 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Pilot for Health: Personalized Algorithmic AI Nudging to Improve Health Outcomes
Jan 19, 2024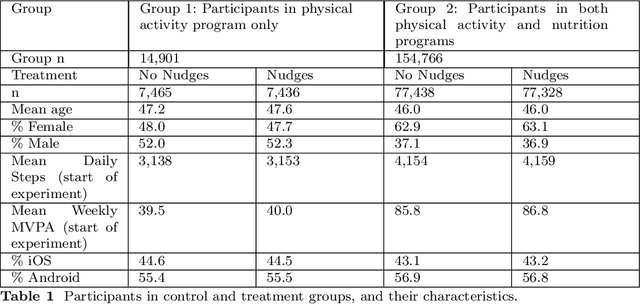
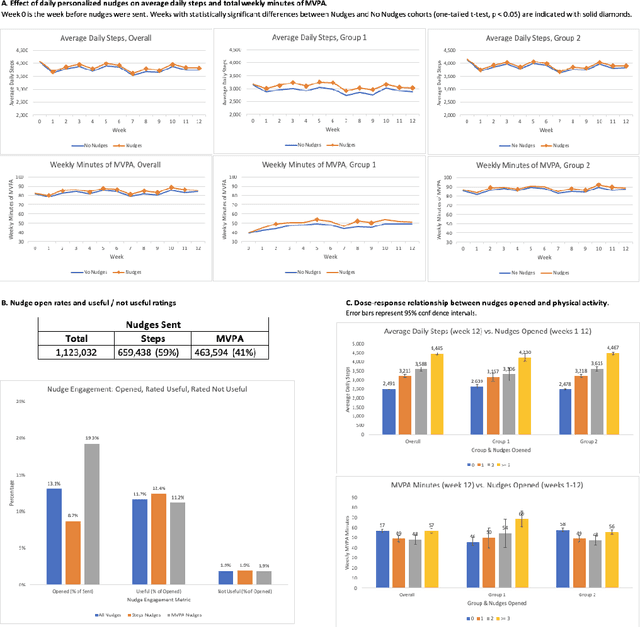
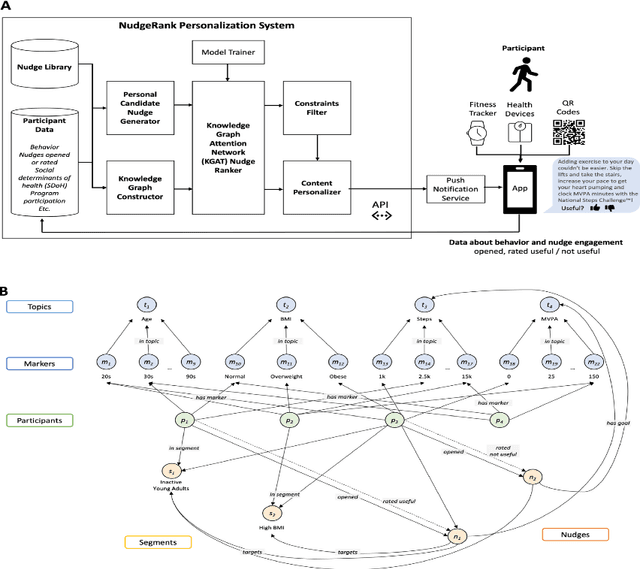

The ability to shape health behaviors of large populations automatically, across wearable types and disease conditions at scale has tremendous potential to improve global health outcomes. We designed and implemented an AI driven platform for digital algorithmic nudging, enabled by a Graph-Neural Network (GNN) based Recommendation System, and granular health behavior data from wearable fitness devices. Here we describe the efficacy results of this platform with its capabilities of personalized and contextual nudging to $n=84,764$ individuals over a 12-week period in Singapore. We statistically validated that participants in the target group who received such AI optimized daily nudges increased daily physical activity like step count by 6.17% ($p = 3.09\times10^{-4}$) and weekly minutes of Moderate to Vigorous Physical Activity (MVPA) by 7.61% ($p = 1.16\times10^{-2}$), compared to matched participants in control group who did not receive any nudges. Further, such nudges were very well received, with a 13.1% of nudges sent being opened (open rate), and 11.7% of the opened nudges rated useful compared to 1.9% rated as not useful thereby demonstrating significant improvement in population level engagement metrics.
