 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Self-Refinement and Self-Correction for LLM-based Product Attribute Value Extraction
Jan 02, 2025



Structured product data, in the form of attribute-value pairs, is essential for e-commerce platforms to support features such as faceted product search and attribute-based product comparison. However, vendors often provide unstructured product descriptions, making attribute value extraction necessary to ensure data consistency and usability. Large language models (LLMs) have demonstrated their potential for product attribute value extraction in few-shot scenarios. Recent research has shown that self-refinement techniques can improve the performance of LLMs on tasks such as code generation and text-to-SQL translation. For other tasks, the application of these techniques has resulted in increased costs due to processing additional tokens, without achieving any improvement in performance. This paper investigates applying two self-refinement techniques, error-based prompt rewriting and self-correction, to the product attribute value extraction task. The self-refinement techniques are evaluated across zero-shot, few-shot in-context learning, and fine-tuning scenarios using GPT-4o. The experiments show that both self-refinement techniques have only a marginal impact on the model's performance across the different scenarios, while significantly increasing processing costs. For scenarios with training data, fine-tuning yields the highest performance, while the ramp-up costs of fine-tuning are balanced out as the amount of product descriptions increases.
Using LLMs for the Extraction and Normalization of Product Attribute Values
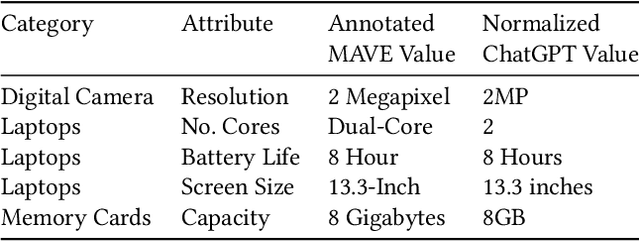
Mar 05, 2024Product offers on e-commerce websites often consist of a textual product title and a textual product description. In order to provide features such as faceted product filtering or content-based product recommendation, the websites need to extract attribute-value pairs from the unstructured product descriptions. This paper explores the potential of using large language models (LLMs), such as OpenAI's GPT-3.5 and GPT-4, to extract and normalize attribute values from product titles and product descriptions. For our experiments, we introduce the WDC Product Attribute-Value Extraction (WDC PAVE) dataset. WDC PAVE consists of product offers from 87 websites that provide schema$.$org annotations. The offers belong to five different categories, each featuring a specific set of attributes. The dataset provides manually verified attribute-value pairs in two forms: (i) directly extracted values and (ii) normalized attribute values. The normalization of the attribute values requires systems to perform the following types of operations: name expansion, generalization, unit of measurement normalization, and string wrangling. Our experiments demonstrate that GPT-4 outperforms PLM-based extraction methods by 10%, achieving an F1-Score of 91%. For the extraction and normalization of product attribute values, GPT-4 achieves a similar performance to the extraction scenario, while being particularly strong at string wrangling and name expansion.
