 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduct Information Extraction using ChatGPT
Jun 23, 2023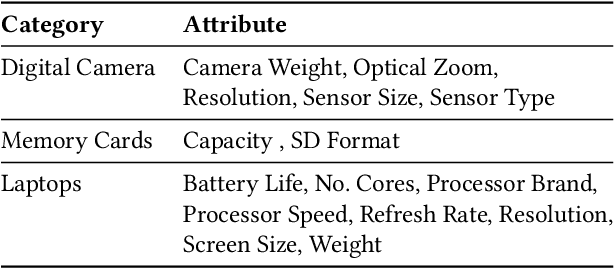
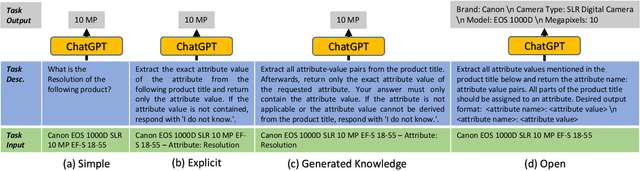
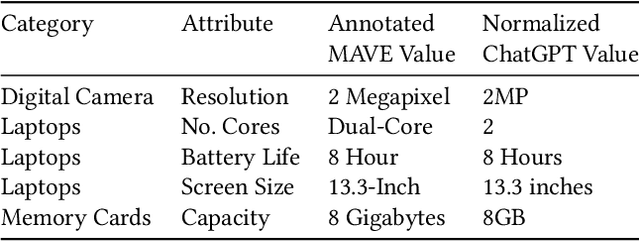
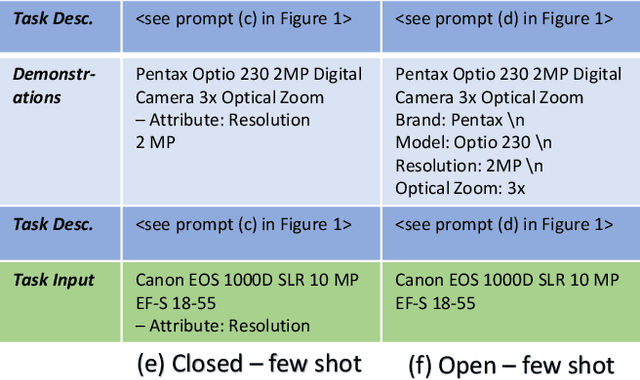
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
WDC Products: A Multi-Dimensional Entity Matching Benchmark
Jan 23, 2023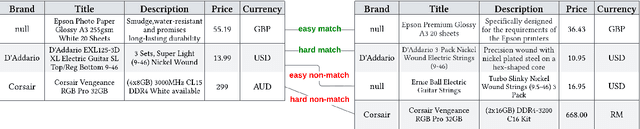
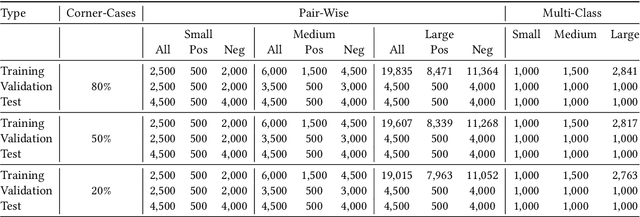
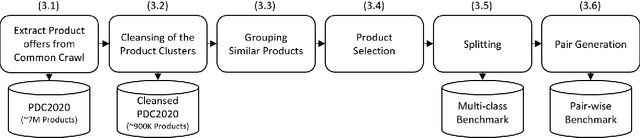
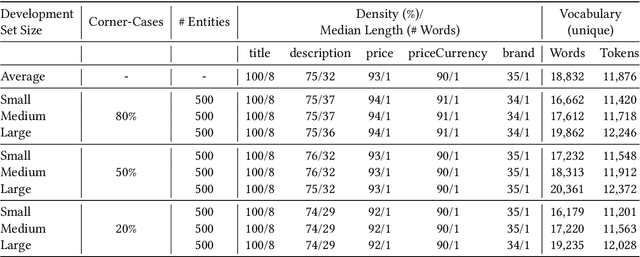
The difficulty of an entity matching task depends on a combination of multiple factors such as the amount of corner-case pairs, the fraction of entities in the test set that have not been seen during training, and the size of the development set. Current entity matching benchmarks usually represent single points in the space along such dimensions or they provide for the evaluation of matching methods along a single dimension, for instance the amount of training data. This paper presents WDC Products, an entity matching benchmark which provides for the systematic evaluation of matching systems along combinations of three dimensions while relying on real-word data. The three dimensions are (i) amount of corner-cases (ii) generalization to unseen entities, and (iii) development set size. Generalization to unseen entities is a dimension not covered by any of the existing benchmarks yet but is crucial for evaluating the robustness of entity matching systems. WDC Products is based on heterogeneous product data from thousands of e-shops which mark-up products offers using schema.org annotations. Instead of learning how to match entity pairs, entity matching can also be formulated as a multi-class classification task that requires the matcher to recognize individual entities. WDC Products is the first benchmark that provides a pair-wise and a multi-class formulation of the same tasks and thus allows to directly compare the two alternatives. We evaluate WDC Products using several state-of-the-art matching systems, including Ditto, HierGAT, and R-SupCon. The evaluation shows that all matching systems struggle with unseen entities to varying degrees. It also shows that some systems are more training data efficient than others.