 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Knowledge Generation and Self-Refinement Strategies for LLM-based Column Type Annotation
Mar 04, 2025Understanding the semantics of columns in relational tables is an important pre-processing step for indexing data lakes in order to provide rich data search. An approach to establishing such understanding is column type annotation (CTA) where the goal is to annotate table columns with terms from a given vocabulary. This paper experimentally compares different knowledge generation and self-refinement strategies for LLM-based column type annotation. The strategies include using LLMs to generate term definitions, error-based refinement of term definitions, self-correction, and fine-tuning using examples and term definitions. We evaluate these strategies along two dimensions: effectiveness measured as F1 performance and efficiency measured in terms of token usage and cost. Our experiments show that the best performing strategy depends on the model/dataset combination. We find that using training data to generate label definitions outperforms using the same data as demonstrations for in-context learning for two out of three datasets using OpenAI models. The experiments further show that using the LLMs to refine label definitions brings an average increase of 3.9% F1 in 10 out of 12 setups compared to the performance of the non-refined definitions. Combining fine-tuned models with self-refined term definitions results in the overall highest performance, outperforming zero-shot prompting fine-tuned models by at least 3% in F1 score. The costs analysis shows that while reaching similar F1 score, self-refinement via prompting is more cost efficient for use cases requiring smaller amounts of tables to be annotated while fine-tuning is more efficient for large amounts of tables.
Automated Self-Refinement and Self-Correction for LLM-based Product Attribute Value Extraction
Jan 02, 2025



Structured product data, in the form of attribute-value pairs, is essential for e-commerce platforms to support features such as faceted product search and attribute-based product comparison. However, vendors often provide unstructured product descriptions, making attribute value extraction necessary to ensure data consistency and usability. Large language models (LLMs) have demonstrated their potential for product attribute value extraction in few-shot scenarios. Recent research has shown that self-refinement techniques can improve the performance of LLMs on tasks such as code generation and text-to-SQL translation. For other tasks, the application of these techniques has resulted in increased costs due to processing additional tokens, without achieving any improvement in performance. This paper investigates applying two self-refinement techniques, error-based prompt rewriting and self-correction, to the product attribute value extraction task. The self-refinement techniques are evaluated across zero-shot, few-shot in-context learning, and fine-tuning scenarios using GPT-4o. The experiments show that both self-refinement techniques have only a marginal impact on the model's performance across the different scenarios, while significantly increasing processing costs. For scenarios with training data, fine-tuning yields the highest performance, while the ramp-up costs of fine-tuning are balanced out as the amount of product descriptions increases.
Fine-tuning Large Language Models for Entity Matching
Sep 12, 2024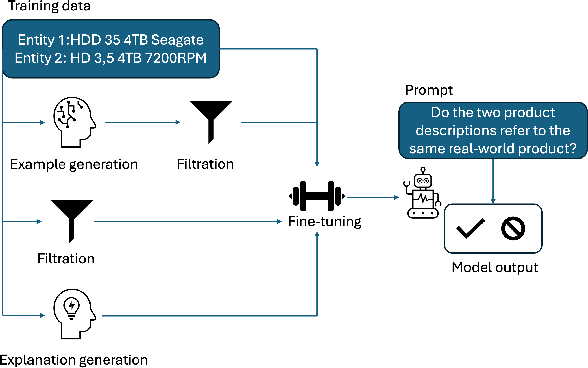
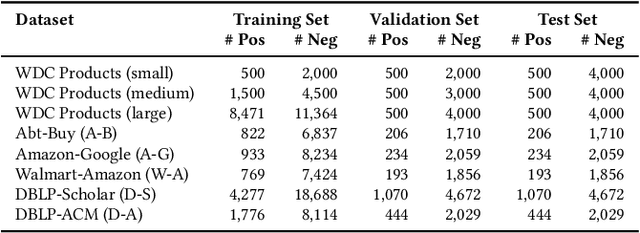

Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and their ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) The representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the model's ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o Mini.