Product Attribute Value Extraction using Large Language Models
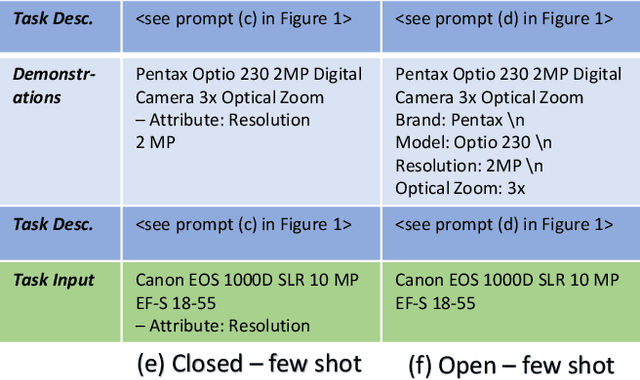
Oct 19, 2023E-commerce applications such as faceted product search or product comparison are based on structured product descriptions like attribute/value pairs. The vendors on e-commerce platforms do not provide structured product descriptions but describe offers using titles or descriptions. To process such offers, it is necessary to extract attribute/value pairs from textual product attributes. State-of-the-art attribute/value extraction techniques rely on pre-trained language models (PLMs), such as BERT. Two major drawbacks of these models for attribute/value extraction are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models face challenges in generalizing to attribute values not included in the training data. This paper explores the potential of large language models (LLMs) as a training data-efficient and robust alternative to PLM-based attribute/value extraction methods. We consider hosted LLMs, such as GPT-3.5 and GPT-4, as well as open-source LLMs based on Llama2. We evaluate the models in a zero-shot scenario and in a scenario where task-specific training data is available. In the zero-shot scenario, we compare various prompt designs for representing information about the target attributes of the extraction. In the scenario with training data, we investigate (i) the provision of example attribute values, (ii) the selection of in-context demonstrations, and (iii) the fine-tuning of GPT-3.5. Our experiments show that GPT-4 achieves an average F1-score of 85% on the two evaluation datasets while the best PLM-based techniques perform on average 5% worse using the same amount of training data. GPT-4 achieves a 10% higher F1-score than the best open-source LLM. The fine-tuned GPT-3.5 model reaches a similar performance as GPT-4 while being significantly more cost-efficient.
Product Information Extraction using ChatGPT
Jun 23, 2023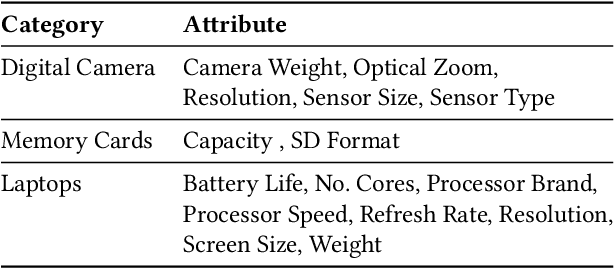
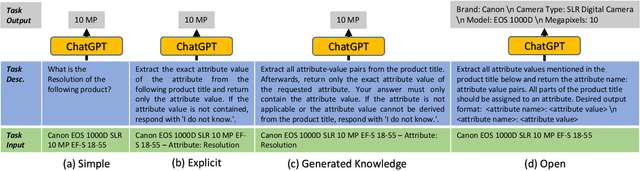
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
SC-Block: Supervised Contrastive Blocking within Entity Resolution Pipelines
Mar 06, 2023The goal of entity resolution is to identify records in multiple datasets that represent the same real-world entity. However, comparing all records across datasets can be computationally intensive, leading to long runtimes. To reduce these runtimes, entity resolution pipelines are constructed of two parts: a blocker that applies a computationally cheap method to select candidate record pairs, and a matcher that afterwards identifies matching pairs from this set using more expensive methods. This paper presents SC-Block, a blocking method that utilizes supervised contrastive learning for positioning records in the embedding space, and nearest neighbour search for candidate set building. We benchmark SC-Block against eight state-of-the-art blocking methods. In order to relate the training time of SC-Block to the reduction of the overall runtime of the entity resolution pipeline, we combine SC-Block with four matching methods into complete pipelines. For measuring the overall runtime, we determine candidate sets with 98% pair completeness and pass them to the matcher. The results show that SC-Block is able to create smaller candidate sets and pipelines with SC-Block execute 1.5 to 2 times faster compared to pipelines with other blockers, without sacrificing F1 score. Blockers are often evaluated using relatively small datasets which might lead to runtime effects resulting from a large vocabulary size being overlooked. In order to measure runtimes in a more challenging setting, we introduce a new benchmark dataset that requires large numbers of product offers to be blocked. On this large-scale benchmark dataset, pipelines utilizing SC-Block and the best-performing matcher execute 8 times faster than pipelines utilizing another blocker with the same matcher reducing the runtime from 2.5 hours to 18 minutes, clearly compensating for the 5 minutes required for training SC-Block.