NPRL: Nightly Profile Representation Learning for Early Sepsis Onset Prediction in ICU Trauma Patients
Apr 25, 2023Sepsis is a syndrome that develops in response to the presence of infection. It is characterized by severe organ dysfunction and is one of the leading causes of mortality in Intensive Care Units (ICUs) worldwide. These complications can be reduced through early application of antibiotics, hence the ability to anticipate the onset of sepsis early is crucial to the survival and well-being of patients. Current machine learning algorithms deployed inside medical infrastructures have demonstrated poor performance and are insufficient for anticipating sepsis onset early. In recent years, deep learning methodologies have been proposed to predict sepsis, but some fail to capture the time of onset (e.g., classifying patients' entire visits as developing sepsis or not) and others are unrealistic to be deployed into medical facilities (e.g., creating training instances using a fixed time to onset where the time of onset needs to be known apriori). Therefore, in this paper, we first propose a novel but realistic prediction framework that predicts each morning whether sepsis onset will occur within the next 24 hours using data collected at night, when patient-provider ratios are higher due to cross-coverage resulting in limited observation to each patient. However, as we increase the prediction rate into daily, the number of negative instances will increase while that of positive ones remain the same. Thereafter, we have a severe class imbalance problem, making a machine learning model hard to capture rare sepsis cases. To address this problem, we propose to do nightly profile representation learning (NPRL) for each patient. We prove that NPRL can theoretically alleviate the rare event problem. Our empirical study using data from a level-1 trauma center further demonstrates the effectiveness of our proposal.
Multi-Subset Approach to Early Sepsis Prediction
Apr 13, 2023Sepsis is a life-threatening organ malfunction caused by the host's inability to fight infection, which can lead to death without proper and immediate treatment. Therefore, early diagnosis and medical treatment of sepsis in critically ill populations at high risk for sepsis and sepsis-associated mortality are vital to providing the patient with rapid therapy. Studies show that advancing sepsis detection by 6 hours leads to earlier administration of antibiotics, which is associated with improved mortality. However, clinical scores like Sequential Organ Failure Assessment (SOFA) are not applicable for early prediction, while machine learning algorithms can help capture the progressing pattern for early prediction. Therefore, we aim to develop a machine learning algorithm that predicts sepsis onset 6 hours before it is suspected clinically. Although some machine learning algorithms have been applied to sepsis prediction, many of them did not consider the fact that six hours is not a small gap. To overcome this big gap challenge, we explore a multi-subset approach in which the likelihood of sepsis occurring earlier than 6 hours is output from a previous subset and feed to the target subset as additional features. Moreover, we use the hourly sampled data like vital signs in an observation window to derive a temporal change trend to further assist, which however is often ignored by previous studies. Our empirical study shows that both the multi-subset approach to alleviating the 6-hour gap and the added temporal trend features can help improve the performance of sepsis-related early prediction.
Machine Learning Approaches for Type 2 Diabetes Prediction and Care Management
Apr 29, 2021



Prediction of diabetes and its various complications has been studied in a number of settings, but a comprehensive overview of problem setting for diabetes prediction and care management has not been addressed in the literature. In this document we seek to remedy this omission in literature with an encompassing overview of diabetes complication prediction as well as situating this problem in the context of real world healthcare management. We illustrate various problems encountered in real world clinical scenarios via our own experience with building and deploying such models. In this manuscript we illustrate a Machine Learning (ML) framework for addressing the problem of predicting Type 2 Diabetes Mellitus (T2DM) together with a solution for risk stratification, intervention and management. These ML models align with how physicians think about disease management and mitigation, which comprises these four steps: Identify, Stratify, Engage, Measure.
