 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Aggregation Queries over Predicted Nearest Neighbors
Feb 26, 2025We introduce Aggregation Queries over Nearest Neighbors (AQNNs), a novel type of aggregation queries over the predicted neighborhood of a designated object. AQNNs are prevalent in modern applications where, for instance, a medical professional may want to compute "the average systolic blood pressure of patients whose predicted condition is similar to a given insomnia patient". Since prediction typically involves an expensive deep learning model or a human expert, we formulate query processing as the problem of returning an approximate aggregate by combining an expensive oracle and a cheaper model (e.g, a simple ML model) to compute the predictions. We design the Sampler with Precision-Recall in Target (SPRinT) framework for answering AQNNs. SPRinT consists of sampling, nearest neighbor refinement, and aggregation, and is tailored for various aggregation functions. It enjoys provable theoretical guarantees, including bounds on sample size and on error in approximate aggregates. Our extensive experiments on medical, e-commerce, and video datasets demonstrate that SPRinT consistently achieves the lowest aggregation error with minimal computation cost compared to its baselines. Scalability results show that SPRinT's execution time and aggregation error remain stable as the dataset size increases, confirming its suitability for large-scale applications.
Personalized Top-k Set Queries Over Predicted Scores
Feb 18, 2025This work studies the applicability of expensive external oracles such as large language models in answering top-k queries over predicted scores. Such scores are incurred by user-defined functions to answer personalized queries over multi-modal data. We propose a generic computational framework that handles arbitrary set-based scoring functions, as long as the functions could be decomposed into constructs, each of which sent to an oracle (in our case an LLM) to predict partial scores. At a given point in time, the framework assumes a set of responses and their partial predicted scores, and it maintains a collection of possible sets that are likely to be the true top-k. Since calling oracles is costly, our framework judiciously identifies the next construct, i.e., the next best question to ask the oracle so as to maximize the likelihood of identifying the true top-k. We present a principled probabilistic model that quantifies that likelihood. We study efficiency opportunities in designing algorithms. We run an evaluation with three large scale datasets, scoring functions, and baselines. Experiments indicate the efficacy of our framework, as it achieves an order of magnitude improvement over baselines in requiring LLM calls while ensuring result accuracy. Scalability experiments further indicate that our framework could be used in large-scale applications.
A Sampling-based Framework for Hypothesis Testing on Large Attributed Graphs
Mar 20, 2024



Hypothesis testing is a statistical method used to draw conclusions about populations from sample data, typically represented in tables. With the prevalence of graph representations in real-life applications, hypothesis testing in graphs is gaining importance. In this work, we formalize node, edge, and path hypotheses in attributed graphs. We develop a sampling-based hypothesis testing framework, which can accommodate existing hypothesis-agnostic graph sampling methods. To achieve accurate and efficient sampling, we then propose a Path-Hypothesis-Aware SamplEr, PHASE, an m- dimensional random walk that accounts for the paths specified in a hypothesis. We further optimize its time efficiency and propose PHASEopt. Experiments on real datasets demonstrate the ability of our framework to leverage common graph sampling methods for hypothesis testing, and the superiority of hypothesis-aware sampling in terms of accuracy and time efficiency.
On Efficient Approximate Queries over Machine Learning Models
Jun 06, 2022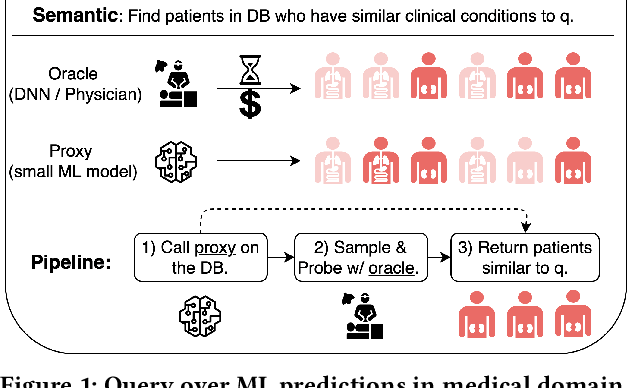

