 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3dSAGER: Geospatial Entity Resolution over 3D Objects (Technical Report)
Nov 09, 2025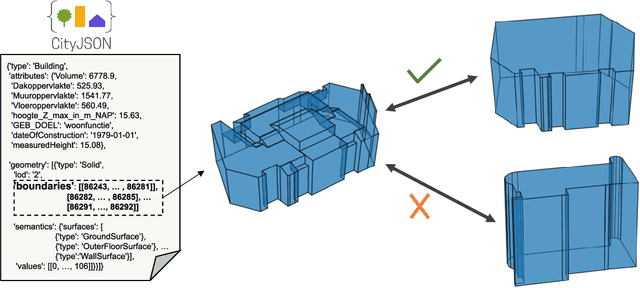
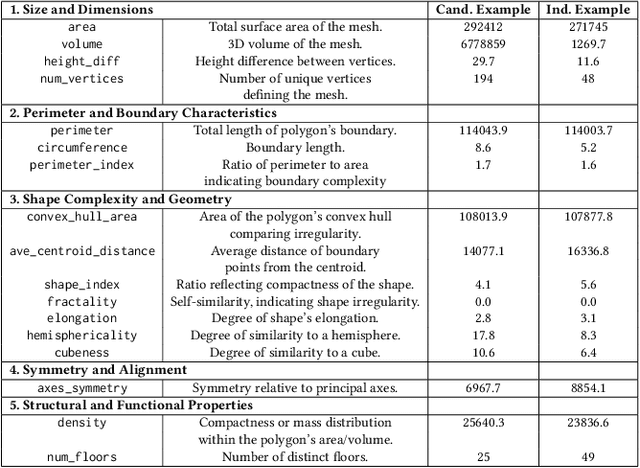
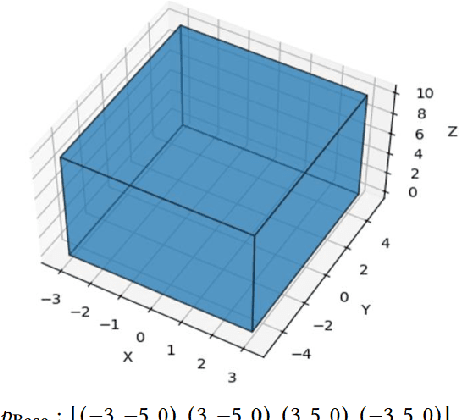
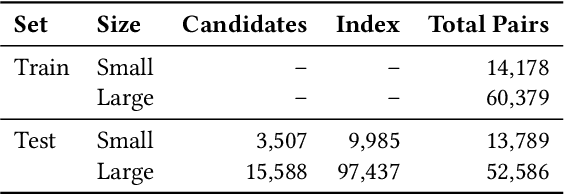
Urban environments are continuously mapped and modeled by various data collection platforms, including satellites, unmanned aerial vehicles and street cameras. The growing availability of 3D geospatial data from multiple modalities has introduced new opportunities and challenges for integrating spatial knowledge at scale, particularly in high-impact domains such as urban planning and rapid disaster management. Geospatial entity resolution is the task of identifying matching spatial objects across different datasets, often collected independently under varying conditions. Existing approaches typically rely on spatial proximity, textual metadata, or external identifiers to determine correspondence. While useful, these signals are often unavailable, unreliable, or misaligned, especially in cross-source scenarios. To address these limitations, we shift the focus to the intrinsic geometry of 3D spatial objects and present 3dSAGER (3D Spatial-Aware Geospatial Entity Resolution), an end-to-end pipeline for geospatial entity resolution over 3D objects. 3dSAGER introduces a novel, spatial-reference-independent featurization mechanism that captures intricate geometric characteristics of matching pairs, enabling robust comparison even across datasets with incompatible coordinate systems where traditional spatial methods fail. As a key component of 3dSAGER, we also propose a new lightweight and interpretable blocking method, BKAFI, that leverages a trained model to efficiently generate high-recall candidate sets. We validate 3dSAGER through extensive experiments on real-world urban datasets, demonstrating significant gains in both accuracy and efficiency over strong baselines. Our empirical study further dissects the contributions of each component, providing insights into their impact and the overall design choices.
