 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management: A Research Manifesto
Mar 19, 2026This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
Mining Frequent Structures in Conceptual Models
Jun 11, 2024



The problem of using structured methods to represent knowledge is well-known in conceptual modeling and has been studied for many years. It has been proven that adopting modeling patterns represents an effective structural method. Patterns are, indeed, generalizable recurrent structures that can be exploited as solutions to design problems. They aid in understanding and improving the process of creating models. The undeniable value of using patterns in conceptual modeling was demonstrated in several experimental studies. However, discovering patterns in conceptual models is widely recognized as a highly complex task and a systematic solution to pattern identification is currently lacking. In this paper, we propose a general approach to the problem of discovering frequent structures, as they occur in conceptual modeling languages. As proof of concept for our scientific contribution, we provide an implementation of the approach, by focusing on UML class diagrams, in particular OntoUML models. This implementation comprises an exploratory tool, which, through the combination of a frequent subgraph mining algorithm and graph manipulation techniques, can process multiple conceptual models and discover recurrent structures according to multiple criteria. The primary objective is to offer a support facility for language engineers. This can be employed to leverage both good and bad modeling practices, to evolve and maintain the conceptual modeling language, and to promote the reuse of encoded experience in designing better models with the given language.
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
Augmented Business Process Management Systems: A Research Manifesto
Feb 03, 2022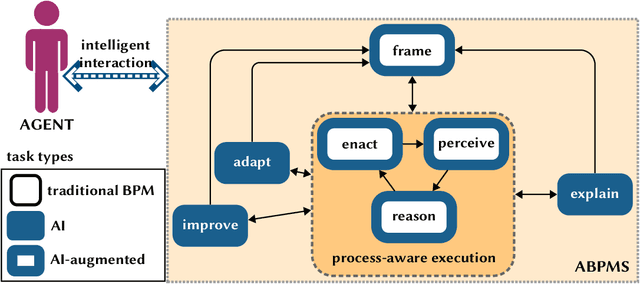
Augmented Business Process Management Systems (ABPMSs) are an emerging class of process-aware information systems that draws upon trustworthy AI technology. An ABPMS enhances the execution of business processes with the aim of making these processes more adaptable, proactive, explainable, and context-sensitive. This manifesto presents a vision for ABPMSs and discusses research challenges that need to be surmounted to realize this vision. To this end, we define the concept of ABPMS, we outline the lifecycle of processes within an ABPMS, we discuss core characteristics of an ABPMS, and we derive a set of challenges to realize systems with these characteristics.
SMT-Based Safety Verification of Data-Aware Processes under Ontologies