Desk-AId: Humanitarian Aid Desk Assessment with Geospatial AI for Predicting Landmine Areas
May 15, 2024



The process of clearing areas, namely demining, starts by assessing and prioritizing potential hazardous areas (i.e., desk assessment) to go under thorough investigation of experts, who confirm the risk and proceed with the mines clearance operations. This paper presents Desk-AId that supports the desk assessment phase by estimating landmine risks using geospatial data and socioeconomic information. Desk-AId uses a Geospatial AI approach specialized to landmines. The approach includes mixed data sampling strategies and context-enrichment by historical conflicts and key multi-domain facilities (e.g., buildings, roads, health sites). The proposed system addresses the issue of having only ground-truth for confirmed hazardous areas by implementing a new hard-negative data sampling strategy, where negative points are sampled in the vicinity of hazardous areas. Experiments validate Desk-Aid in two domains for landmine risk assessment: 1) country-wide, and 2) uncharted study areas). The proposed approach increases the estimation accuracies up to 92%, for different classification models such as RandomForest (RF), Feedforward Neural Networks (FNN), and Graph Neural Networks (GNN).
Using LLMs for the Extraction and Normalization of Product Attribute Values
Mar 05, 2024Product offers on e-commerce websites often consist of a textual product title and a textual product description. In order to provide features such as faceted product filtering or content-based product recommendation, the websites need to extract attribute-value pairs from the unstructured product descriptions. This paper explores the potential of using large language models (LLMs), such as OpenAI's GPT-3.5 and GPT-4, to extract and normalize attribute values from product titles and product descriptions. For our experiments, we introduce the WDC Product Attribute-Value Extraction (WDC PAVE) dataset. WDC PAVE consists of product offers from 87 websites that provide schema$.$org annotations. The offers belong to five different categories, each featuring a specific set of attributes. The dataset provides manually verified attribute-value pairs in two forms: (i) directly extracted values and (ii) normalized attribute values. The normalization of the attribute values requires systems to perform the following types of operations: name expansion, generalization, unit of measurement normalization, and string wrangling. Our experiments demonstrate that GPT-4 outperforms PLM-based extraction methods by 10%, achieving an F1-Score of 91%. For the extraction and normalization of product attribute values, GPT-4 achieves a similar performance to the extraction scenario, while being particularly strong at string wrangling and name expansion.
Product Attribute Value Extraction using Large Language Models
Oct 19, 2023E-commerce applications such as faceted product search or product comparison are based on structured product descriptions like attribute/value pairs. The vendors on e-commerce platforms do not provide structured product descriptions but describe offers using titles or descriptions. To process such offers, it is necessary to extract attribute/value pairs from textual product attributes. State-of-the-art attribute/value extraction techniques rely on pre-trained language models (PLMs), such as BERT. Two major drawbacks of these models for attribute/value extraction are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models face challenges in generalizing to attribute values not included in the training data. This paper explores the potential of large language models (LLMs) as a training data-efficient and robust alternative to PLM-based attribute/value extraction methods. We consider hosted LLMs, such as GPT-3.5 and GPT-4, as well as open-source LLMs based on Llama2. We evaluate the models in a zero-shot scenario and in a scenario where task-specific training data is available. In the zero-shot scenario, we compare various prompt designs for representing information about the target attributes of the extraction. In the scenario with training data, we investigate (i) the provision of example attribute values, (ii) the selection of in-context demonstrations, and (iii) the fine-tuning of GPT-3.5. Our experiments show that GPT-4 achieves an average F1-score of 85% on the two evaluation datasets while the best PLM-based techniques perform on average 5% worse using the same amount of training data. GPT-4 achieves a 10% higher F1-score than the best open-source LLM. The fine-tuned GPT-3.5 model reaches a similar performance as GPT-4 while being significantly more cost-efficient.
