 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Curation Using Agentic AI
Jan 30, 2026Data annotation is essential for supervised learning, yet producing accurate, unbiased, and scalable labels remains challenging as datasets grow in size and modality. Traditional human-centric pipelines are costly, slow, and prone to annotator variability, motivating reliability-aware automated annotation. We present AURA (Agentic AI for Unified Reliability Modeling and Annotation Aggregation), an agentic AI framework for large-scale, multi-modal data annotation. AURA coordinates multiple AI agents to generate and validate labels without requiring ground truth. At its core, AURA adapts a classical probabilistic model that jointly infers latent true labels and annotator reliability via confusion matrices, using Expectation-Maximization to reconcile conflicting annotations and aggregate noisy predictions. Across the four benchmark datasets evaluated, AURA achieves accuracy improvements of up to 5.8% over baseline. In more challenging settings with poor quality annotators, the improvement is up to 50% over baseline. AURA also accurately estimates the reliability of annotators, allowing assessment of annotator quality even without any pre-validation steps.
Continuous Fairness On Data Streams
Jan 13, 2026We study the problem of enforcing continuous group fairness over windows in data streams. We propose a novel fairness model that ensures group fairness at a finer granularity level (referred to as block) within each sliding window. This formulation is particularly useful when the window size is large, making it desirable to enforce fairness at a finer granularity. Within this framework, we address two key challenges: efficiently monitoring whether each sliding window satisfies block-level group fairness, and reordering the current window as effectively as possible when fairness is violated. To enable real-time monitoring, we design sketch-based data structures that maintain attribute distributions with minimal overhead. We also develop optimal, efficient algorithms for the reordering task, supported by rigorous theoretical guarantees. Our evaluation on four real-world streaming scenarios demonstrates the practical effectiveness of our approach. We achieve millisecond-level processing and a throughput of approximately 30,000 queries per second on average, depending on system parameters. The stream reordering algorithm improves block-level group fairness by up to 95% in certain cases, and by 50-60% on average across datasets. A qualitative study further highlights the advantages of block-level fairness compared to window-level fairness.
Personalized Top-k Set Queries Over Predicted Scores
