 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3dSAGER: Geospatial Entity Resolution over 3D Objects (Technical Report)
Nov 09, 2025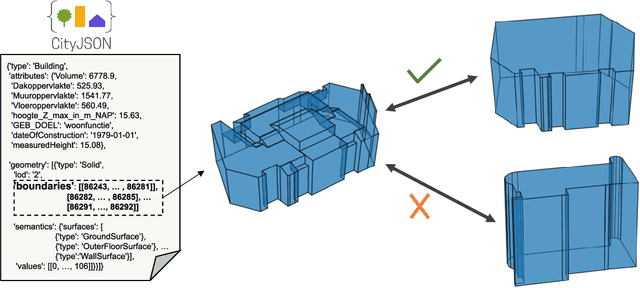
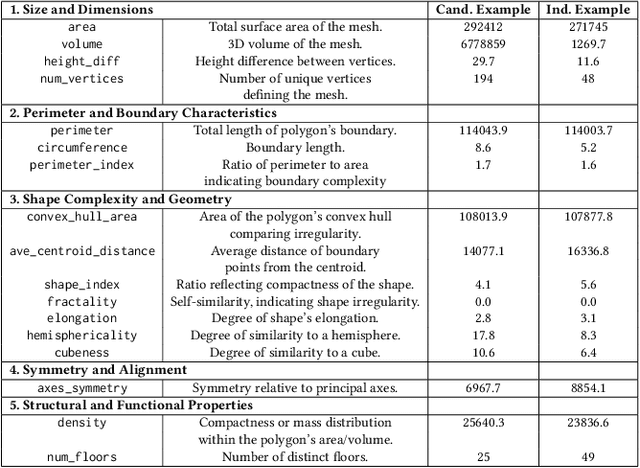
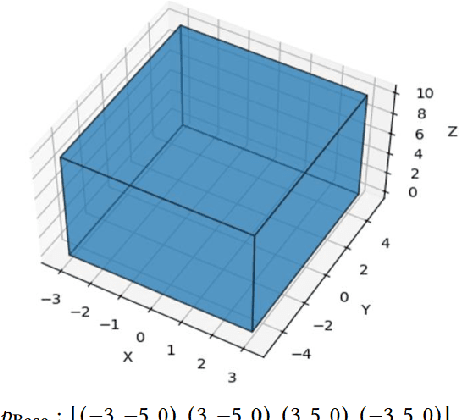
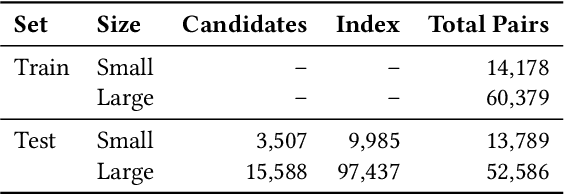
Urban environments are continuously mapped and modeled by various data collection platforms, including satellites, unmanned aerial vehicles and street cameras. The growing availability of 3D geospatial data from multiple modalities has introduced new opportunities and challenges for integrating spatial knowledge at scale, particularly in high-impact domains such as urban planning and rapid disaster management. Geospatial entity resolution is the task of identifying matching spatial objects across different datasets, often collected independently under varying conditions. Existing approaches typically rely on spatial proximity, textual metadata, or external identifiers to determine correspondence. While useful, these signals are often unavailable, unreliable, or misaligned, especially in cross-source scenarios. To address these limitations, we shift the focus to the intrinsic geometry of 3D spatial objects and present 3dSAGER (3D Spatial-Aware Geospatial Entity Resolution), an end-to-end pipeline for geospatial entity resolution over 3D objects. 3dSAGER introduces a novel, spatial-reference-independent featurization mechanism that captures intricate geometric characteristics of matching pairs, enabling robust comparison even across datasets with incompatible coordinate systems where traditional spatial methods fail. As a key component of 3dSAGER, we also propose a new lightweight and interpretable blocking method, BKAFI, that leverages a trained model to efficiently generate high-recall candidate sets. We validate 3dSAGER through extensive experiments on real-world urban datasets, demonstrating significant gains in both accuracy and efficiency over strong baselines. Our empirical study further dissects the contributions of each component, providing insights into their impact and the overall design choices.
