 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Large Language Models for Entity Matching
Sep 12, 2024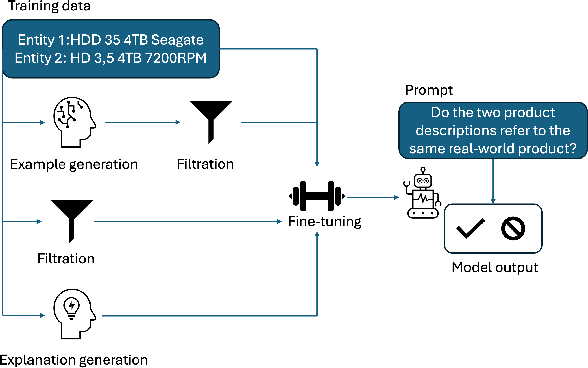
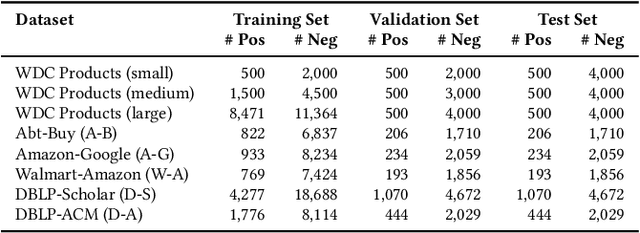

Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and their ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) The representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the model's ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o Mini.
Entity Matching using Large Language Models
Oct 17, 2023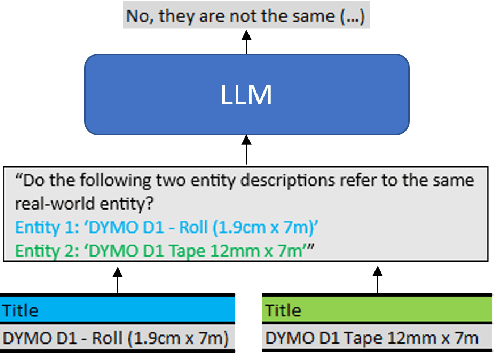
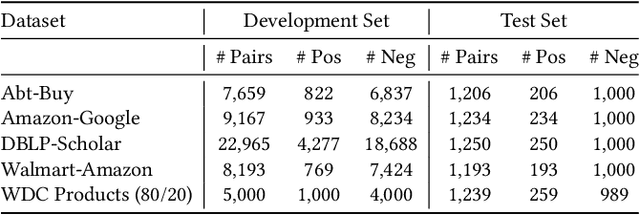
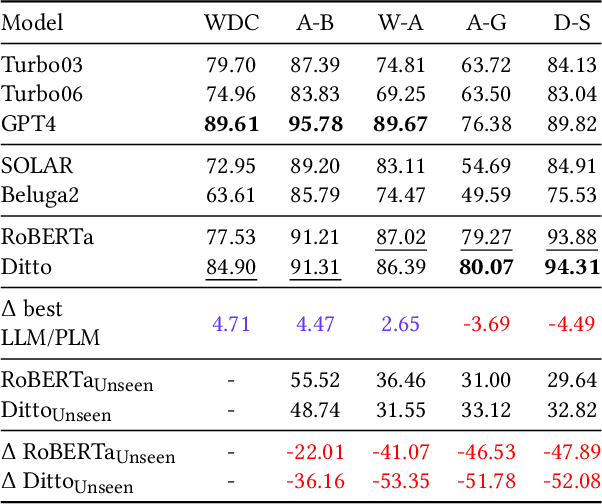

Entity Matching is the task of deciding whether two entity descriptions refer to the same real-world entity. Entity Matching is a central step in most data integration pipelines and an enabler for many e-commerce applications which require to match products offers from different vendors. State-of-the-art entity matching methods often rely on pre-trained language models (PLMs) such as BERT or RoBERTa. Two major drawbacks of these models for entity matching are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. In this paper, we investigate using large language models (LLMs) for entity matching as a less domain-specific training data reliant and more robust alternative to PLM-based matchers. Our study covers hosted LLMs, such as GPT3.5 and GPT4, as well as open source LLMs based on Llama2 which can be run locally. We evaluate these models in a zero-shot scenario as well as a scenario where task-specific training data is available. We compare different prompt designs as well as the prompt sensitivity of the models in the zero-shot scenario. We investigate (i) the selection of in-context demonstrations, (ii) the generation of matching rules, as well as (iii) fine-tuning GPT3.5 in the second scenario using the same pool of training data across the different approaches. Our experiments show that GPT4 without any task-specific training data outperforms fine-tuned PLMs (RoBERTa and Ditto) on three out of five benchmark datasets reaching F1 scores around 90%. The experiments with in-context learning and rule generation show that all models beside of GPT4 benefit from these techniques (on average 5.9% and 2.2% F1), while GPT4 does not need such additional guidance in most cases...