Aug 27, 2021In the context of verification of data-aware processes (DAPs), a formal approach based on satisfiability modulo theories (SMT) has been considered to verify parameterised safety properties of so-called artifact-centric systems. This approach requires a combination of model-theoretic notions and algorithmic techniques based on backward reachability. We introduce here a variant of one of the most investigated models in this spectrum, namely simple artifact systems (SASs), where, instead of managing a database, we operate over a description logic (DL) ontology expressed in (a slight extension of) RDFS. This DL, enjoying suitable model-theoretic properties, allows us to define DL-based SASs to which backward reachability can still be applied, leading to decidability in PSPACE of the corresponding safety problems.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
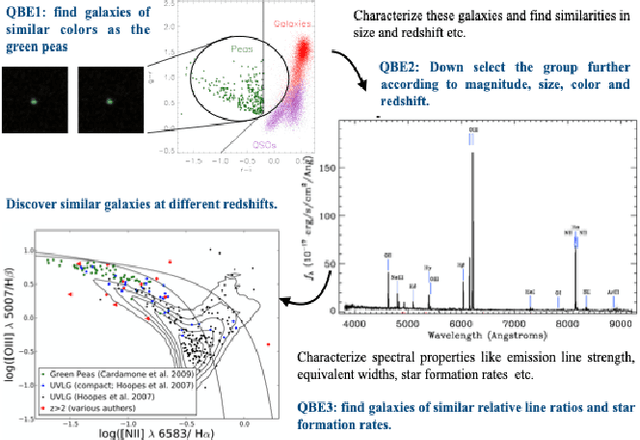
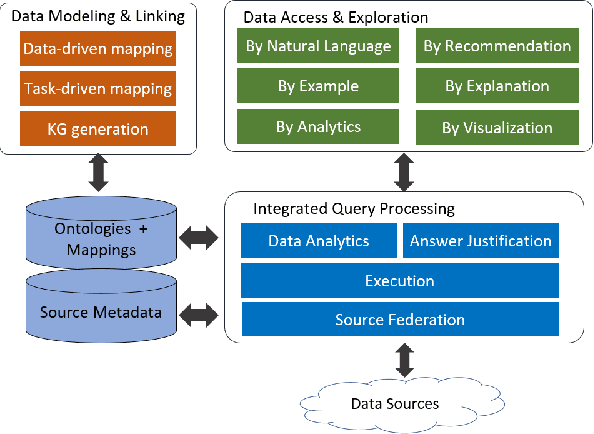

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
Mapping Patterns for Virtual Knowledge Graphs
Dec 03, 2020Virtual Knowledge Graphs (VKG) constitute one of the most promising paradigms for integrating and accessing legacy data sources. A critical bottleneck in the integration process involves the definition, validation, and maintenance of mappings that link data sources to a domain ontology. To support the management of mappings throughout their entire lifecycle, we propose a comprehensive catalog of sophisticated mapping patterns that emerge when linking databases to ontologies. To do so, we build on well-established methodologies and patterns studied in data management, data analysis, and conceptual modeling. These are extended and refined through the analysis of concrete VKG benchmarks and real-world use cases, and considering the inherent impedance mismatch between data sources and ontologies. We validate our catalog on the considered VKG scenarios, showing that it covers the vast majority of patterns present therein.
Counting Query Answers over a DL-Lite Knowledge Base
May 25, 2020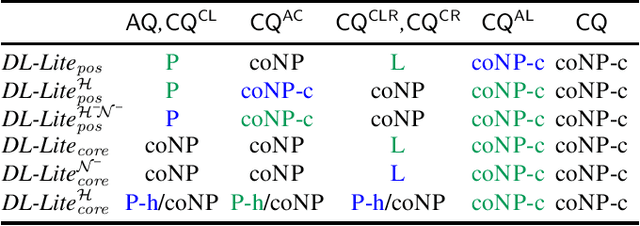
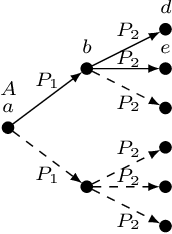
Counting answers to a query is an operation supported by virtually all database management systems. In this paper we focus on counting answers over a Knowledge Base (KB), which may be viewed as a database enriched with background knowledge about the domain under consideration. In particular, we place our work in the context of Ontology-Mediated Query Answering/Ontology-based Data Access (OMQA/OBDA), where the language used for the ontology is a member of the DL-Lite family and the data is a (usually virtual) set of assertions. We study the data complexity of query answering, for different members of the DL-Lite family that include number restrictions, and for variants of conjunctive queries with counting that differ with respect to their shape (connected, branching, rooted). We improve upon existing results by providing a PTIME and coNP lower bounds, and upper bounds in PTIME and LOGSPACE. For the latter case, we define a novel query rewriting technique into first-order logic with counting.