Feb 18, 2025This work studies the applicability of expensive external oracles such as large language models in answering top-k queries over predicted scores. Such scores are incurred by user-defined functions to answer personalized queries over multi-modal data. We propose a generic computational framework that handles arbitrary set-based scoring functions, as long as the functions could be decomposed into constructs, each of which sent to an oracle (in our case an LLM) to predict partial scores. At a given point in time, the framework assumes a set of responses and their partial predicted scores, and it maintains a collection of possible sets that are likely to be the true top-k. Since calling oracles is costly, our framework judiciously identifies the next construct, i.e., the next best question to ask the oracle so as to maximize the likelihood of identifying the true top-k. We present a principled probabilistic model that quantifies that likelihood. We study efficiency opportunities in designing algorithms. We run an evaluation with three large scale datasets, scoring functions, and baselines. Experiments indicate the efficacy of our framework, as it achieves an order of magnitude improvement over baselines in requiring LLM calls while ensuring result accuracy. Scalability experiments further indicate that our framework could be used in large-scale applications.
MISFEAT: Feature Selection for Subgroups with Systematic Missing Data
Dec 09, 2024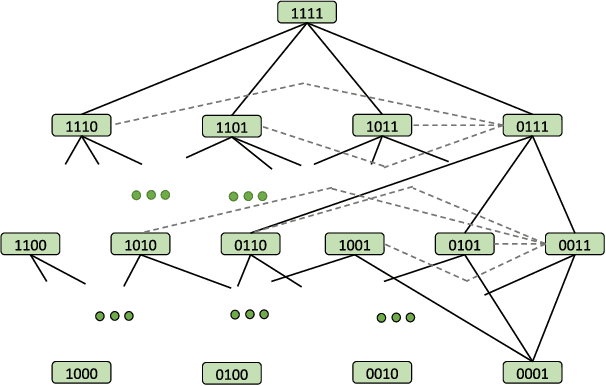
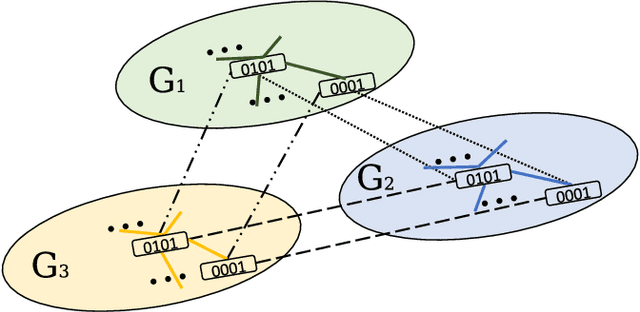
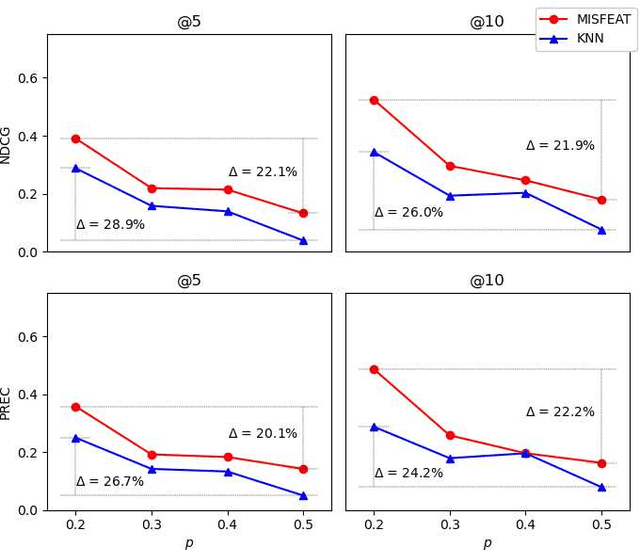
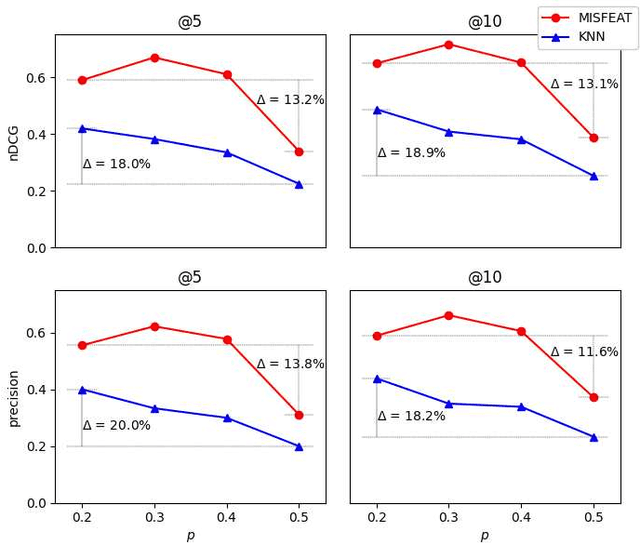
We investigate the problem of selecting features for datasets that can be naturally partitioned into subgroups (e.g., according to socio-demographic groups and age), each with its own dominant set of features. Within this subgroup-oriented framework, we address the challenge of systematic missing data, a scenario in which some feature values are missing for all tuples of a subgroup, due to flawed data integration, regulatory constraints, or privacy concerns. Feature selection is governed by finding mutual Information, a popular quantification of correlation, between features and a target variable. Our goal is to identify top-K feature subsets of some fixed size with the highest joint mutual information with a target variable. In the presence of systematic missing data, the closed form of mutual information could not simply be applied. We argue that in such a setting, leveraging relationships between available feature mutual information within a subgroup or across subgroups can assist inferring missing mutual information values. We propose a generalizable model based on heterogeneous graph neural network to identify interdependencies between feature-subgroup-target variable connections by modeling it as a multiplex graph, and employing information propagation between its nodes. We address two distinct scalability challenges related to training and propose principled solutions to tackle them. Through an extensive empirical evaluation, we demonstrate the efficacy of the proposed solutions both qualitatively and running time wise.
