares the accuracy of different instantiations of this approach, demonstrating the advantages of a multi-model approach to case suffix prediction.
Business Process Simulation: Probabilistic Modeling of Intermittent Resource Availability and Multitasking Behavior
Oct 22, 2024In business process simulation, resource availability is typically modeled by assigning a calendar to each resource, e.g., Monday-Friday, 9:00-18:00. Resources are assumed to be always available during each time slot in their availability calendar. This assumption often becomes invalid due to interruptions, breaks, or time-sharing across processes. In other words, existing approaches fail to capture intermittent availability. Another limitation of existing approaches is that they either do not consider multitasking behavior, or if they do, they assume that resources always multitask (up to a maximum capacity) whenever available. However, studies have shown that the multitasking patterns vary across days. This paper introduces a probabilistic approach to model resource availability and multitasking behavior for business process simulation. In this approach, each time slot in a resource calendar has an associated availability probability and a multitasking probability per multitasking level. For example, a resource may be available on Fridays between 14:00-15:00 with 90\% probability, and given that they are performing one task during this slot, they may take on a second concurrent task with 60\% probability. We propose algorithms to discover probabilistic calendars and probabilistic multitasking capacities from event logs. An evaluation shows that, with these enhancements, simulation models discovered from event logs better replicate the distribution of activities and cycle times, relative to approaches with crisp calendars and monotasking assumptions.
Discovery and Simulation of Data-Aware Business Processes
Aug 24, 2024Simulation is a common approach to predict the effect of business process changes on quantitative performance. The starting point of Business Process Simulation (BPS) is a process model enriched with simulation parameters. To cope with the typically large parameter spaces of BPS models, several methods have been proposed to automatically discover BPS models from event logs. Virtually all these approaches neglect the data perspective of business processes. Yet, the data attributes manipulated by a business process often determine which activities are performed, how many times, and when. This paper addresses this gap by introducing a data-aware BPS modeling approach and a method to discover data-aware BPS models from event logs. The BPS modeling approach supports three types of data attributes (global, case-level, and event-level) as well as deterministic and stochastic attribute update rules and data-aware branching conditions. An empirical evaluation shows that the proposed method accurately discovers the type of each data attribute and its associated update rules, and that the resulting BPS models more closely replicate the process execution control flow relative to data-unaware BPS models.
Enhancing the Accuracy of Predictors of Activity Sequences of Business Processes
Dec 09, 2023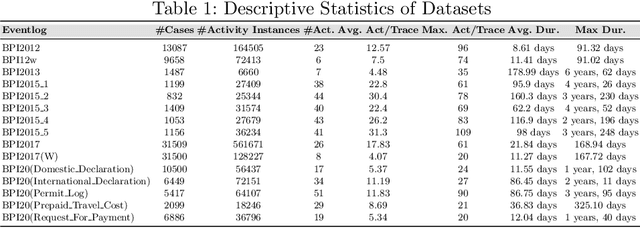

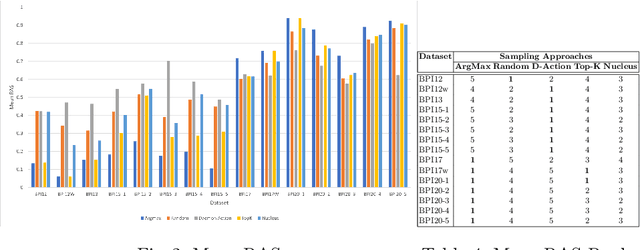
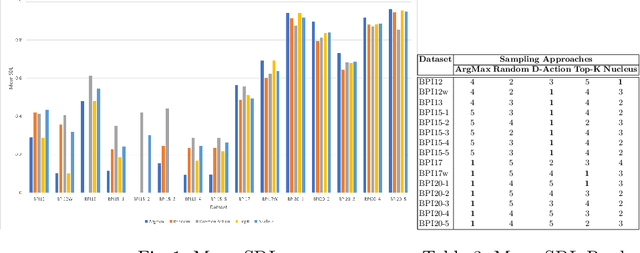
Predictive process monitoring is an evolving research field that studies how to train and use predictive models for operational decision-making. One of the problems studied in this field is that of predicting the sequence of upcoming activities in a case up to its completion, a.k.a. the case suffix. The prediction of case suffixes provides input to estimate short-term workloads and execution times under different resource schedules. Existing methods to address this problem often generate suffixes wherein some activities are repeated many times, whereas this pattern is not observed in the data. Closer examination shows that this shortcoming stems from the approach used to sample the successive activity instances to generate a case suffix. Accordingly, the paper introduces a sampling approach aimed at reducing repetitions of activities in the predicted case suffixes. The approach, namely Daemon action, strikes a balance between exploration and exploitation when generating the successive activity instances. We enhance a deep learning approach for case suffix predictions using this sampling approach, and experimentally show that the enhanced approach outperforms the unenhanced ones with respect to control-flow accuracy measures.
