 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidation of a Hospital Digital Twin with Machine Learning
Mar 09, 2023Recently there has been a surge of interest in developing Digital Twins of process flows in healthcare to better understand bottlenecks and areas of improvement. A key challenge is in the validation process. We describe a work in progress for a digital twin using an agent based simulation model for determining bed turnaround time for patients in hospitals. We employ a strategy using machine learning for validating the model and implementing sensitivity analysis.
Machine Learning Approaches for Type 2 Diabetes Prediction and Care Management
Apr 29, 2021



Prediction of diabetes and its various complications has been studied in a number of settings, but a comprehensive overview of problem setting for diabetes prediction and care management has not been addressed in the literature. In this document we seek to remedy this omission in literature with an encompassing overview of diabetes complication prediction as well as situating this problem in the context of real world healthcare management. We illustrate various problems encountered in real world clinical scenarios via our own experience with building and deploying such models. In this manuscript we illustrate a Machine Learning (ML) framework for addressing the problem of predicting Type 2 Diabetes Mellitus (T2DM) together with a solution for risk stratification, intervention and management. These ML models align with how physicians think about disease management and mitigation, which comprises these four steps: Identify, Stratify, Engage, Measure.
Assessing Fairness in Classification Parity of Machine Learning Models in Healthcare
Feb 07, 2021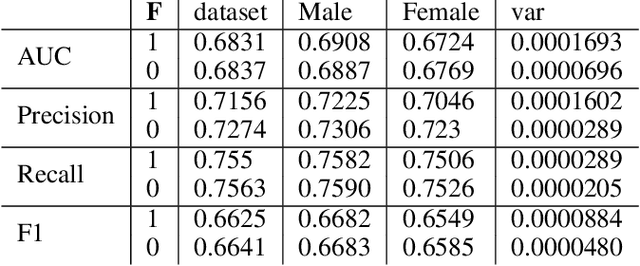
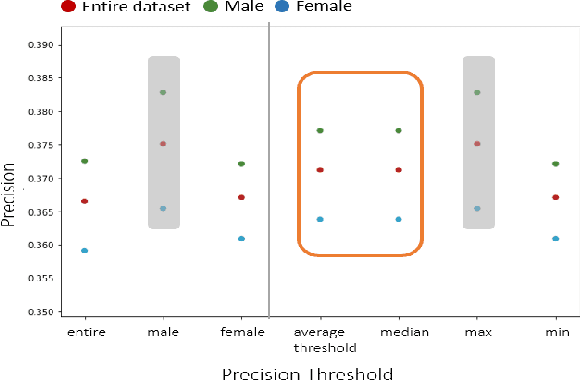
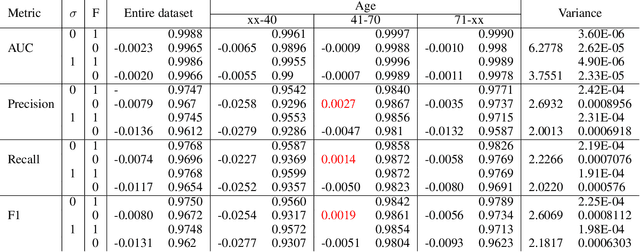
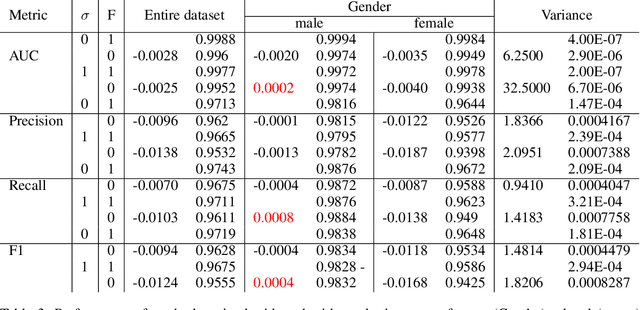
Fairness in AI and machine learning systems has become a fundamental problem in the accountability of AI systems. While the need for accountability of AI models is near ubiquitous, healthcare in particular is a challenging field where accountability of such systems takes upon additional importance, as decisions in healthcare can have life altering consequences. In this paper we present preliminary results on fairness in the context of classification parity in healthcare. We also present some exploratory methods to improve fairness and choosing appropriate classification algorithms in the context of healthcare.
