 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT: Multi Robot Energy-Aware Orchestrator for Indoor Search and Rescue Critical Tasks
Mar 07, 2025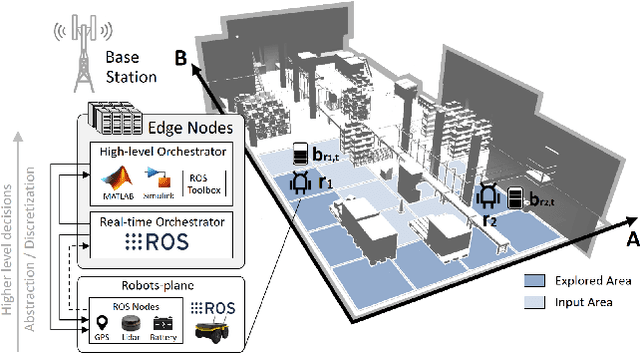

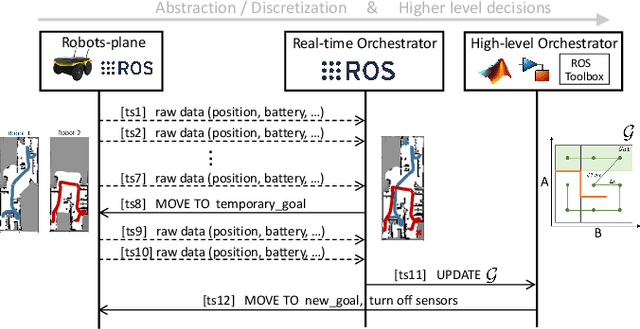
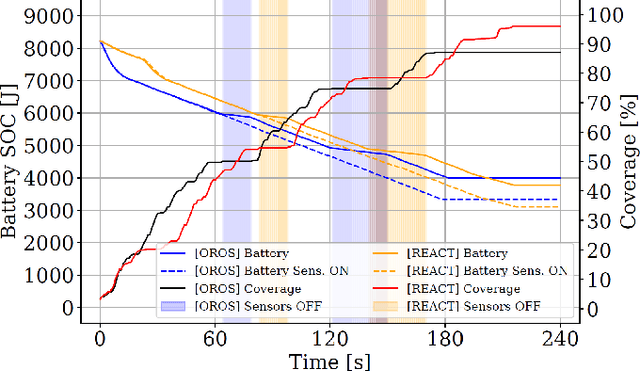
Smart factories enhance production efficiency and sustainability, but emergencies like human errors, machinery failures and natural disasters pose significant risks. In critical situations, such as fires or earthquakes, collaborative robots can assist first-responders by entering damaged buildings and locating missing persons, mitigating potential losses. Unlike previous solutions that overlook the critical aspect of energy management, in this paper we propose REACT, a smart energy-aware orchestrator that optimizes the exploration phase, ensuring prolonged operational time and effective area coverage. Our solution leverages a fleet of collaborative robots equipped with advanced sensors and communication capabilities to explore and navigate unknown indoor environments, such as smart factories affected by fires or earthquakes, with high density of obstacles. By leveraging real-time data exchange and cooperative algorithms, the robots dynamically adjust their paths, minimize redundant movements and reduce energy consumption. Extensive simulations confirm that our approach significantly improves the efficiency and reliability of search and rescue missions in complex indoor environments, improving the exploration rate by 10% over existing methods and reaching a map coverage of 97% under time critical operations, up to nearly 100% under relaxed time constraint.
Are you a robot? Detecting Autonomous Vehicles from Behavior Analysis
Mar 14, 2024



The tremendous hype around autonomous driving is eagerly calling for emerging and novel technologies to support advanced mobility use cases. As car manufactures keep developing SAE level 3+ systems to improve the safety and comfort of passengers, traffic authorities need to establish new procedures to manage the transition from human-driven to fully-autonomous vehicles while providing a feedback-loop mechanism to fine-tune envisioned autonomous systems. Thus, a way to automatically profile autonomous vehicles and differentiate those from human-driven ones is a must. In this paper, we present a fully-fledged framework that monitors active vehicles using camera images and state information in order to determine whether vehicles are autonomous, without requiring any active notification from the vehicles themselves. Essentially, it builds on the cooperation among vehicles, which share their data acquired on the road feeding a machine learning model to identify autonomous cars. We extensively tested our solution and created the NexusStreet dataset, by means of the CARLA simulator, employing an autonomous driving control agent and a steering wheel maneuvered by licensed drivers. Experiments show it is possible to discriminate the two behaviors by analyzing video clips with an accuracy of 80%, which improves up to 93% when the target state information is available. Lastly, we deliberately degraded the state to observe how the framework performs under non-ideal data collection conditions.
Label Augmentation with Reinforced Labeling for Weak Supervision
Apr 13, 2022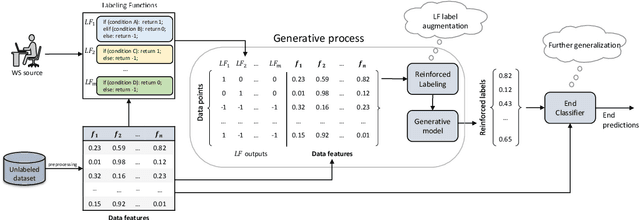
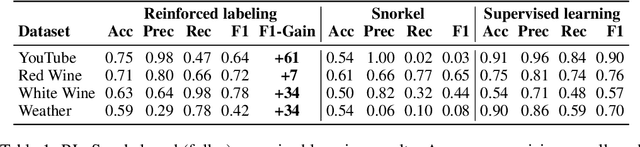
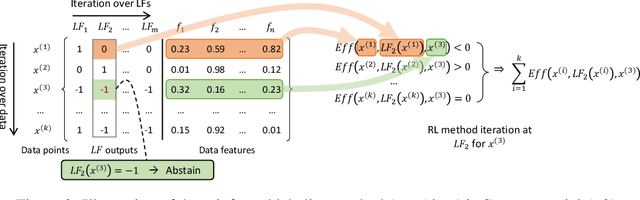

Weak supervision (WS) is an alternative to the traditional supervised learning to address the need for ground truth. Data programming is a practical WS approach that allows programmatic labeling data samples using labeling functions (LFs) instead of hand-labeling each data point. However, the existing approach fails to fully exploit the domain knowledge encoded into LFs, especially when the LFs' coverage is low. This is due to the common data programming pipeline that neglects to utilize data features during the generative process. This paper proposes a new approach called reinforced labeling (RL). Given an unlabeled dataset and a set of LFs, RL augments the LFs' outputs to cases not covered by LFs based on similarities among samples. Thus, RL can lead to higher labeling coverage for training an end classifier. The experiments on several domains (classification of YouTube comments, wine quality, and weather prediction) result in considerable gains. The new approach produces significant performance improvement, leading up to +21 points in accuracy and +61 points in F1 scores compared to the state-of-the-art data programming approach.