Humans, Machine Learning, and Language Models in Union: A Cognitive Study on Table Unionability
Jun 15, 2025Data discovery and table unionability in particular became key tasks in modern Data Science. However, the human perspective for these tasks is still under-explored. Thus, this research investigates the human behavior in determining table unionability within data discovery. We have designed an experimental survey and conducted a comprehensive analysis, in which we assess human decision-making for table unionability. We use the observations from the analysis to develop a machine learning framework to boost the (raw) performance of humans. Furthermore, we perform a preliminary study on how LLM performance is compared to humans indicating that it is typically better to consider a combination of both. We believe that this work lays the foundations for developing future Human-in-the-Loop systems for efficient data discovery.
Fuzzy Integration of Data Lake Tables
Jan 16, 2025Data integration is an important step in any data science pipeline where the objective is to unify the information available in different datasets for comprehensive analysis. Full Disjunction, which is an associative extension of the outer join operator, has been shown to be an effective operator for integrating datasets. It fully preserves and combines the available information. Existing Full Disjunction algorithms only consider the equi-join scenario where only tuples having the same value on joining columns are integrated. This, however, does not realistically represent an open data scenario, where datasets come from diverse sources with inconsistent values (e.g., synonyms, abbreviations, etc.) and with limited metadata. So, joining just on equal values severely limits the ability of Full Disjunction to fully combine datasets. Thus, in this work, we propose an extension of Full Disjunction to also account for "fuzzy" matches among tuples. We present a novel data-driven approach to enable the joining of approximate or fuzzy matches within Full Disjunction. Experimentally, we show that fuzzy Full Disjunction does not add significant time overhead over a state-of-the-art Full Disjunction implementation and also that it enhances the integration effectiveness.
The Battleship Approach to the Low Resource Entity Matching Problem
Nov 27, 2023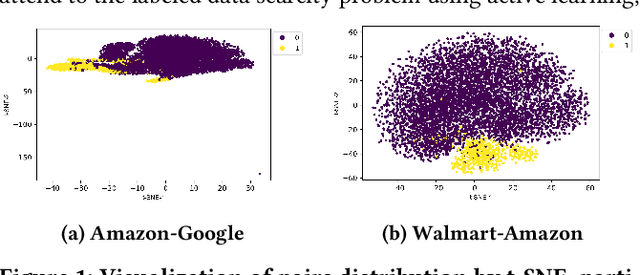


Entity matching, a core data integration problem, is the task of deciding whether two data tuples refer to the same real-world entity. Recent advances in deep learning methods, using pre-trained language models, were proposed for resolving entity matching. Although demonstrating unprecedented results, these solutions suffer from a major drawback as they require large amounts of labeled data for training, and, as such, are inadequate to be applied to low resource entity matching problems. To overcome the challenge of obtaining sufficient labeled data we offer a new active learning approach, focusing on a selection mechanism that exploits unique properties of entity matching. We argue that a distributed representation of a tuple pair indicates its informativeness when considered among other pairs. This is used consequently in our approach that iteratively utilizes space-aware considerations. Bringing it all together, we treat the low resource entity matching problem as a Battleship game, hunting indicative samples, focusing on positive ones, through awareness of the latent space along with careful planning of next sampling iterations. An extensive experimental analysis shows that the proposed algorithm outperforms state-of-the-art active learning solutions to low resource entity matching, and although using less samples, can be as successful as state-of-the-art fully trained known algorithms.