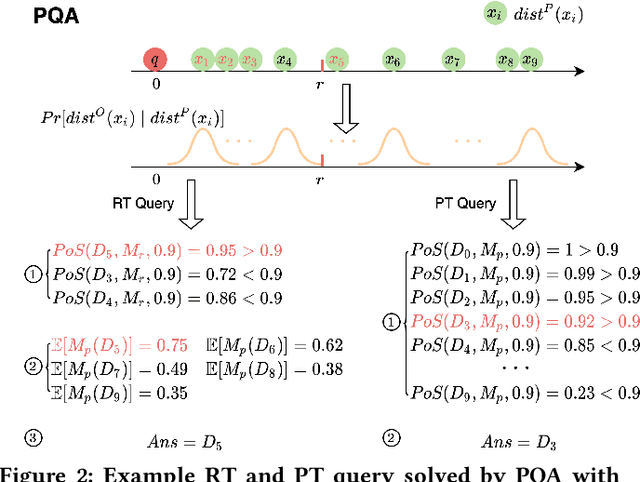

The question of answering queries over ML predictions has been gaining attention in the database community. This question is challenging because the cost of finding high quality answers corresponds to invoking an oracle such as a human expert or an expensive deep neural network model on every single item in the DB and then applying the query. We develop a novel unified framework for approximate query answering by leveraging a proxy to minimize the oracle usage of finding high quality answers for both Precision-Target (PT) and Recall-Target (RT) queries. Our framework uses a judicious combination of invoking the expensive oracle on data samples and applying the cheap proxy on the objects in the DB. It relies on two assumptions. Under the Proxy Quality assumption, proxy quality can be quantified in a probabilistic manner w.r.t. the oracle. This allows us to develop two algorithms: PQA that efficiently finds high quality answers with high probability and no oracle calls, and PQE, a heuristic extension that achieves empirically good performance with a small number of oracle calls. Alternatively, under the Core Set Closure assumption, we develop two algorithms: CSC that efficiently returns high quality answers with high probability and minimal oracle usage, and CSE, which extends it to more general settings. Our extensive experiments on five real-world datasets on both query types, PT and RT, demonstrate that our algorithms outperform the state-of-the-art and achieve high result quality with provable statistical guarantees.
Guided Exploration of Data Summaries
May 27, 2022
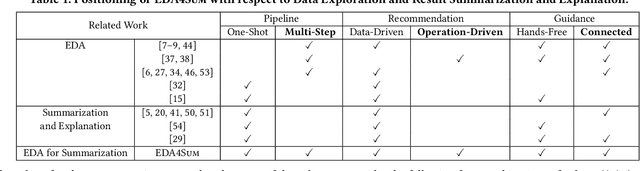
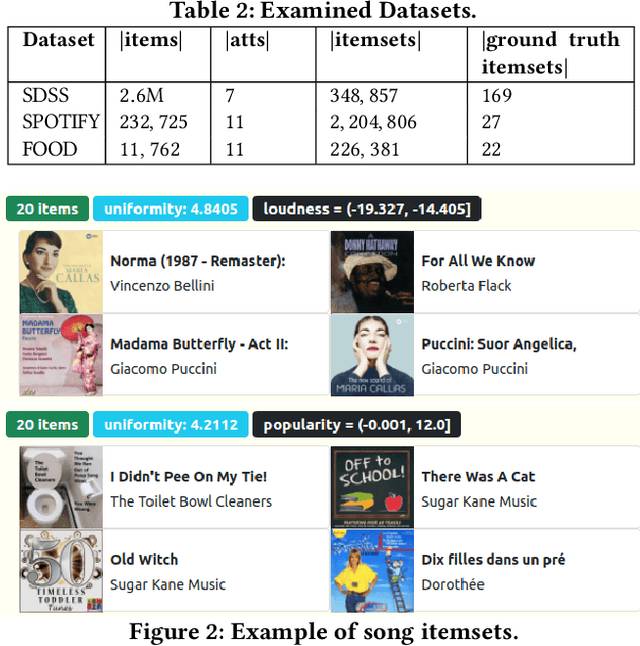
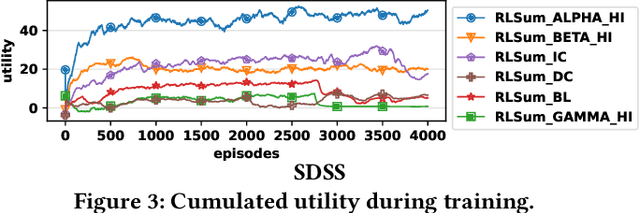
Data summarization is the process of producing interpretable and representative subsets of an input dataset. It is usually performed following a one-shot process with the purpose of finding the best summary. A useful summary contains k individually uniform sets that are collectively diverse to be representative. Uniformity addresses interpretability and diversity addresses representativity. Finding such as summary is a difficult task when data is highly diverse and large. We examine the applicability of Exploratory Data Analysis (EDA) to data summarization and formalize Eda4Sum, the problem of guided exploration of data summaries that seeks to sequentially produce connected summaries with the goal of maximizing their cumulative utility. EdA4Sum generalizes one-shot summarization. We propose to solve it with one of two approaches: (i) Top1Sum which chooses the most useful summary at each step; (ii) RLSum which trains a policy with Deep Reinforcement Learning that rewards an agent for finding a diverse and new collection of uniform sets at each step. We compare these approaches with one-shot summarization and top-performing EDA solutions. We run extensive experiments on three large datasets. Our results demonstrate the superiority of our approaches for summarizing very large data, and the need to provide guidance to domain experts.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
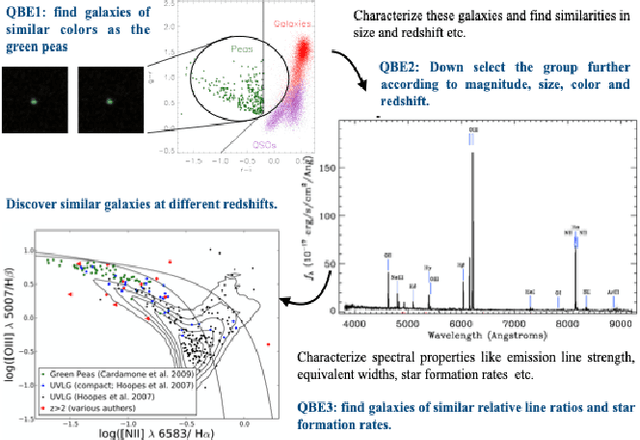
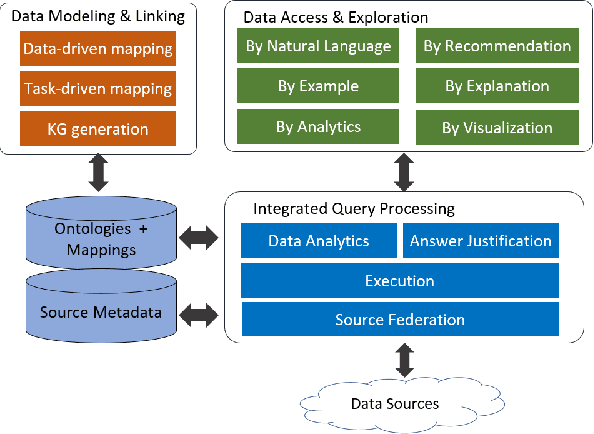