DDTR: Diffusion Denoising Trace Recovery
Oct 26, 2025With recent technological advances, process logs, which were traditionally deterministic in nature, are being captured from non-deterministic sources, such as uncertain sensors or machine learning models (that predict activities using cameras). In the presence of stochastically-known logs, logs that contain probabilistic information, the need for stochastic trace recovery increases, to offer reliable means of understanding the processes that govern such systems. We design a novel deep learning approach for stochastic trace recovery, based on Diffusion Denoising Probabilistic Models (DDPM), which makes use of process knowledge (either implicitly by discovering a model or explicitly by injecting process knowledge in the training phase) to recover traces by denoising. We conduct an empirical evaluation demonstrating state-of-the-art performance with up to a 25% improvement over existing methods, along with increased robustness under high noise levels.
MISFEAT: Feature Selection for Subgroups with Systematic Missing Data
Dec 09, 2024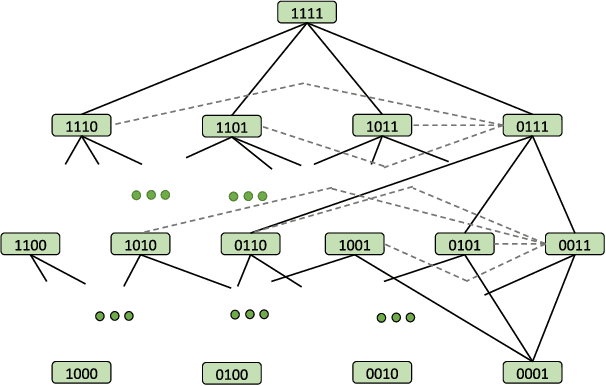
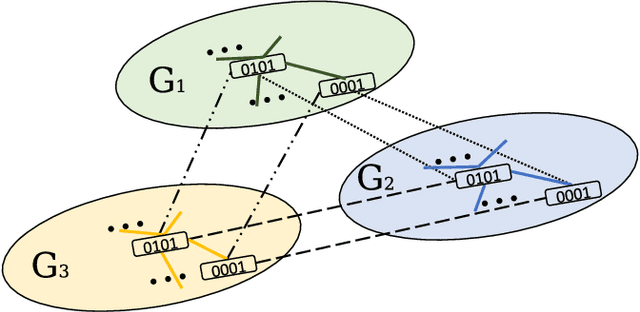
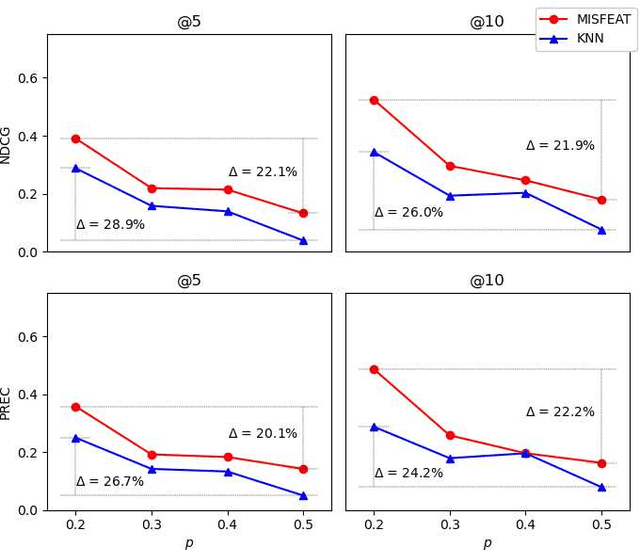
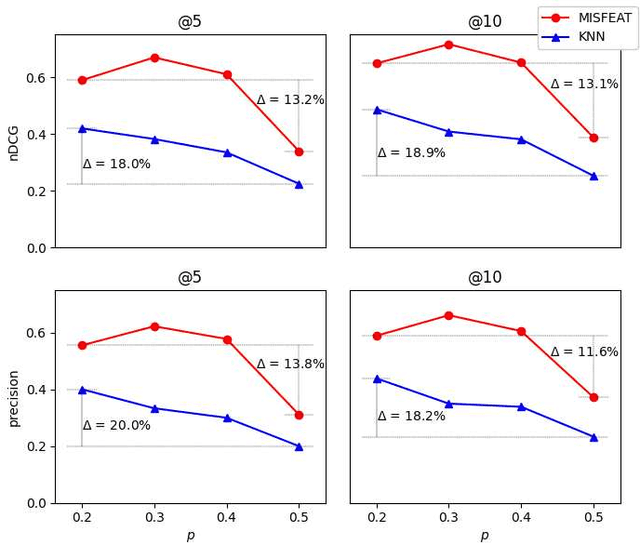
We investigate the problem of selecting features for datasets that can be naturally partitioned into subgroups (e.g., according to socio-demographic groups and age), each with its own dominant set of features. Within this subgroup-oriented framework, we address the challenge of systematic missing data, a scenario in which some feature values are missing for all tuples of a subgroup, due to flawed data integration, regulatory constraints, or privacy concerns. Feature selection is governed by finding mutual Information, a popular quantification of correlation, between features and a target variable. Our goal is to identify top-K feature subsets of some fixed size with the highest joint mutual information with a target variable. In the presence of systematic missing data, the closed form of mutual information could not simply be applied. We argue that in such a setting, leveraging relationships between available feature mutual information within a subgroup or across subgroups can assist inferring missing mutual information values. We propose a generalizable model based on heterogeneous graph neural network to identify interdependencies between feature-subgroup-target variable connections by modeling it as a multiplex graph, and employing information propagation between its nodes. We address two distinct scalability challenges related to training and propose principled solutions to tackle them. Through an extensive empirical evaluation, we demonstrate the efficacy of the proposed solutions both qualitatively and running time wise.