Prescriptive Process Monitoring Under Resource Constraints: A Reinforcement Learning Approach
Jul 13, 2023Prescriptive process monitoring methods seek to optimize the performance of business processes by triggering interventions at runtime, thereby increasing the probability of positive case outcomes. These interventions are triggered according to an intervention policy. Reinforcement learning has been put forward as an approach to learning intervention policies through trial and error. Existing approaches in this space assume that the number of resources available to perform interventions in a process is unlimited, an unrealistic assumption in practice. This paper argues that, in the presence of resource constraints, a key dilemma in the field of prescriptive process monitoring is to trigger interventions based not only on predictions of their necessity, timeliness, or effect but also on the uncertainty of these predictions and the level of resource utilization. Indeed, committing scarce resources to an intervention when the necessity or effects of this intervention are highly uncertain may intuitively lead to suboptimal intervention effects. Accordingly, the paper proposes a reinforcement learning approach for prescriptive process monitoring that leverages conformal prediction techniques to consider the uncertainty of the predictions upon which an intervention decision is based. An evaluation using real-life datasets demonstrates that explicitly modeling uncertainty using conformal predictions helps reinforcement learning agents converge towards policies with higher net intervention gain
Can I Trust My Simulation Model? Measuring the Quality of Business Process Simulation Models
Mar 30, 2023



Business Process Simulation (BPS) is an approach to analyze the performance of business processes under different scenarios. For example, BPS allows us to estimate what would be the cycle time of a process if one or more resources became unavailable. The starting point of BPS is a process model annotated with simulation parameters (a BPS model). BPS models may be manually designed, based on information collected from stakeholders and empirical observations, or automatically discovered from execution data. Regardless of its origin, a key question when using a BPS model is how to assess its quality. In this paper, we propose a collection of measures to evaluate the quality of a BPS model w.r.t. its ability to replicate the observed behavior of the process. We advocate an approach whereby different measures tackle different process perspectives. We evaluate the ability of the proposed measures to discern the impact of modifications to a BPS model, and their ability to uncover the relative strengths and weaknesses of two approaches for automated discovery of BPS models. The evaluation shows that the measures not only capture how close a BPS model is to the observed behavior, but they also help us to identify sources of discrepancies.
Learning When to Treat Business Processes: Prescriptive Process Monitoring with Causal Inference and Reinforcement Learning
Mar 07, 2023Increasing the success rate of a process, i.e. the percentage of cases that end in a positive outcome, is a recurrent process improvement goal. At runtime, there are often certain actions (a.k.a. treatments) that workers may execute to lift the probability that a case ends in a positive outcome. For example, in a loan origination process, a possible treatment is to issue multiple loan offers to increase the probability that the customer takes a loan. Each treatment has a cost. Thus, when defining policies for prescribing treatments to cases, managers need to consider the net gain of the treatments. Also, the effect of a treatment varies over time: treating a case earlier may be more effective than later in a case. This paper presents a prescriptive monitoring method that automates this decision-making task. The method combines causal inference and reinforcement learning to learn treatment policies that maximize the net gain. The method leverages a conformal prediction technique to speed up the convergence of the reinforcement learning mechanism by separating cases that are likely to end up in a positive or negative outcome, from uncertain cases. An evaluation on two real-life datasets shows that the proposed method outperforms a state-of-the-art baseline.
Intervening With Confidence: Conformal Prescriptive Monitoring of Business Processes
Dec 07, 2022Prescriptive process monitoring methods seek to improve the performance of a process by selectively triggering interventions at runtime (e.g., offering a discount to a customer) to increase the probability of a desired case outcome (e.g., a customer making a purchase). The backbone of a prescriptive process monitoring method is an intervention policy, which determines for which cases and when an intervention should be executed. Existing methods in this field rely on predictive models to define intervention policies; specifically, they consider policies that trigger an intervention when the estimated probability of a negative outcome exceeds a threshold. However, the probabilities computed by a predictive model may come with a high level of uncertainty (low confidence), leading to unnecessary interventions and, thus, wasted effort. This waste is particularly problematic when the resources available to execute interventions are limited. To tackle this shortcoming, this paper proposes an approach to extend existing prescriptive process monitoring methods with so-called conformal predictions, i.e., predictions with confidence guarantees. An empirical evaluation using real-life public datasets shows that conformal predictions enhance the net gain of prescriptive process monitoring methods under limited resources.