Assessing Fairness in Classification Parity of Machine Learning Models in Healthcare
Feb 07, 2021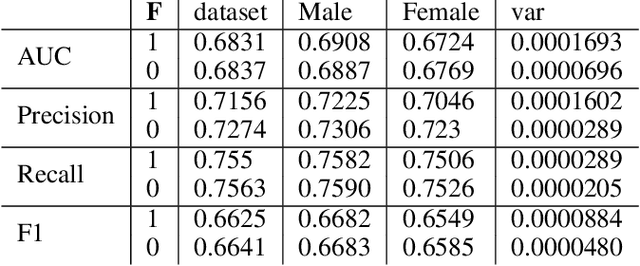
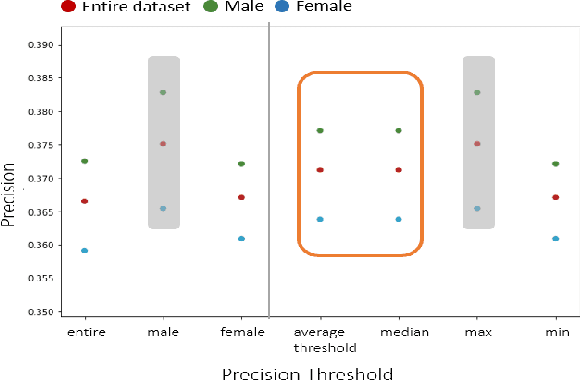
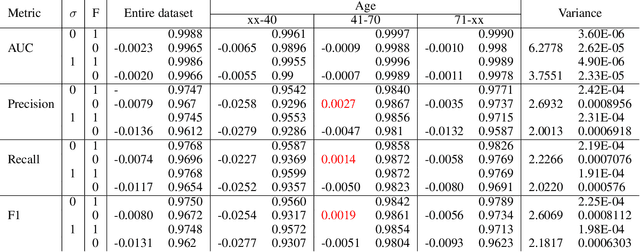
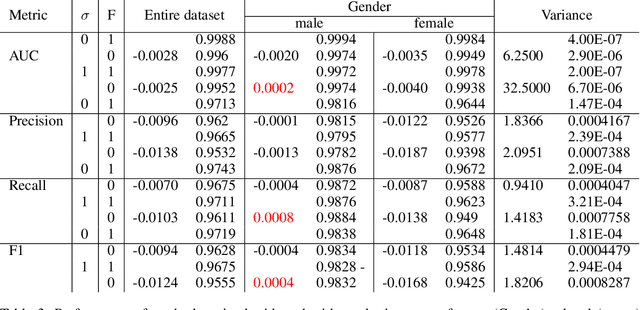
Fairness in AI and machine learning systems has become a fundamental problem in the accountability of AI systems. While the need for accountability of AI models is near ubiquitous, healthcare in particular is a challenging field where accountability of such systems takes upon additional importance, as decisions in healthcare can have life altering consequences. In this paper we present preliminary results on fairness in the context of classification parity in healthcare. We also present some exploratory methods to improve fairness and choosing appropriate classification algorithms in the context of healthcare.