A Scalable and Near-Optimal Conformance Checking Approach for Long Traces
Jun 08, 2024Long traces and large event logs that originate from sensors and prediction models are becoming more common in our data-rich world. In such circumstances, conformance checking, a key task in process mining, can become computationally infeasible due to the exponential complexity of finding an optimal alignment. This paper introduces a novel sliding window approach to address these scalability challenges while preserving the interpretability of alignment-based methods. By breaking down traces into manageable subtraces and iteratively aligning each with the process model, our method significantly reduces the search space. The approach uses global information that captures structural properties of the trace and the process model to make informed alignment decisions, discarding unpromising alignments even if they are optimal for a local subtrace. This improves the overall accuracy of the results. Experimental evaluations demonstrate that the proposed method consistently finds optimal alignments in most cases and highlight its scalability. This is further supported by a theoretical complexity analysis, which shows the reduced growth of the search space compared to other common conformance checking methods. This work provides a valuable contribution towards efficient conformance checking for large-scale process mining applications.
The Battleship Approach to the Low Resource Entity Matching Problem
Nov 27, 2023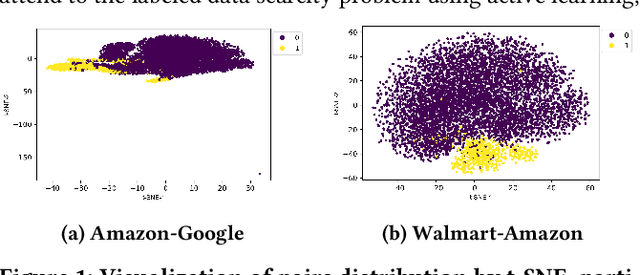


Entity matching, a core data integration problem, is the task of deciding whether two data tuples refer to the same real-world entity. Recent advances in deep learning methods, using pre-trained language models, were proposed for resolving entity matching. Although demonstrating unprecedented results, these solutions suffer from a major drawback as they require large amounts of labeled data for training, and, as such, are inadequate to be applied to low resource entity matching problems. To overcome the challenge of obtaining sufficient labeled data we offer a new active learning approach, focusing on a selection mechanism that exploits unique properties of entity matching. We argue that a distributed representation of a tuple pair indicates its informativeness when considered among other pairs. This is used consequently in our approach that iteratively utilizes space-aware considerations. Bringing it all together, we treat the low resource entity matching problem as a Battleship game, hunting indicative samples, focusing on positive ones, through awareness of the latent space along with careful planning of next sampling iterations. An extensive experimental analysis shows that the proposed algorithm outperforms state-of-the-art active learning solutions to low resource entity matching, and although using less samples, can be as successful as state-of-the-art fully trained known algorithms.
