 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3dSAGER: Geospatial Entity Resolution over 3D Objects (Technical Report)
Nov 09, 2025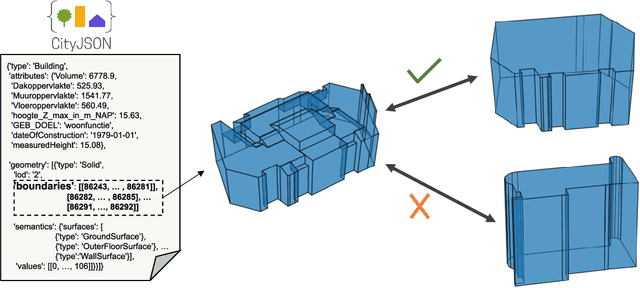
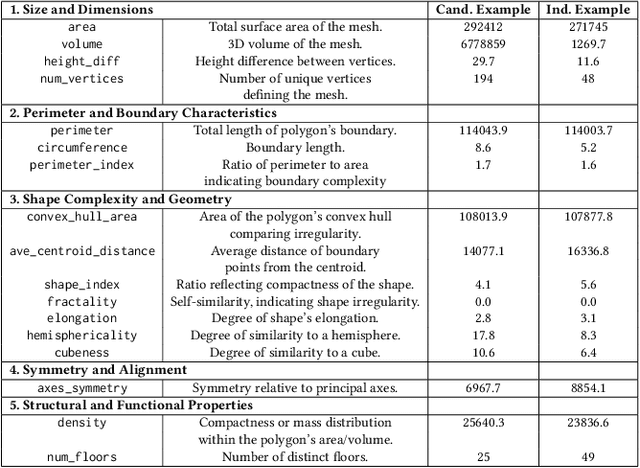
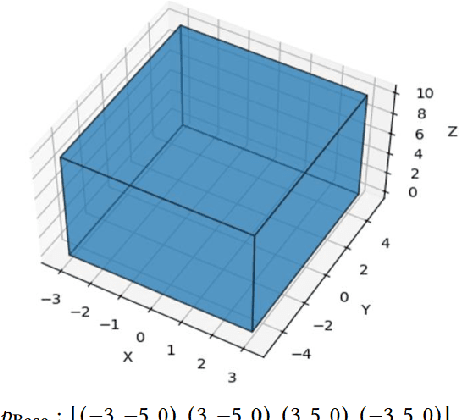
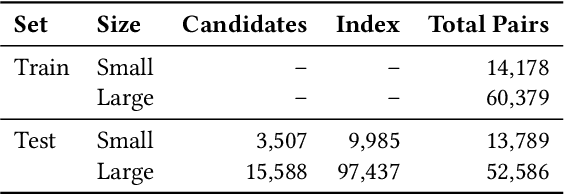
Urban environments are continuously mapped and modeled by various data collection platforms, including satellites, unmanned aerial vehicles and street cameras. The growing availability of 3D geospatial data from multiple modalities has introduced new opportunities and challenges for integrating spatial knowledge at scale, particularly in high-impact domains such as urban planning and rapid disaster management. Geospatial entity resolution is the task of identifying matching spatial objects across different datasets, often collected independently under varying conditions. Existing approaches typically rely on spatial proximity, textual metadata, or external identifiers to determine correspondence. While useful, these signals are often unavailable, unreliable, or misaligned, especially in cross-source scenarios. To address these limitations, we shift the focus to the intrinsic geometry of 3D spatial objects and present 3dSAGER (3D Spatial-Aware Geospatial Entity Resolution), an end-to-end pipeline for geospatial entity resolution over 3D objects. 3dSAGER introduces a novel, spatial-reference-independent featurization mechanism that captures intricate geometric characteristics of matching pairs, enabling robust comparison even across datasets with incompatible coordinate systems where traditional spatial methods fail. As a key component of 3dSAGER, we also propose a new lightweight and interpretable blocking method, BKAFI, that leverages a trained model to efficiently generate high-recall candidate sets. We validate 3dSAGER through extensive experiments on real-world urban datasets, demonstrating significant gains in both accuracy and efficiency over strong baselines. Our empirical study further dissects the contributions of each component, providing insights into their impact and the overall design choices.