Emergency Department Optimization and Load Prediction in Hospitals
Feb 06, 2021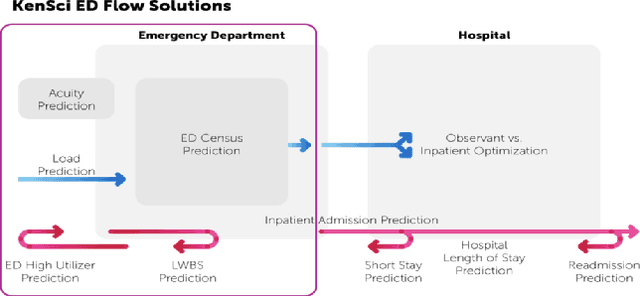

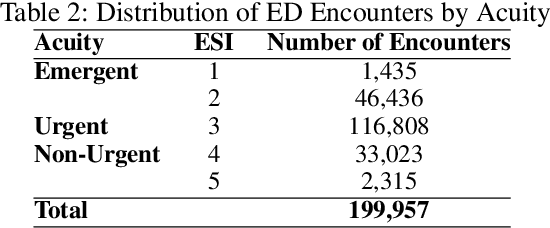
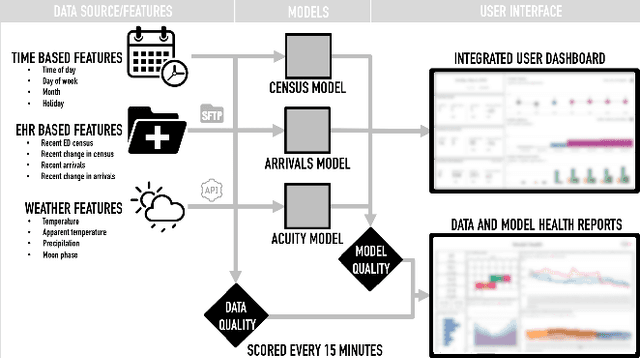
Over the past several years, across the globe, there has been an increase in people seeking care in emergency departments (EDs). ED resources, including nurse staffing, are strained by such increases in patient volume. Accurate forecasting of incoming patient volume in emergency departments (ED) is crucial for efficient utilization and allocation of ED resources. Working with a suburban ED in the Pacific Northwest, we developed a tool powered by machine learning models, to forecast ED arrivals and ED patient volume to assist end-users, such as ED nurses, in resource allocation. In this paper, we discuss the results from our predictive models, the challenges, and the learnings from users' experiences with the tool in active clinical deployment in a real world setting.
Survey of explainable machine learning with visual and granular methods beyond quasi-explanations
Sep 21, 2020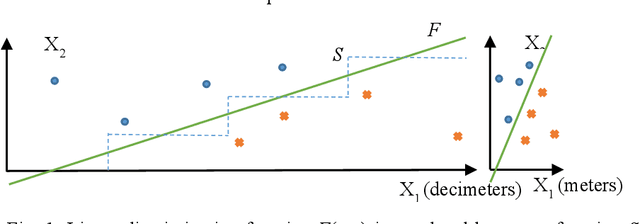
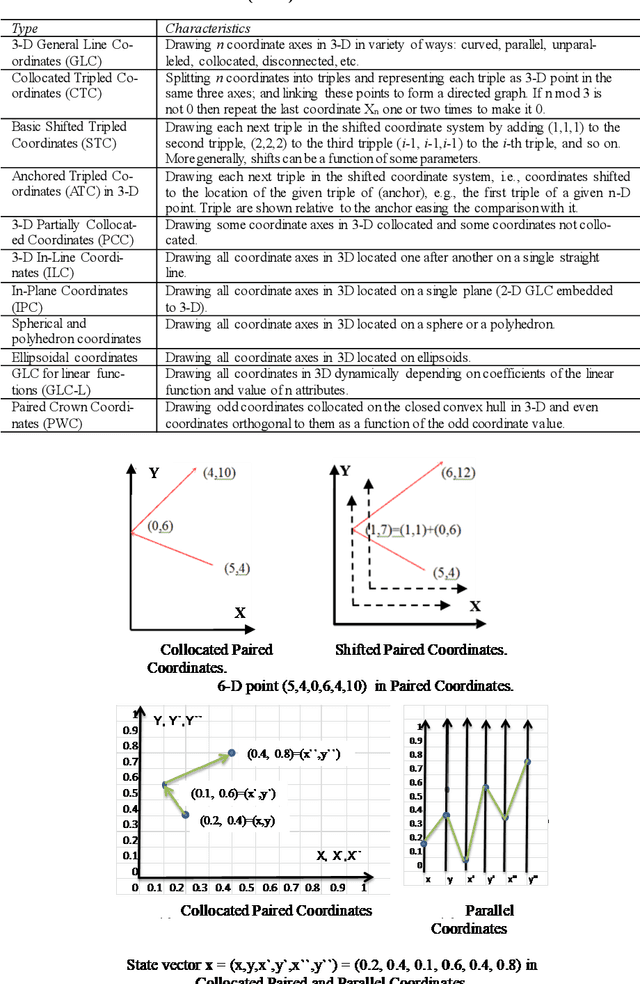
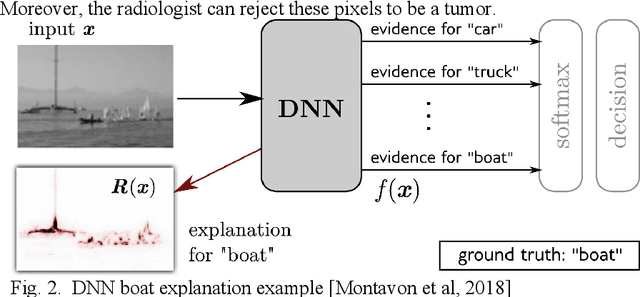
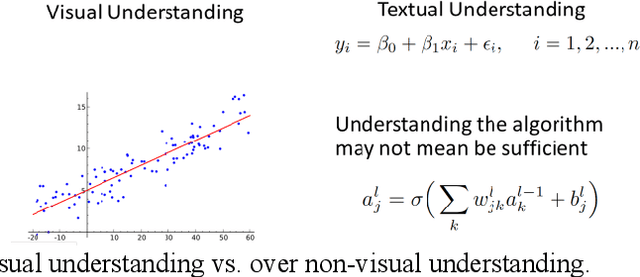
This paper surveys visual methods of explainability of Machine Learning (ML) with focus on moving from quasi-explanations that dominate in ML to domain-specific explanation supported by granular visuals. ML interpretation is fundamentally a human activity and visual methods are more readily interpretable. While efficient visual representations of high-dimensional data exist, the loss of interpretable information, occlusion, and clutter continue to be a challenge, which lead to quasi-explanations. We start with the motivation and the different definitions of explainability. The paper focuses on a clear distinction between quasi-explanations and domain specific explanations, and between explainable and an actually