Emergency Department Optimization and Load Prediction in Hospitals
Feb 06, 2021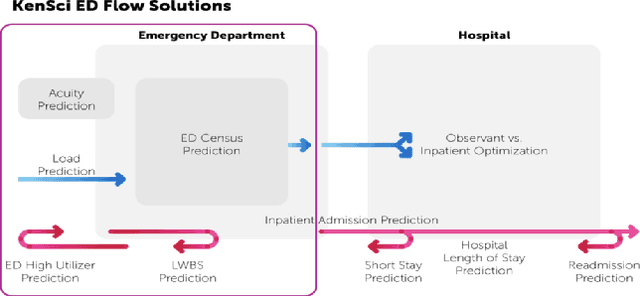

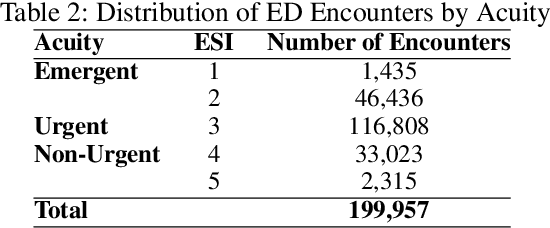
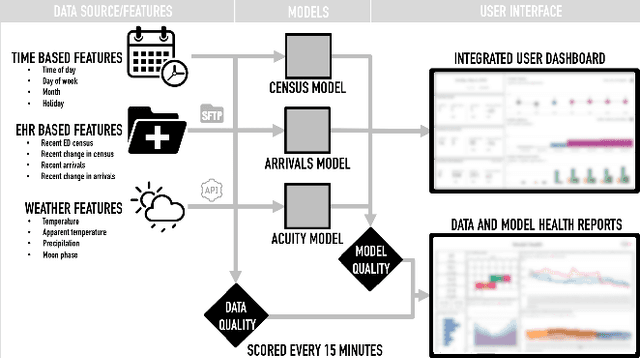
Over the past several years, across the globe, there has been an increase in people seeking care in emergency departments (EDs). ED resources, including nurse staffing, are strained by such increases in patient volume. Accurate forecasting of incoming patient volume in emergency departments (ED) is crucial for efficient utilization and allocation of ED resources. Working with a suburban ED in the Pacific Northwest, we developed a tool powered by machine learning models, to forecast ED arrivals and ED patient volume to assist end-users, such as ED nurses, in resource allocation. In this paper, we discuss the results from our predictive models, the challenges, and the learnings from users' experiences with the tool in active clinical deployment in a real world setting.
Survey of explainable machine learning with visual and granular methods beyond quasi-explanations
Sep 21, 2020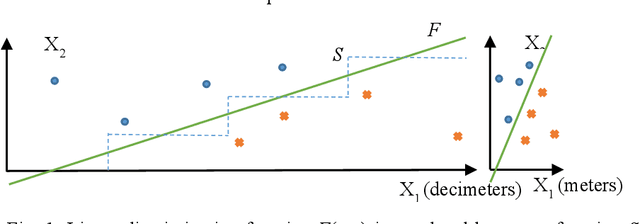
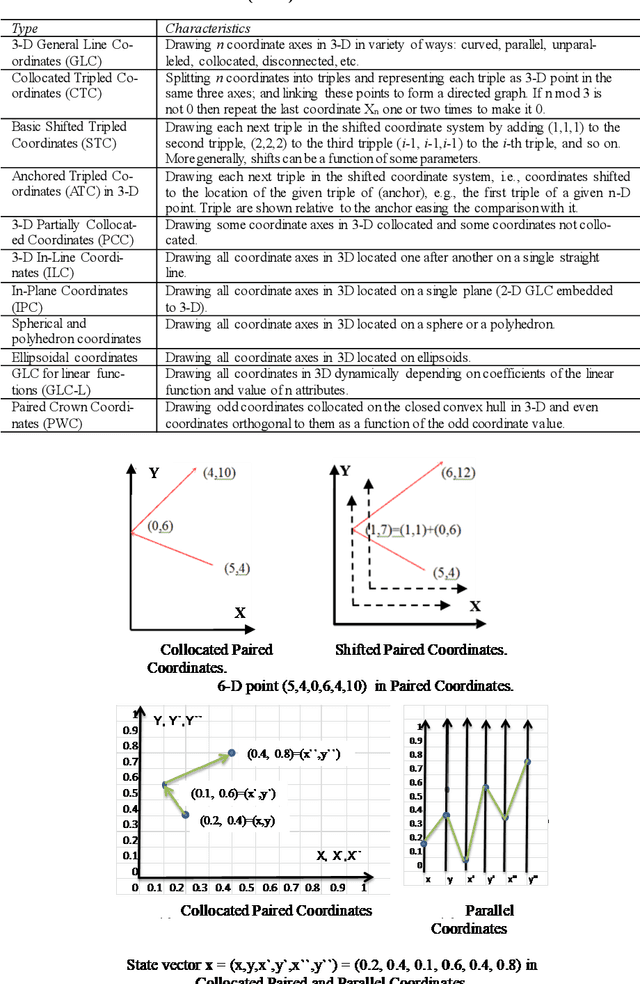
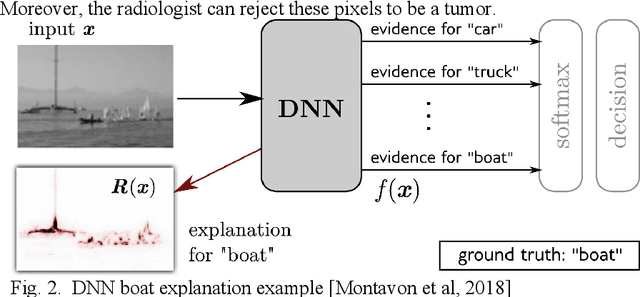
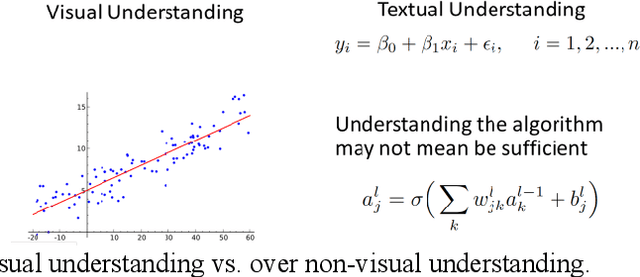
This paper surveys visual methods of explainability of Machine Learning (ML) with focus on moving from quasi-explanations that dominate in ML to domain-specific explanation supported by granular visuals. ML interpretation is fundamentally a human activity and visual methods are more readily interpretable. While efficient visual representations of high-dimensional data exist, the loss of interpretable information, occlusion, and clutter continue to be a challenge, which lead to quasi-explanations. We start with the motivation and the different definitions of explainability. The paper focuses on a clear distinction between quasi-explanations and domain specific explanations, and between explainable and an actually