MISFEAT: Feature Selection for Subgroups with Systematic Missing Data
Dec 09, 2024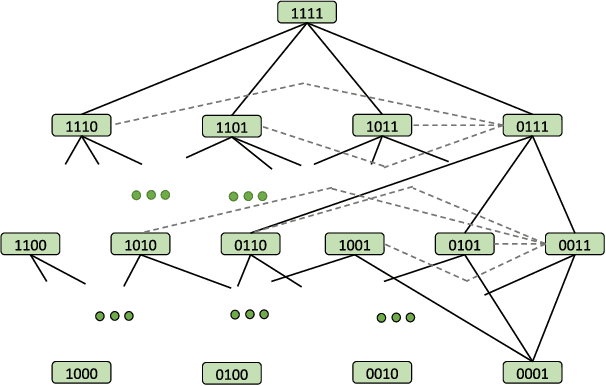
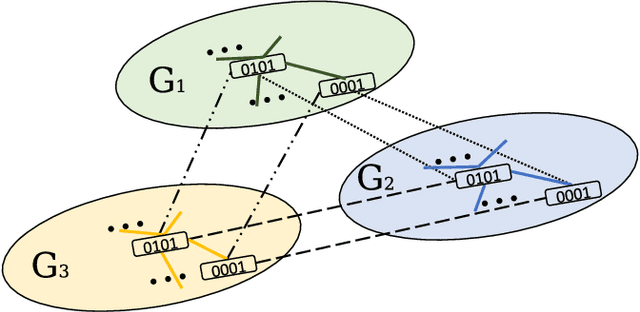
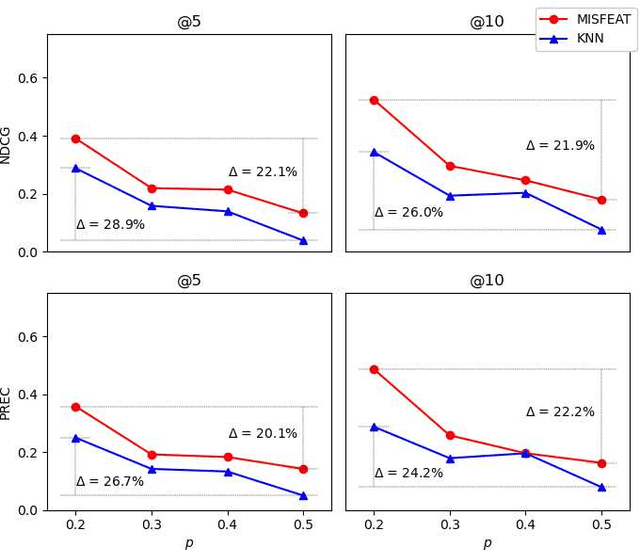
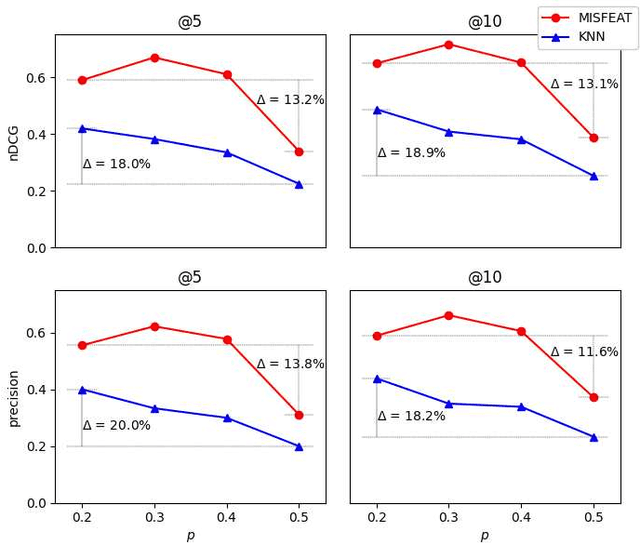
We investigate the problem of selecting features for datasets that can be naturally partitioned into subgroups (e.g., according to socio-demographic groups and age), each with its own dominant set of features. Within this subgroup-oriented framework, we address the challenge of systematic missing data, a scenario in which some feature values are missing for all tuples of a subgroup, due to flawed data integration, regulatory constraints, or privacy concerns. Feature selection is governed by finding mutual Information, a popular quantification of correlation, between features and a target variable. Our goal is to identify top-K feature subsets of some fixed size with the highest joint mutual information with a target variable. In the presence of systematic missing data, the closed form of mutual information could not simply be applied. We argue that in such a setting, leveraging relationships between available feature mutual information within a subgroup or across subgroups can assist inferring missing mutual information values. We propose a generalizable model based on heterogeneous graph neural network to identify interdependencies between feature-subgroup-target variable connections by modeling it as a multiplex graph, and employing information propagation between its nodes. We address two distinct scalability challenges related to training and propose principled solutions to tackle them. Through an extensive empirical evaluation, we demonstrate the efficacy of the proposed solutions both qualitatively and running time wise.
The Battleship Approach to the Low Resource Entity Matching Problem
Nov 27, 2023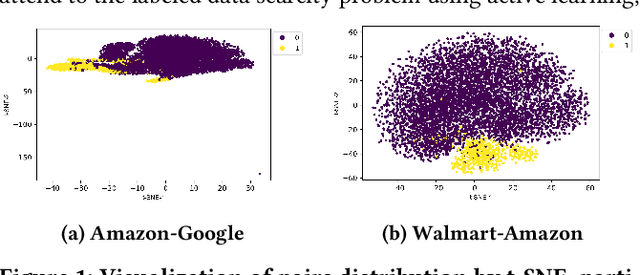


Entity matching, a core data integration problem, is the task of deciding whether two data tuples refer to the same real-world entity. Recent advances in deep learning methods, using pre-trained language models, were proposed for resolving entity matching. Although demonstrating unprecedented results, these solutions suffer from a major drawback as they require large amounts of labeled data for training, and, as such, are inadequate to be applied to low resource entity matching problems. To overcome the challenge of obtaining sufficient labeled data we offer a new active learning approach, focusing on a selection mechanism that exploits unique properties of entity matching. We argue that a distributed representation of a tuple pair indicates its informativeness when considered among other pairs. This is used consequently in our approach that iteratively utilizes space-aware considerations. Bringing it all together, we treat the low resource entity matching problem as a Battleship game, hunting indicative samples, focusing on positive ones, through awareness of the latent space along with careful planning of next sampling iterations. An extensive experimental analysis shows that the proposed algorithm outperforms state-of-the-art active learning solutions to low resource entity matching, and although using less samples, can be as successful as state-of-the-art fully trained known algorithms.