 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Language Learning for Entity Matching
Paper and Code
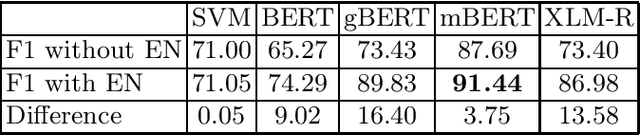
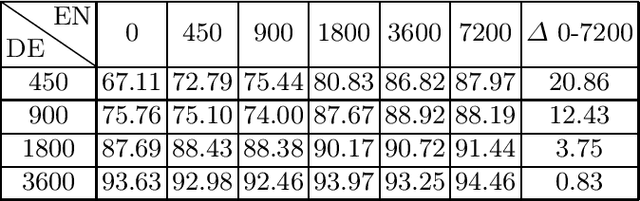
Transformer-based matching methods have significantly moved the state-of-the-art for less-structured matching tasks involving textual entity descriptions. In order to excel on these tasks, Transformer-based matching methods require a decent amount of training pairs. Providing enough training data can be challenging, especially if a matcher for non-English entity descriptions should be learned. This paper explores along the use case of matching product offers from different e-shops to which extent it is possible to improve the performance of Transformer-based entity matchers by complementing a small set of training pairs in the target language, German in our case, with a larger set of English-language training pairs. Our experiments using different Transformers show that extending the German set with English pairs is always beneficial. The impact of adding the English pairs is especially high in low-resource settings in which only a rather small number of non-English pairs is available. As it is often possible to automatically gather English training pairs from the Web by using schema.org annotations, our results could proof relevant for many product matching scenarios targeting low-resource languages.