Entity Matching using Large Language Models
Oct 17, 2023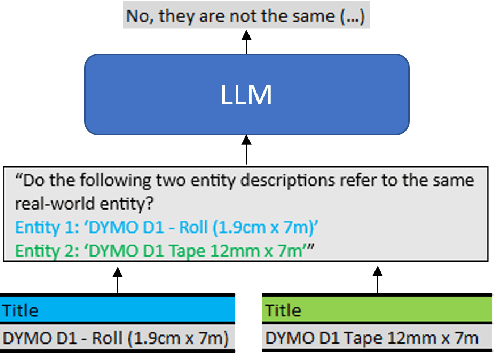
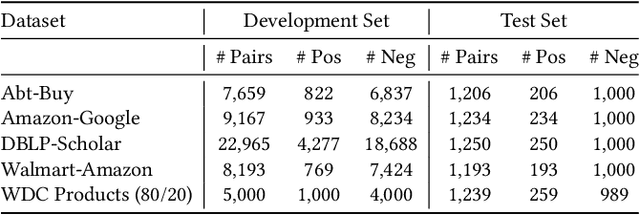
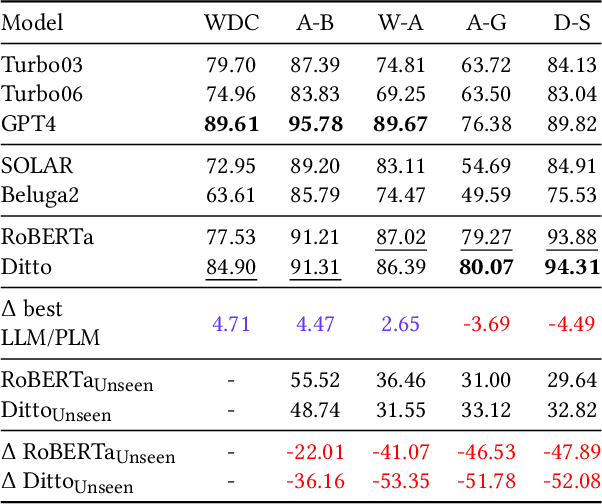

Entity Matching is the task of deciding whether two entity descriptions refer to the same real-world entity. Entity Matching is a central step in most data integration pipelines and an enabler for many e-commerce applications which require to match products offers from different vendors. State-of-the-art entity matching methods often rely on pre-trained language models (PLMs) such as BERT or RoBERTa. Two major drawbacks of these models for entity matching are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. In this paper, we investigate using large language models (LLMs) for entity matching as a less domain-specific training data reliant and more robust alternative to PLM-based matchers. Our study covers hosted LLMs, such as GPT3.5 and GPT4, as well as open source LLMs based on Llama2 which can be run locally. We evaluate these models in a zero-shot scenario as well as a scenario where task-specific training data is available. We compare different prompt designs as well as the prompt sensitivity of the models in the zero-shot scenario. We investigate (i) the selection of in-context demonstrations, (ii) the generation of matching rules, as well as (iii) fine-tuning GPT3.5 in the second scenario using the same pool of training data across the different approaches. Our experiments show that GPT4 without any task-specific training data outperforms fine-tuned PLMs (RoBERTa and Ditto) on three out of five benchmark datasets reaching F1 scores around 90%. The experiments with in-context learning and rule generation show that all models beside of GPT4 benefit from these techniques (on average 5.9% and 2.2% F1), while GPT4 does not need such additional guidance in most cases...