Using ChatGPT for Entity Matching
May 05, 2023Entity Matching is the task of deciding if two entity descriptions refer to the same real-world entity. State-of-the-art entity matching methods often rely on fine-tuning Transformer models such as BERT or RoBERTa. Two major drawbacks of using these models for entity matching are that (i) the models require significant amounts of fine-tuning data for reaching a good performance and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. In this paper, we investigate using ChatGPT for entity matching as a more robust, training data-efficient alternative to traditional Transformer models. We perform experiments along three dimensions: (i) general prompt design, (ii) in-context learning, and (iii) provision of higher-level matching knowledge. We show that ChatGPT is competitive with a fine-tuned RoBERTa model, reaching an average zero-shot performance of 83% F1 on a challenging matching task on which RoBERTa requires 2000 training examples for reaching a similar performance. Adding in-context demonstrations to the prompts further improves the F1 by up to 5% even using only a small set of 20 handpicked examples. Finally, we show that guiding the zero-shot model by stating higher-level matching rules leads to similar gains as providing in-context examples.
WDC Products: A Multi-Dimensional Entity Matching Benchmark
Jan 23, 2023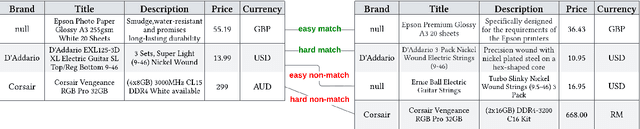
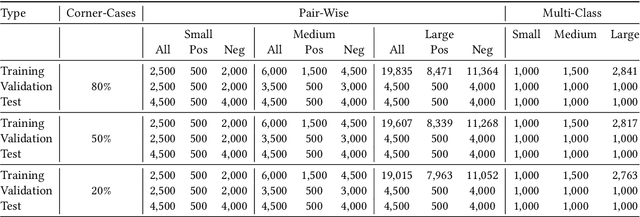
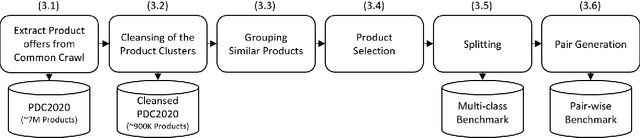
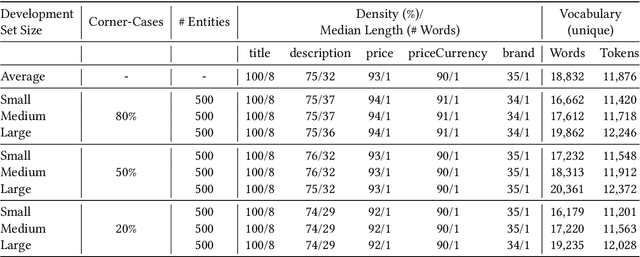
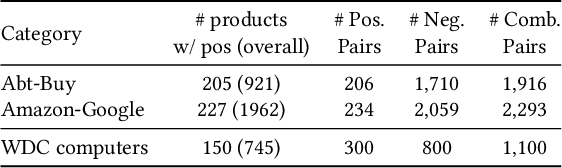
The difficulty of an entity matching task depends on a combination of multiple factors such as the amount of corner-case pairs, the fraction of entities in the test set that have not been seen during training, and the size of the development set. Current entity matching benchmarks usually represent single points in the space along such dimensions or they provide for the evaluation of matching methods along a single dimension, for instance the amount of training data. This paper presents WDC Products, an entity matching benchmark which provides for the systematic evaluation of matching systems along combinations of three dimensions while relying on real-word data. The three dimensions are (i) amount of corner-cases (ii) generalization to unseen entities, and (iii) development set size. Generalization to unseen entities is a dimension not covered by any of the existing benchmarks yet but is crucial for evaluating the robustness of entity matching systems. WDC Products is based on heterogeneous product data from thousands of e-shops which mark-up products offers using schema.org annotations. Instead of learning how to match entity pairs, entity matching can also be formulated as a multi-class classification task that requires the matcher to recognize individual entities. WDC Products is the first benchmark that provides a pair-wise and a multi-class formulation of the same tasks and thus allows to directly compare the two alternatives. We evaluate WDC Products using several state-of-the-art matching systems, including Ditto, HierGAT, and R-SupCon. The evaluation shows that all matching systems struggle with unseen entities to varying degrees. It also shows that some systems are more training data efficient than others.