explained ML model that are critically important for the explainability domain. We discuss foundations of interpretability, overview visual interpretability and present several types of methods to visualize the ML models. Next, we present methods of visual discovery of ML models, with the focus on interpretable models, based on the recently introduced concept of General Line Coordinates (GLC). These methods take the critical step of creating visual explanations that are not merely quasi-explanations but are also domain specific visual explanations while these methods themselves are domain-agnostic. The paper includes results on theoretical limits to preserve n-D distances in lower dimensions, based on the Johnson-Lindenstrauss lemma, point-to-point and point-to-graph GLC approaches, and real-world case studies. The paper also covers traditional visual methods for understanding ML models, which include deep learning and time series models. We show that many of these methods are quasi-explanations and need further enhancement to become domain specific explanations. We conclude with outlining open problems and current research frontiers.
The Challenge of Imputation in Explainable Artificial Intelligence Models
Jul 29, 2019

Explainable models in Artificial Intelligence are often employed to ensure transparency and accountability of AI systems. The fidelity of the explanations are dependent upon the algorithms used as well as on the fidelity of the data. Many real world datasets have missing values that can greatly influence explanation fidelity. The standard way to deal with such scenarios is imputation. This can, however, lead to situations where the imputed values may correspond to a setting which refer to counterfactuals. Acting on explanations from AI models with imputed values may lead to unsafe outcomes. In this paper, we explore different settings where AI models with imputation can be problematic and describe ways to address such scenarios.