Trace Recovery from Stochastically Known Logs
Jun 25, 2022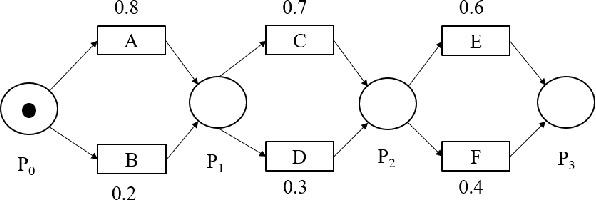

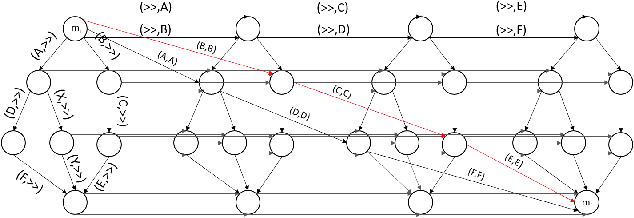
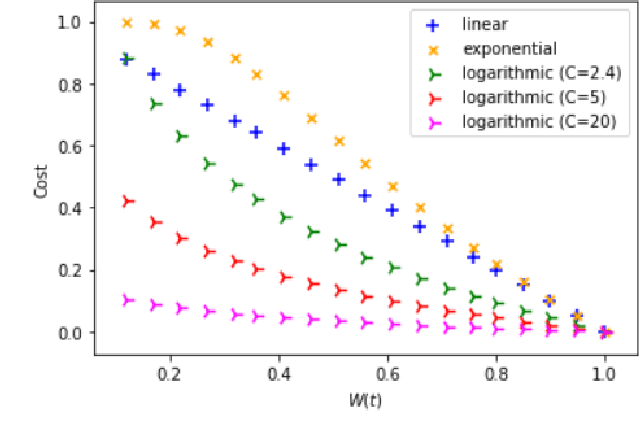
In this work we propose an algorithm for trace recovery from stochastically known logs, a setting that is becoming more common with the increasing number of sensors and predictive models that generate uncertain data. The suggested approach calculates the conformance between a process model and a stochastically known trace and recovers the best alignment within this stochastic trace as the true trace. The paper offers an analysis of the impact of various cost models on trace recovery accuracy and makes use of a product multi-graph to compare alternative trace recovery options. The average accuracy of our approach, evaluated using two publicly available datasets, is impressive, with an average recovery accuracy score of 90-97%, significantly improving a common heuristic that chooses the most likely value for each uncertain activity. We believe that the effectiveness of the proposed algorithm in recovering correct traces from stochastically known logs may be a powerful aid for developing credible decision-making tools in uncertain settings.
Human's Role in-the-Loop
Apr 27, 2022


Data integration has been recently challenged by the need to handle large volumes of data, arriving at high velocity from a variety of sources, which demonstrate varying levels of veracity. This challenging setting, often referred to as big data, renders many of the existing techniques, especially those that are human-intensive, obsolete. Big data also produces technological advancements such as Internet of things, cloud computing, and deep learning, and accordingly, provides a new, exciting, and challenging research agenda. Given the availability of data and the improvement of machine learning techniques, this blog discusses the respective roles of humans and machines in achieving cognitive tasks in matching, aiming to determine whether traditional roles of humans and machines are subject to change. Such investigation, we believe, will pave a way to better utilize both human and machine resources in new and innovative manners. We shall discuss two possible modes of change, namely humans out and humans in. Humans out aim at exploring out-of-the-box latent matching reasoning using machine learning algorithms when attempting to overpower human matcher performance. Pursuing out-of-the-box thinking, machine and deep learning can be involved in matching. Humans in explores how to better involve humans in the matching loop by assigning human matchers with a symmetric role to algorithmic matcher in the matching process.
From Limited Annotated Raw Material Data to Quality Production Data: A Case Study in the Milk Industry
Apr 26, 2022
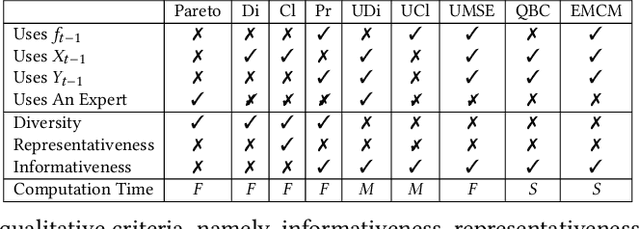
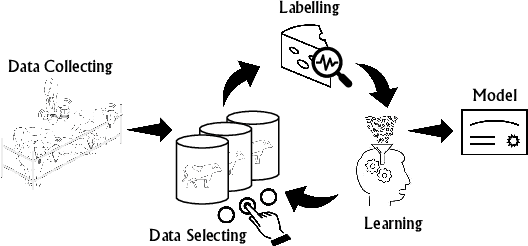
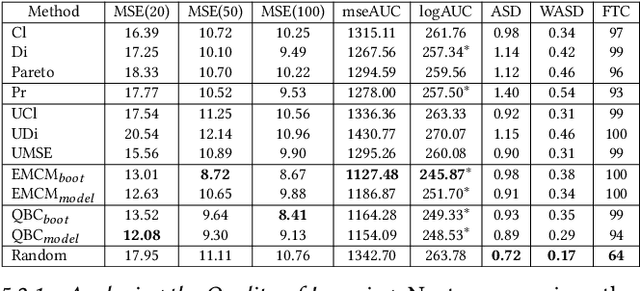
Industry 4.0 offers opportunities to combine multiple sensor data sources using IoT technologies for better utilization of raw material in production lines. A common belief that data is readily available (the big data phenomenon), is oftentimes challenged by the need to effectively acquire quality data under severe constraints. In this paper we propose a design methodology, using active learning to enhance learning capabilities, for building a model of production outcome using a constrained amount of raw material training data. The proposed methodology extends existing active learning methods to effectively solve regression-based learning problems and may serve settings where data acquisition requires excessive resources in the physical world. We further suggest a set of qualitative measures to analyze learners performance. The proposed methodology is demonstrated using an actual application in the milk industry, where milk is gathered from multiple small milk farms and brought to a dairy production plant to be processed into cottage cheese.