Eliciting Worker Preference for Task Completion
Jan 10, 2018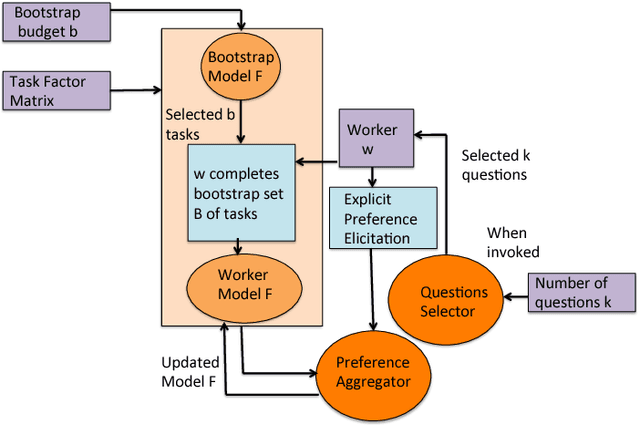
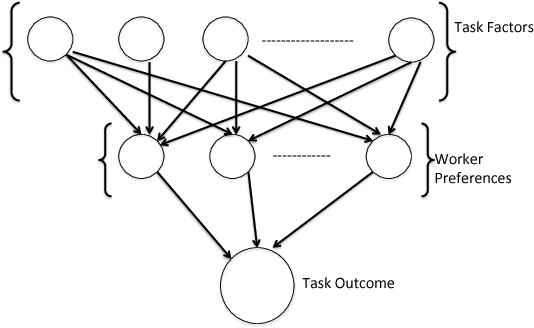
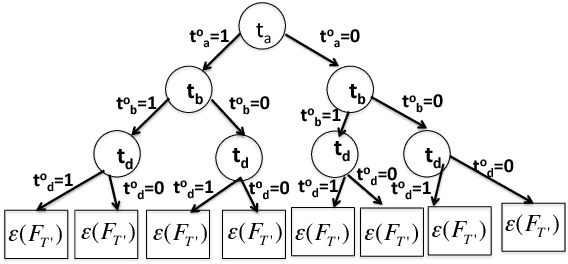
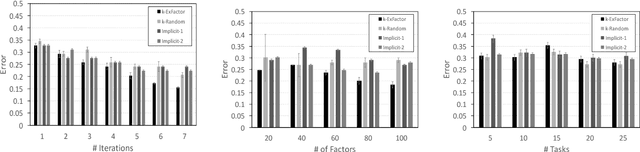
Current crowdsourcing platforms provide little support for worker feedback. Workers are sometimes invited to post free text describing their experience and preferences in completing tasks. They can also use forums such as Turker Nation1 to exchange preferences on tasks and requesters. In fact, crowdsourcing platforms rely heavily on observing workers and inferring their preferences implicitly. In this work, we believe that asking workers to indicate their preferences explicitly improve their experience in task completion and hence, the quality of their contributions. Explicit elicitation can indeed help to build more accurate worker models for task completion that captures the evolving nature of worker preferences. We design a worker model whose accuracy is improved iteratively by requesting preferences for task factors such as required skills, task payment, and task relevance. We propose a generic framework, develop efficient solutions in realistic scenarios, and run extensive experiments that show the benefit of explicit preference elicitation over implicit ones with statistical significance.
Feature Based Task Recommendation in Crowdsourcing with Implicit Observations
Sep 07, 2016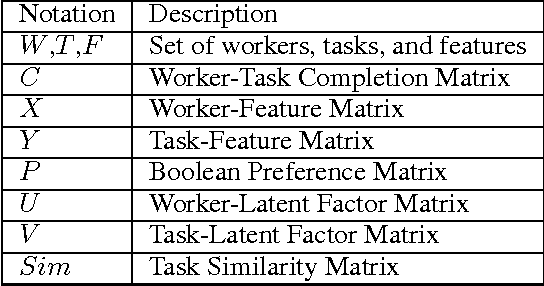
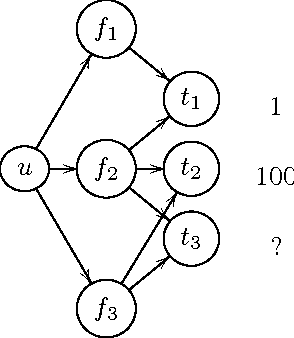
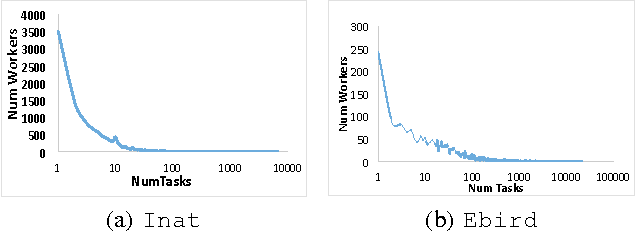
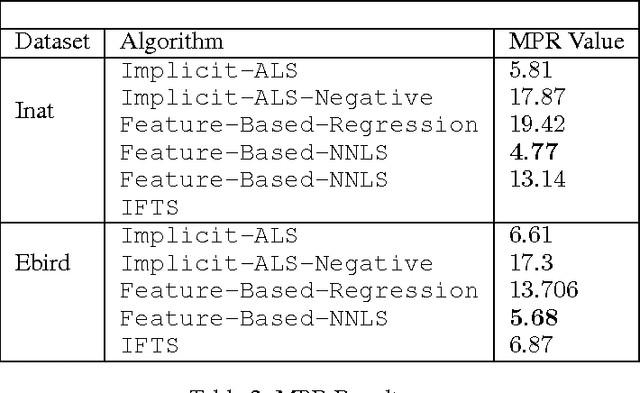
Existing research in crowdsourcing has investigated how to recommend tasks to workers based on which task the workers have already completed, referred to as {\em implicit feedback}. We, on the other hand, investigate the task recommendation problem, where we leverage both implicit feedback and explicit features of the task. We assume that we are given a set of workers, a set of tasks, interactions (such as the number of times a worker has completed a particular task), and the presence of explicit features of each task (such as, task location). We intend to recommend tasks to the workers by exploiting the implicit interactions, and the presence or absence of explicit features in the tasks. We formalize the problem as an optimization problem, propose two alternative problem formulations and respective solutions that exploit implicit feedback, explicit features, as well as similarity between the tasks. We compare the efficacy of our proposed solutions against multiple state-of-the-art techniques using two large scale real world datasets.