Supervised Contrastive Learning for Product Matching
Feb 04, 2022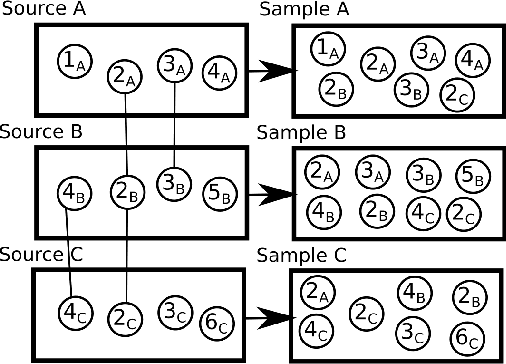
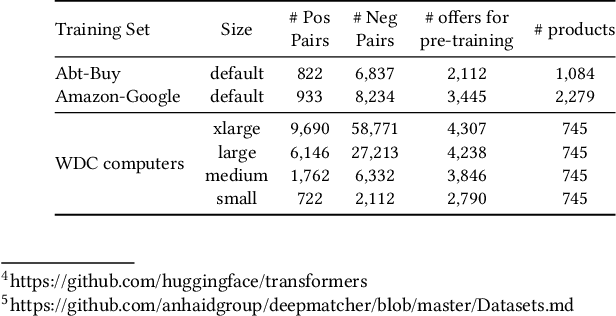
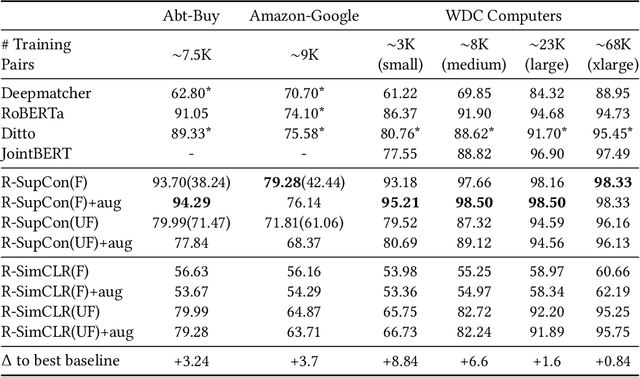
Contrastive learning has seen increasing success in the fields of computer vision and information retrieval in recent years. This poster is the first work that applies contrastive learning to the task of product matching in e-commerce using product offers from different e-shops. More specifically, we employ a supervised contrastive learning technique to pre-train a Transformer encoder which is afterwards fine-tuned for the matching problem using pair-wise training data. We further propose a source-aware sampling strategy which enables contrastive learning to be applied for use cases in which the training data does not contain product idenifiers. We show that applying supervised contrastive pre-training in combination with source-aware sampling significantly improves the state-of-the art performance on several widely used benchmark datasets: For Abt-Buy, we reach an F1 of 94.29 (+3.24 compared to the previous state-of-the-art), for Amazon-Google 79.28 (+ 3.7). For WDC Computers datasets, we reach improvements between +0.8 and +8.84 F1 depending on the training set size. Further experiments with data augmentation and self-supervised contrastive pre-training show, that the former can be helpful for smaller training sets while the latter leads to a significant decline in performance due to inherent label-noise. We thus conclude that contrastive pre-training has a high potential for product matching use cases in which explicit supervision is available.
Cross-Language Learning for Entity Matching
Oct 07, 2021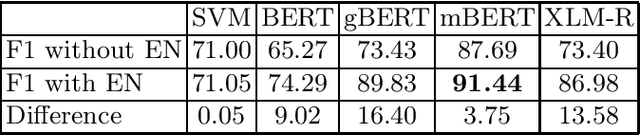
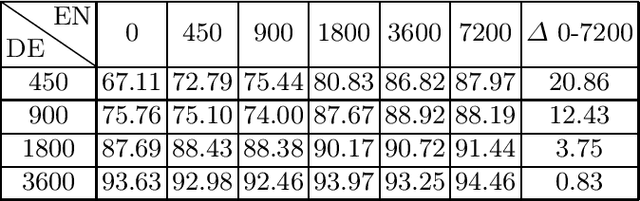
Transformer-based matching methods have significantly moved the state-of-the-art for less-structured matching tasks involving textual entity descriptions. In order to excel on these tasks, Transformer-based matching methods require a decent amount of training pairs. Providing enough training data can be challenging, especially if a matcher for non-English entity descriptions should be learned. This paper explores along the use case of matching product offers from different e-shops to which extent it is possible to improve the performance of Transformer-based entity matchers by complementing a small set of training pairs in the target language, German in our case, with a larger set of English-language training pairs. Our experiments using different Transformers show that extending the German set with English pairs is always beneficial. The impact of adding the English pairs is especially high in low-resource settings in which only a rather small number of non-English pairs is available. As it is often possible to automatically gather English training pairs from the Web by using schema.org annotations, our results could proof relevant for many product matching scenarios targeting low-resource languages.