On Expansion and Contraction of DL-Lite Knowledge Bases
Jan 25, 2020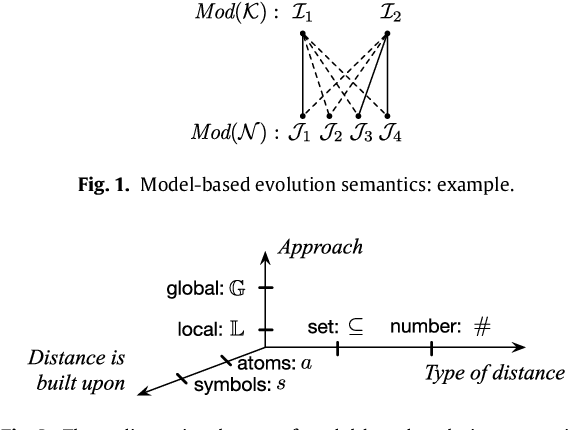
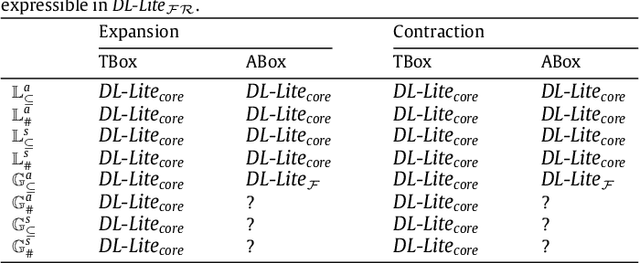
Knowledge bases (KBs) are not static entities: new information constantly appears and some of the previous knowledge becomes obsolete. In order to reflect this evolution of knowledge, KBs should be expanded with the new knowledge and contracted from the obsolete one. This problem is well-studied for propositional but much less for first-order KBs. In this work we investigate knowledge expansion and contraction for KBs expressed in DL-Lite, a family of description logics (DLs) that underlie the tractable fragment OWL 2 QL of the Web Ontology Language OWL 2. We start with a novel knowledge evolution framework and natural postulates that evolution should respect, and compare our postulates to the well-established AGM postulates. We then review well-known model and formula-based approaches for expansion and contraction for propositional theories and show how they can be adapted to the case of DL-Lite. In particular, we show intrinsic limitations of model-based approaches: besides the fact that some of them do not respect the postulates we have established, they ignore the structural properties of KBs. This leads to undesired properties of evolution results: evolution of DL-Lite KBs cannot be captured in DL-Lite. Moreover, we show that well-known formula-based approaches are also not appropriate for DL-Lite expansion and contraction: they either have a high complexity of computation, or they produce logical theories that cannot be expressed in DL-Lite. Thus, we propose a novel formula-based approach that respects our principles and for which evolution is expressible in DL-Lite. For this approach we also propose polynomial time deterministic algorithms to compute evolution of DL-Lite KBs when evolution affects only factual data.
Enriching Ontology-based Data Access with Provenance (Extended Version)
Jun 01, 2019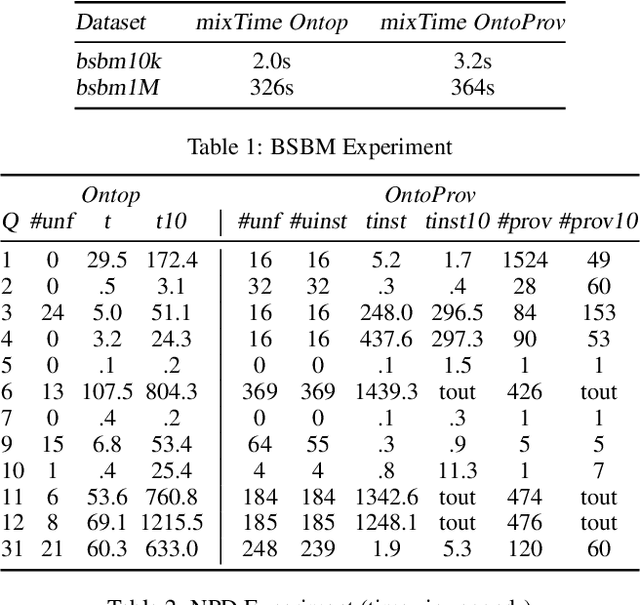
Ontology-based data access (OBDA) is a popular paradigm for querying heterogeneous data sources by connecting them through mappings to an ontology. In OBDA, it is often difficult to reconstruct why a tuple occurs in the answer of a query. We address this challenge by enriching OBDA with provenance semirings, taking inspiration from database theory. In particular, we investigate the problems of (i) deciding whether a provenance annotated OBDA instance entails a provenance annotated conjunctive query, and (ii) computing a polynomial representing the provenance of a query entailed by a provenance annotated OBDA instance. Differently from pure databases, in our case these polynomials may be infinite. To regain finiteness, we consider idempotent semirings, and study the complexity in the case of DL-Lite ontologies. We implement Task (ii) in a state-of-the-art OBDA system and show the practical feasibility of the approach through an extensive evaluation against two popular benchmarks.