 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextMine: LLM-Powered Knowledge Extraction for Humanitarian Mine Action
Sep 18, 2025Humanitarian Mine Action has generated extensive best-practice knowledge, but much remains locked in unstructured reports. We introduce TextMine, an ontology-guided pipeline that uses Large Language Models to extract knowledge triples from HMA texts. TextMine integrates document chunking, domain-aware prompting, triple extraction, and both reference-based and LLM-as-a-Judge evaluation. We also create the first HMA ontology and a curated dataset of real-world demining reports. Experiments show ontology-aligned prompts boost extraction accuracy by 44.2%, cut hallucinations by 22.5%, and improve format conformance by 20.9% over baselines. While validated on Cambodian reports, TextMine can adapt to global demining efforts or other domains, transforming unstructured data into structured knowledge.
Problem Solved? Information Extraction Design Space for Layout-Rich Documents using LLMs
Feb 25, 2025



This paper defines and explores the design space for information extraction (IE) from layout-rich documents using large language models (LLMs). The three core challenges of layout-aware IE with LLMs are 1) data structuring, 2) model engagement, and 3) output refinement. Our study delves into the sub-problems within these core challenges, such as input representation, chunking, prompting, and selection of LLMs and multimodal models. It examines the outcomes of different design choices through a new layout-aware IE test suite, benchmarking against the state-of-art (SoA) model LayoutLMv3. The results show that the configuration from one-factor-at-a-time (OFAT) trial achieves near-optimal results with 14.1 points F1-score gain from the baseline model, while full factorial exploration yields only a slightly higher 15.1 points gain at around 36x greater token usage. We demonstrate that well-configured general-purpose LLMs can match the performance of specialized models, providing a cost-effective alternative. Our test-suite is freely available at https://github.com/gayecolakoglu/LayIE-LLM.
Desk-AId: Humanitarian Aid Desk Assessment with Geospatial AI for Predicting Landmine Areas
May 15, 2024



The process of clearing areas, namely demining, starts by assessing and prioritizing potential hazardous areas (i.e., desk assessment) to go under thorough investigation of experts, who confirm the risk and proceed with the mines clearance operations. This paper presents Desk-AId that supports the desk assessment phase by estimating landmine risks using geospatial data and socioeconomic information. Desk-AId uses a Geospatial AI approach specialized to landmines. The approach includes mixed data sampling strategies and context-enrichment by historical conflicts and key multi-domain facilities (e.g., buildings, roads, health sites). The proposed system addresses the issue of having only ground-truth for confirmed hazardous areas by implementing a new hard-negative data sampling strategy, where negative points are sampled in the vicinity of hazardous areas. Experiments validate Desk-Aid in two domains for landmine risk assessment: 1) country-wide, and 2) uncharted study areas). The proposed approach increases the estimation accuracies up to 92%, for different classification models such as RandomForest (RF), Feedforward Neural Networks (FNN), and Graph Neural Networks (GNN).
Label Augmentation with Reinforced Labeling for Weak Supervision
Apr 13, 2022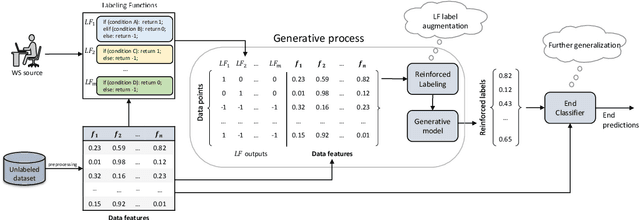
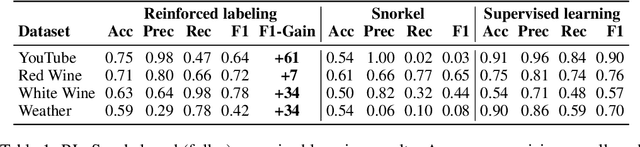
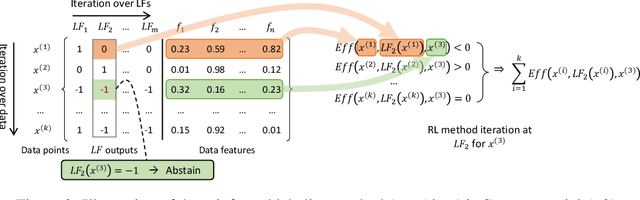

Weak supervision (WS) is an alternative to the traditional supervised learning to address the need for ground truth. Data programming is a practical WS approach that allows programmatic labeling data samples using labeling functions (LFs) instead of hand-labeling each data point. However, the existing approach fails to fully exploit the domain knowledge encoded into LFs, especially when the LFs' coverage is low. This is due to the common data programming pipeline that neglects to utilize data features during the generative process. This paper proposes a new approach called reinforced labeling (RL). Given an unlabeled dataset and a set of LFs, RL augments the LFs' outputs to cases not covered by LFs based on similarities among samples. Thus, RL can lead to higher labeling coverage for training an end classifier. The experiments on several domains (classification of YouTube comments, wine quality, and weather prediction) result in considerable gains. The new approach produces significant performance improvement, leading up to +21 points in accuracy and +61 points in F1 scores compared to the state-of-the-art data programming approach.