 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISFEAT: Feature Selection for Subgroups with Systematic Missing Data
Dec 09, 2024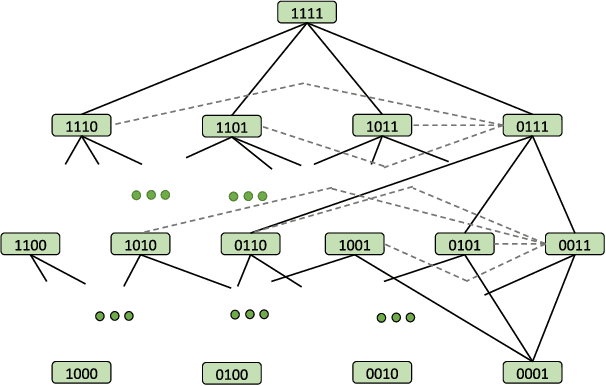
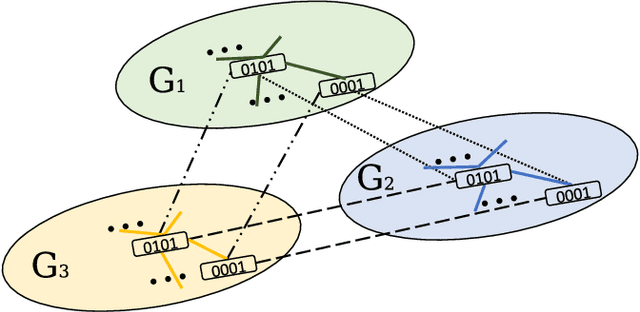
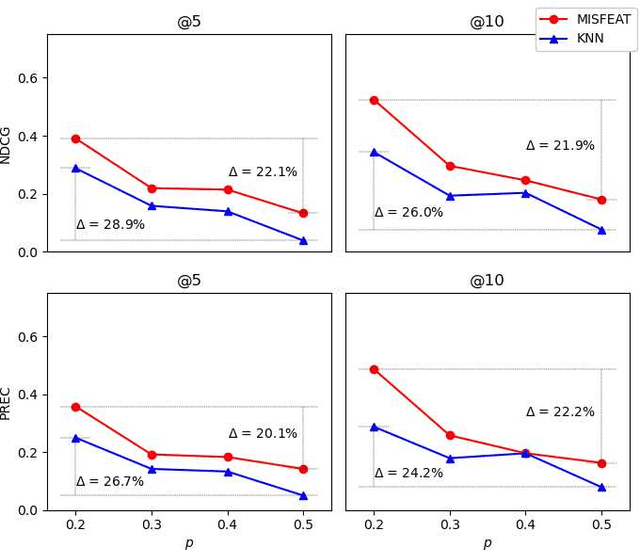
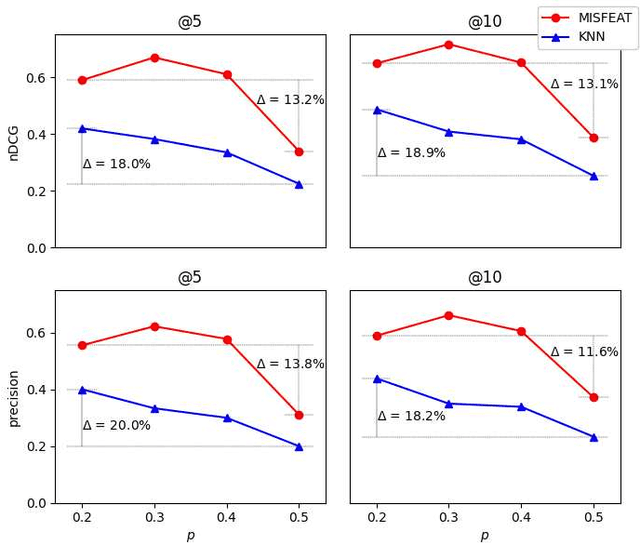
We investigate the problem of selecting features for datasets that can be naturally partitioned into subgroups (e.g., according to socio-demographic groups and age), each with its own dominant set of features. Within this subgroup-oriented framework, we address the challenge of systematic missing data, a scenario in which some feature values are missing for all tuples of a subgroup, due to flawed data integration, regulatory constraints, or privacy concerns. Feature selection is governed by finding mutual Information, a popular quantification of correlation, between features and a target variable. Our goal is to identify top-K feature subsets of some fixed size with the highest joint mutual information with a target variable. In the presence of systematic missing data, the closed form of mutual information could not simply be applied. We argue that in such a setting, leveraging relationships between available feature mutual information within a subgroup or across subgroups can assist inferring missing mutual information values. We propose a generalizable model based on heterogeneous graph neural network to identify interdependencies between feature-subgroup-target variable connections by modeling it as a multiplex graph, and employing information propagation between its nodes. We address two distinct scalability challenges related to training and propose principled solutions to tackle them. Through an extensive empirical evaluation, we demonstrate the efficacy of the proposed solutions both qualitatively and running time wise.