Conformance Checking Over Stochastically Known Logs
Mar 14, 2022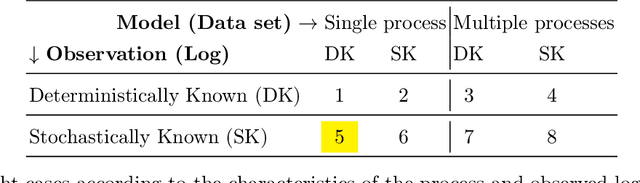
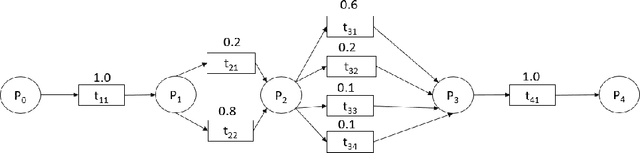

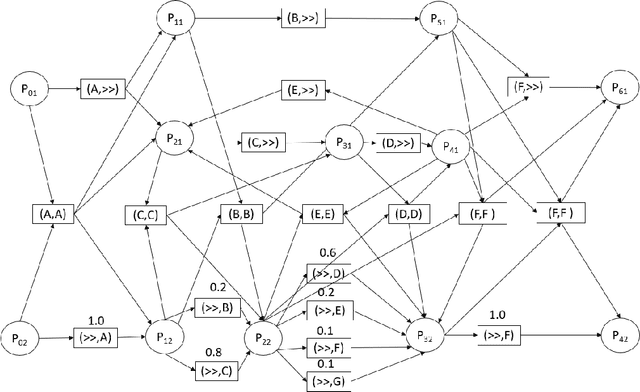
With the growing number of devices, sensors and digital systems, data logs may become uncertain due to, e.g., sensor reading inaccuracies or incorrect interpretation of readings by processing programs. At times, such uncertainties can be captured stochastically, especially when using probabilistic data classification models. In this work we focus on conformance checking, which compares a process model with an event log, when event logs are stochastically known. Building on existing alignment-based conformance checking fundamentals, we mathematically define a stochastic trace model, a stochastic synchronous product, and a cost function that reflects the uncertainty of events in a log. Then, we search for an optimal alignment over the reachability graph of the stochastic synchronous product for finding an optimal alignment between a model and a stochastic process observation. Via structured experiments with two well-known process mining benchmarks, we explore the behavior of the suggested stochastic conformance checking approach and compare it to a standard alignment-based approach as well as to an approach that creates a lower bound on performance. We envision the proposed stochastic conformance checking approach as a viable process mining component for future analysis of stochastic event logs.
Augmented Business Process Management Systems: A Research Manifesto
Feb 03, 2022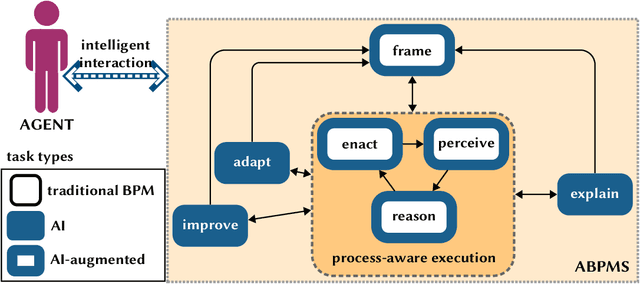
Augmented Business Process Management Systems (ABPMSs) are an emerging class of process-aware information systems that draws upon trustworthy AI technology. An ABPMS enhances the execution of business processes with the aim of making these processes more adaptable, proactive, explainable, and context-sensitive. This manifesto presents a vision for ABPMSs and discusses research challenges that need to be surmounted to realize this vision. To this end, we define the concept of ABPMS, we outline the lifecycle of processes within an ABPMS, we discuss core characteristics of an ABPMS, and we derive a set of challenges to realize systems with these characteristics.