Product Information Extraction using ChatGPT
Jun 23, 2023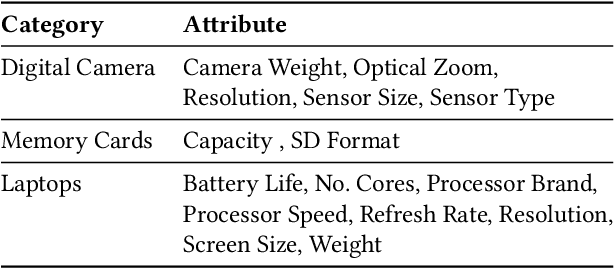
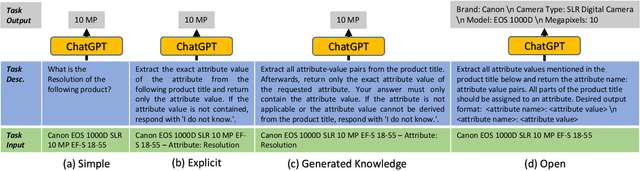
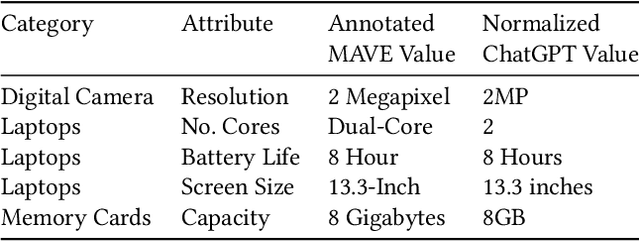
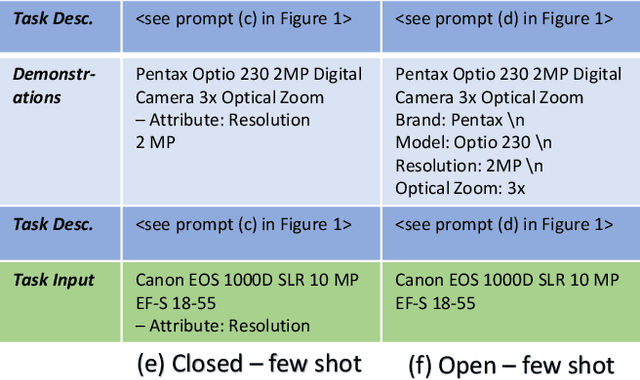
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
Column Type Annotation using ChatGPT
Jun 01, 2023Column type annotation is the task of annotating the columns of a relational table with the semantic type of the values contained in each column. Column type annotation is a crucial pre-processing step for data search and integration in the context of data lakes. State-of-the-art column type annotation methods either rely on matching table columns to properties of a knowledge graph or fine-tune pre-trained language models such as BERT for the column type annotation task. In this work, we take a different approach and explore using ChatGPT for column type annotation. We evaluate different prompt designs in zero- and few-shot settings and experiment with providing task definitions and detailed instructions to the model. We further implement a two-step table annotation pipeline which first determines the class of the entities described in the table and depending on this class asks ChatGPT to annotate columns using only the relevant subset of the overall vocabulary. Using instructions as well as the two-step pipeline, ChatGPT reaches F1 scores of over 85% in zero- and one-shot setups. To reach a similar F1 score a RoBERTa model needs to be fine-tuned with 300 examples. This comparison shows that ChatGPT is able deliver competitive results for the column type annotation task given no or only a minimal amount of task-specific demonstrations.
Using ChatGPT for Entity Matching
May 05, 2023Entity Matching is the task of deciding if two entity descriptions refer to the same real-world entity. State-of-the-art entity matching methods often rely on fine-tuning Transformer models such as BERT or RoBERTa. Two major drawbacks of using these models for entity matching are that (i) the models require significant amounts of fine-tuning data for reaching a good performance and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. In this paper, we investigate using ChatGPT for entity matching as a more robust, training data-efficient alternative to traditional Transformer models. We perform experiments along three dimensions: (i) general prompt design, (ii) in-context learning, and (iii) provision of higher-level matching knowledge. We show that ChatGPT is competitive with a fine-tuned RoBERTa model, reaching an average zero-shot performance of 83% F1 on a challenging matching task on which RoBERTa requires 2000 training examples for reaching a similar performance. Adding in-context demonstrations to the prompts further improves the F1 by up to 5% even using only a small set of 20 handpicked examples. Finally, we show that guiding the zero-shot model by stating higher-level matching rules leads to similar gains as providing in-context examples.