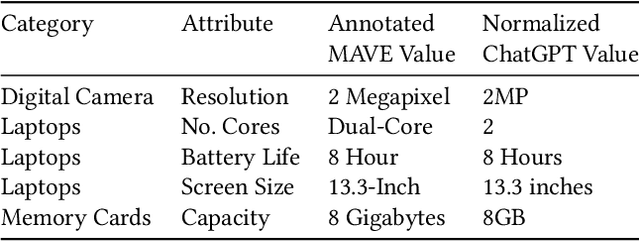
Product Attribute Value Extraction using Large Language Models
Oct 19, 2023E-commerce applications such as faceted product search or product comparison are based on structured product descriptions like attribute/value pairs. The vendors on e-commerce platforms do not provide structured product descriptions but describe offers using titles or descriptions. To process such offers, it is necessary to extract attribute/value pairs from textual product attributes. State-of-the-art attribute/value extraction techniques rely on pre-trained language models (PLMs), such as BERT. Two major drawbacks of these models for attribute/value extraction are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models face challenges in generalizing to attribute values not included in the training data. This paper explores the potential of large language models (LLMs) as a training data-efficient and robust alternative to PLM-based attribute/value extraction methods. We consider hosted LLMs, such as GPT-3.5 and GPT-4, as well as open-source LLMs based on Llama2. We evaluate the models in a zero-shot scenario and in a scenario where task-specific training data is available. In the zero-shot scenario, we compare various prompt designs for representing information about the target attributes of the extraction. In the scenario with training data, we investigate (i) the provision of example attribute values, (ii) the selection of in-context demonstrations, and (iii) the fine-tuning of GPT-3.5. Our experiments show that GPT-4 achieves an average F1-score of 85% on the two evaluation datasets while the best PLM-based techniques perform on average 5% worse using the same amount of training data. GPT-4 achieves a 10% higher F1-score than the best open-source LLM. The fine-tuned GPT-3.5 model reaches a similar performance as GPT-4 while being significantly more cost-efficient.
Generative Benchmark Creation for Table Union Search
Aug 07, 2023Data management has traditionally relied on synthetic data generators to generate structured benchmarks, like the TPC suite, where we can control important parameters like data size and its distribution precisely. These benchmarks were central to the success and adoption of database management systems. But more and more, data management problems are of a semantic nature. An important example is finding tables that can be unioned. While any two tables with the same cardinality can be unioned, table union search is the problem of finding tables whose union is semantically coherent. Semantic problems cannot be benchmarked using synthetic data. Our current methods for creating benchmarks involve the manual curation and labeling of real data. These methods are not robust or scalable and perhaps more importantly, it is not clear how robust the created benchmarks are. We propose to use generative AI models to create structured data benchmarks for table union search. We present a novel method for using generative models to create tables with specified properties. Using this method, we create a new benchmark containing pairs of tables that are both unionable and non-unionable but related. We thoroughly evaluate recent existing table union search methods over existing benchmarks and our new benchmark. We also present and evaluate a new table search methods based on recent large language models over all benchmarks. We show that the new benchmark is more challenging for all methods than hand-curated benchmarks, specifically, the top-performing method achieves a Mean Average Precision of around 60%, over 30% less than its performance on existing manually created benchmarks. We examine why this is the case and show that the new benchmark permits more detailed analysis of methods, including a study of both false positives and false negatives that were not possible with existing benchmarks.
Product Information Extraction using ChatGPT
Jun 23, 2023
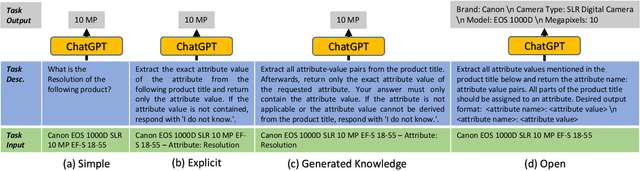
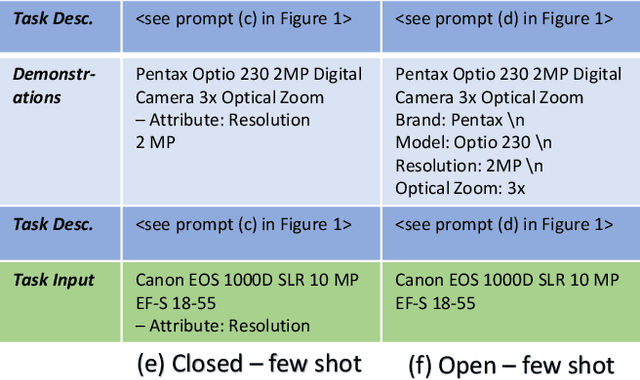
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
SC-Block: Supervised Contrastive Blocking within Entity Resolution Pipelines
Mar 06, 2023The goal of entity resolution is to identify records in multiple datasets that represent the same real-world entity. However, comparing all records across datasets can be computationally intensive, leading to long runtimes. To reduce these runtimes, entity resolution pipelines are constructed of two parts: a blocker that applies a computationally cheap method to select candidate record pairs, and a matcher that afterwards identifies matching pairs from this set using more expensive methods. This paper presents SC-Block, a blocking method that utilizes supervised contrastive learning for positioning records in the embedding space, and nearest neighbour search for candidate set building. We benchmark SC-Block against eight state-of-the-art blocking methods. In order to relate the training time of SC-Block to the reduction of the overall runtime of the entity resolution pipeline, we combine SC-Block with four matching methods into complete pipelines. For measuring the overall runtime, we determine candidate sets with 98% pair completeness and pass them to the matcher. The results show that SC-Block is able to create smaller candidate sets and pipelines with SC-Block execute 1.5 to 2 times faster compared to pipelines with other blockers, without sacrificing F1 score. Blockers are often evaluated using relatively small datasets which might lead to runtime effects resulting from a large vocabulary size being overlooked. In order to measure runtimes in a more challenging setting, we introduce a new benchmark dataset that requires large numbers of product offers to be blocked. On this large-scale benchmark dataset, pipelines utilizing SC-Block and the best-performing matcher execute 8 times faster than pipelines utilizing another blocker with the same matcher reducing the runtime from 2.5 hours to 18 minutes, clearly compensating for the 5 minutes required for training SC-Block.