explained ML model that are critically important for the explainability domain. We discuss foundations of interpretability, overview visual interpretability and present several types of methods to visualize the ML models. Next, we present methods of visual discovery of ML models, with the focus on interpretable models, based on the recently introduced concept of General Line Coordinates (GLC). These methods take the critical step of creating visual explanations that are not merely quasi-explanations but are also domain specific visual explanations while these methods themselves are domain-agnostic. The paper includes results on theoretical limits to preserve n-D distances in lower dimensions, based on the Johnson-Lindenstrauss lemma, point-to-point and point-to-graph GLC approaches, and real-world case studies. The paper also covers traditional visual methods for understanding ML models, which include deep learning and time series models. We show that many of these methods are quasi-explanations and need further enhancement to become domain specific explanations. We conclude with outlining open problems and current research frontiers.
The Challenge of Imputation in Explainable Artificial Intelligence Models
Jul 29, 2019

Explainable models in Artificial Intelligence are often employed to ensure transparency and accountability of AI systems. The fidelity of the explanations are dependent upon the algorithms used as well as on the fidelity of the data. Many real world datasets have missing values that can greatly influence explanation fidelity. The standard way to deal with such scenarios is imputation. This can, however, lead to situations where the imputed values may correspond to a setting which refer to counterfactuals. Acting on explanations from AI models with imputed values may lead to unsafe outcomes. In this paper, we explore different settings where AI models with imputation can be problematic and describe ways to address such scenarios.