Predicting Risk-of-Readmission for Congestive Heart Failure Patients: A Multi-Layer Approach
Jun 10, 2013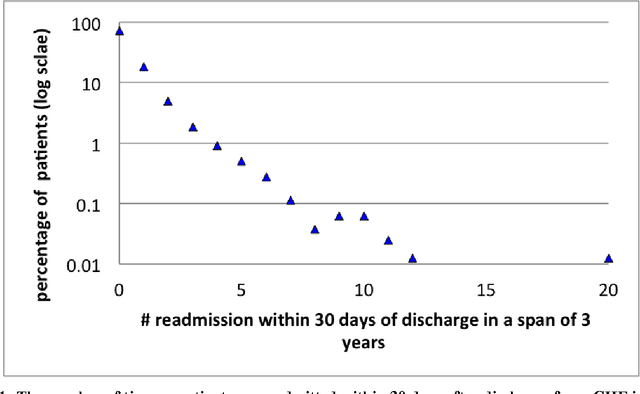

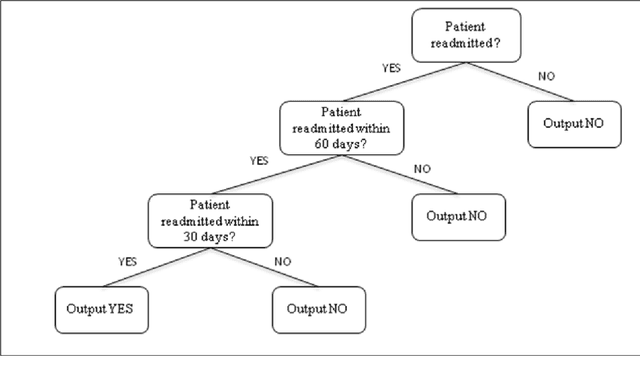
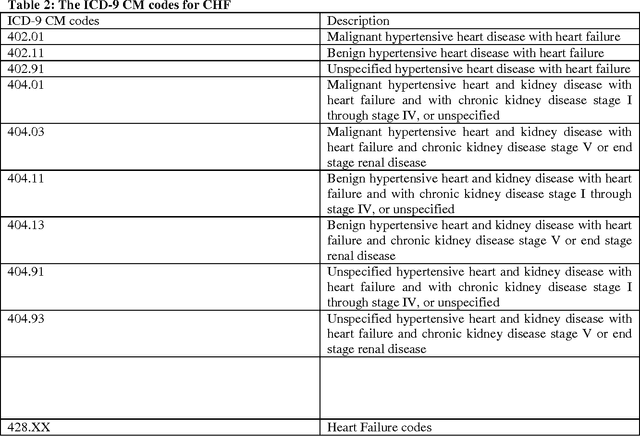
Mitigating risk-of-readmission of Congestive Heart Failure (CHF) patients within 30 days of discharge is important because such readmissions are not only expensive but also critical indicator of provider care and quality of treatment. Accurately predicting the risk-of-readmission may allow hospitals to identify high-risk patients and eventually improve quality of care by identifying factors that contribute to such readmissions in many scenarios. In this paper, we investigate the problem of predicting risk-of-readmission as a supervised learning problem, using a multi-layer classification approach. Earlier contributions inadequately attempted to assess a risk value for 30 day readmission by building a direct predictive model as opposed to our approach. We first split the problem into various stages, (a) at risk in general (b) risk within 60 days (c) risk within 30 days, and then build suitable classifiers for each stage, thereby increasing the ability to accurately predict the risk using multiple layers of decision. The advantage of our approach is that we can use different classification models for the subtasks that are more suited for the respective problems. Moreover, each of the subtasks can be solved using different features and training data leading to a highly confident diagnosis or risk compared to a one-shot single layer approach. An experimental evaluation on actual hospital patient record data from Multicare Health Systems shows that our model is significantly better at predicting risk-of-readmission of CHF patients within 30 days after discharge compared to prior attempts.