HumanAL: Calibrating Human Matching Beyond a Single Task
May 06, 2022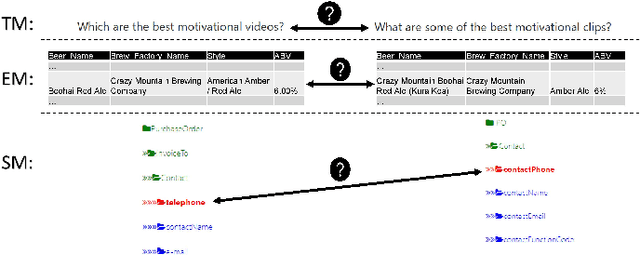

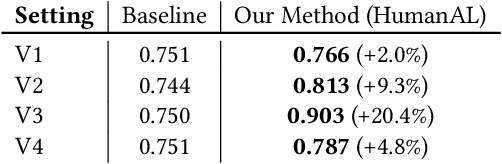
This work offers a novel view on the use of human input as labels, acknowledging that humans may err. We build a behavioral profile for human annotators which is used as a feature representation of the provided input. We show that by utilizing black-box machine learning, we can take into account human behavior and calibrate their input to improve the labeling quality. To support our claims and provide a proof-of-concept, we experiment with three different matching tasks, namely, schema matching, entity matching and text matching. Our empirical evaluation suggests that the method can improve the quality of gathered labels in multiple settings including cross-domain (across different matching tasks).
Human's Role in-the-Loop
Apr 27, 2022

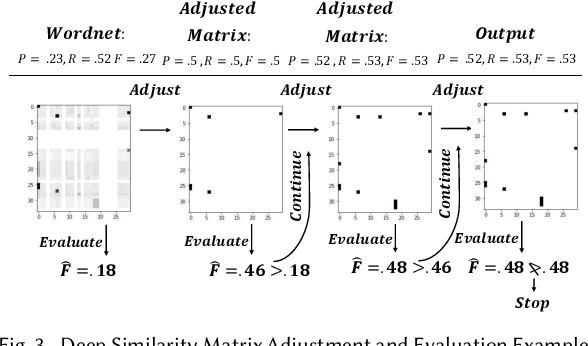

Data integration has been recently challenged by the need to handle large volumes of data, arriving at high velocity from a variety of sources, which demonstrate varying levels of veracity. This challenging setting, often referred to as big data, renders many of the existing techniques, especially those that are human-intensive, obsolete. Big data also produces technological advancements such as Internet of things, cloud computing, and deep learning, and accordingly, provides a new, exciting, and challenging research agenda. Given the availability of data and the improvement of machine learning techniques, this blog discusses the respective roles of humans and machines in achieving cognitive tasks in matching, aiming to determine whether traditional roles of humans and machines are subject to change. Such investigation, we believe, will pave a way to better utilize both human and machine resources in new and innovative manners. We shall discuss two possible modes of change, namely humans out and humans in. Humans out aim at exploring out-of-the-box latent matching reasoning using machine learning algorithms when attempting to overpower human matcher performance. Pursuing out-of-the-box thinking, machine and deep learning can be involved in matching. Humans in explores how to better involve humans in the matching loop by assigning human matchers with a symmetric role to algorithmic matcher in the matching process.