 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
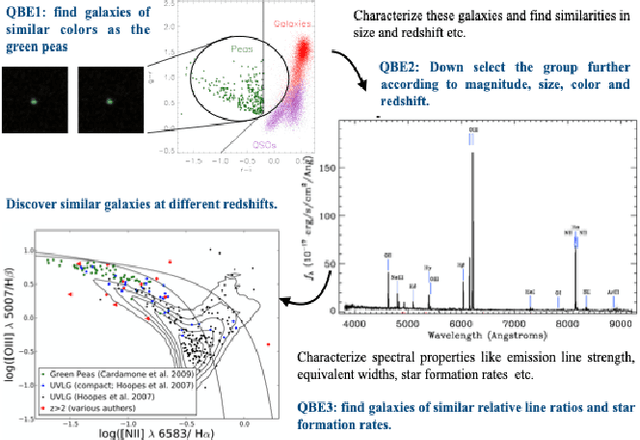
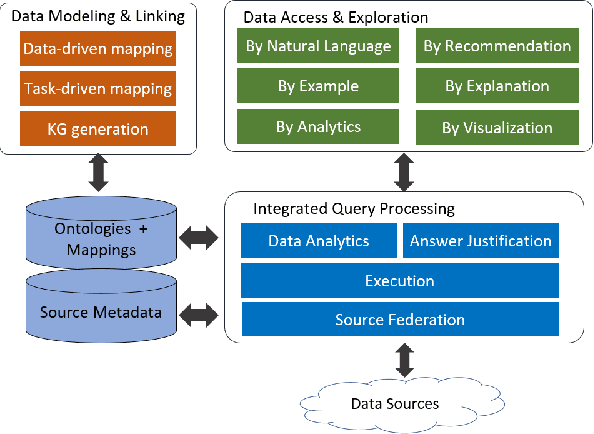

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
Mapping Patterns for Virtual Knowledge Graphs
Dec 03, 2020Virtual Knowledge Graphs (VKG) constitute one of the most promising paradigms for integrating and accessing legacy data sources. A critical bottleneck in the integration process involves the definition, validation, and maintenance of mappings that link data sources to a domain ontology. To support the management of mappings throughout their entire lifecycle, we propose a comprehensive catalog of sophisticated mapping patterns that emerge when linking databases to ontologies. To do so, we build on well-established methodologies and patterns studied in data management, data analysis, and conceptual modeling. These are extended and refined through the analysis of concrete VKG benchmarks and real-world use cases, and considering the inherent impedance mismatch between data sources and ontologies. We validate our catalog on the considered VKG scenarios, showing that it covers the vast majority of patterns present therein.
Semi-structured data extraction and modelling: the WIA Project
Sep 30, 2013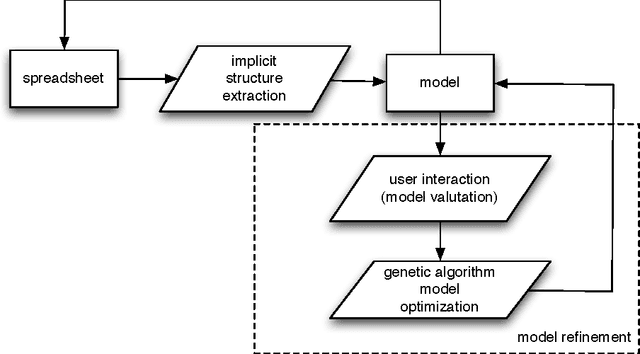
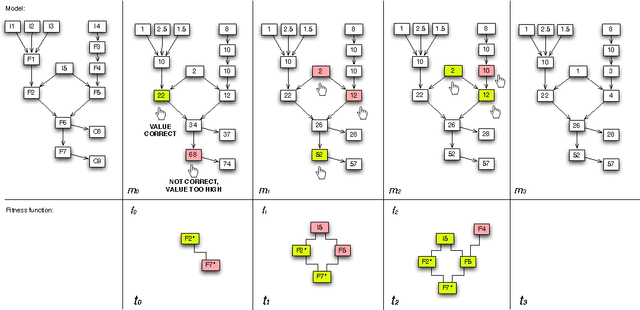
Over the last decades, the amount of data of all kinds available electronically has increased dramatically. Data are accessible through a range of interfaces including Web browsers, database query languages, application-specific interfaces, built on top of a number of different data exchange formats. All these data span from un-structured to highly structured data. Very often, some of them have structure even if the structure is implicit, and not as rigid or regular as that found in standard database systems. Spreadsheet documents are prototypical in this respect. Spreadsheets are the lightweight technology able to supply companies with easy to build business management and business intelligence applications, and business people largely adopt spreadsheets as smart vehicles for data files generation and sharing. Actually, the more spreadsheets grow in complexity (e.g., their use in product development plans and quoting), the more their arrangement, maintenance, and analysis appear as a knowledge-driven activity. The algorithmic approach to the problem of automatic data structure extraction from spreadsheet documents (i.e., grid-structured and free topological-related data) emerges from the WIA project: Worksheets Intelligent Analyser. The WIA-algorithm shows how to provide a description of spreadsheet contents in terms of higher level of abstractions or conceptualisations. In particular, the WIA-algorithm target is about the extraction of i) the calculus work-flow implemented in the spreadsheets formulas and ii) the logical role played by the data which take part into the calculus. The aim of the resulting conceptualisations is to provide spreadsheets with abstract representations useful for further model refinements and optimizations through evolutionary algorithms computations.
* In Proceedings Wivace 2013, arXiv:1309.7122