Predicting Risk-of-Readmission for Congestive Heart Failure Patients: A Multi-Layer Approach
Jun 10, 2013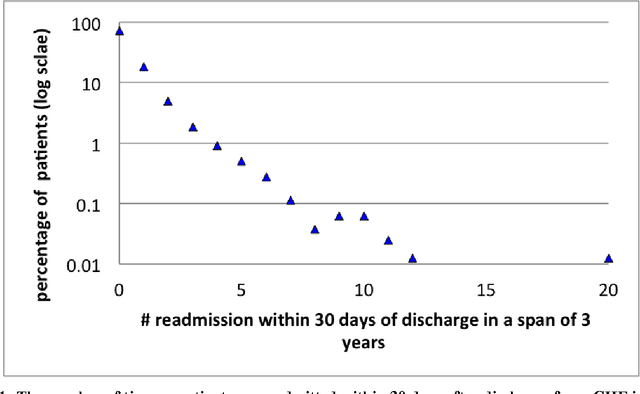

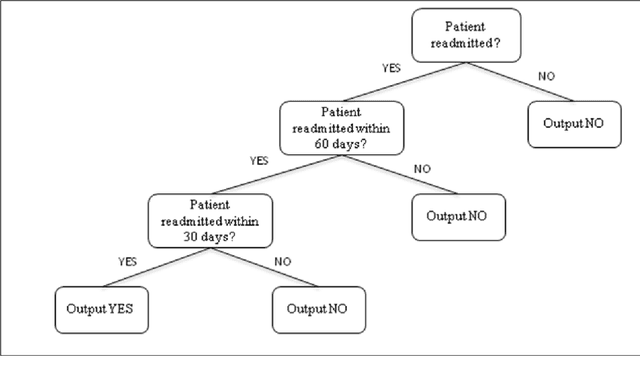
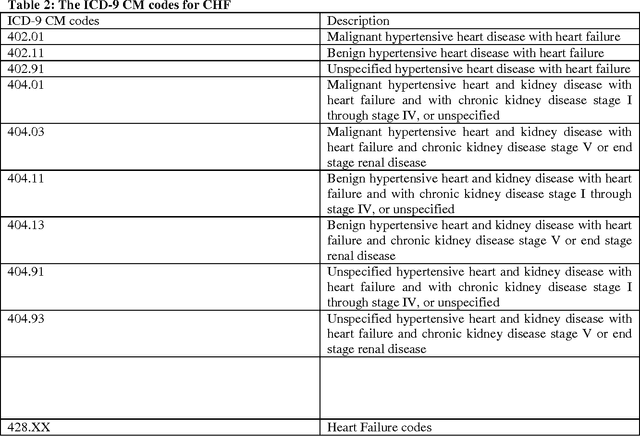
Mitigating risk-of-readmission of Congestive Heart Failure (CHF) patients within 30 days of discharge is important because such readmissions are not only expensive but also critical indicator of provider care and quality of treatment. Accurately predicting the risk-of-readmission may allow hospitals to identify high-risk patients and eventually improve quality of care by identifying factors that contribute to such readmissions in many scenarios. In this paper, we investigate the problem of predicting risk-of-readmission as a supervised learning problem, using a multi-layer classification approach. Earlier contributions inadequately attempted to assess a risk value for 30 day readmission by building a direct predictive model as opposed to our approach. We first split the problem into various stages, (a) at risk in general (b) risk within 60 days (c) risk within 30 days, and then build suitable classifiers for each stage, thereby increasing the ability to accurately predict the risk using multiple layers of decision. The advantage of our approach is that we can use different classification models for the subtasks that are more suited for the respective problems. Moreover, each of the subtasks can be solved using different features and training data leading to a highly confident diagnosis or risk compared to a one-shot single layer approach. An experimental evaluation on actual hospital patient record data from Multicare Health Systems shows that our model is significantly better at predicting risk-of-readmission of CHF patients within 30 days after discharge compared to prior attempts.