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
DropLeaf: a precision farming smartphone application for measuring pesticide spraying methods
Aug 31, 2020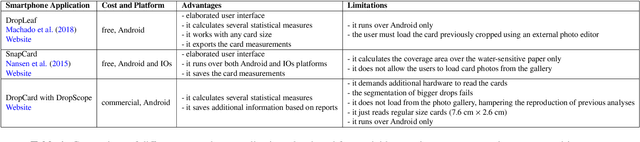

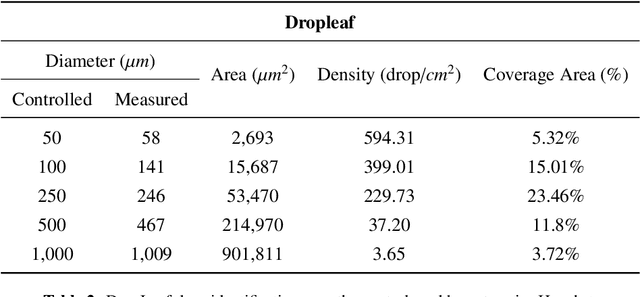

Pesticide application has been heavily used in the cultivation of major crops, contributing to the increase of crop production over the past decades. However, their appropriate use and calibration of machines rely upon evaluation methodologies that can precisely estimate how well the pesticides' spraying covered the crops. A few strategies have been proposed in former works, yet their elevated costs and low portability do not permit their wide adoption. This work introduces and experimentally assesses a novel tool that functions over a smartphone-based mobile application, named DropLeaf - Spraying Meter. Tests performed using DropLeaf demonstrated that, notwithstanding its versatility, it can estimate the pesticide spraying with high precision. Our methodology is based on image analysis, and the assessment of spraying deposition measures is performed successfully over real and synthetic water-sensitive papers. The proposed tool can be extensively used by farmers and agronomists furnished with regular smartphones, improving the utilization of pesticides with well-being, ecological, and monetary advantages. DropLeaf can be easily used for spray drift assessment of different methods, including emerging UAV (Unmanned Aerial Vehicle) sprayers.
Patient trajectory prediction in the Mimic-III dataset, challenges and pitfalls
Sep 30, 2019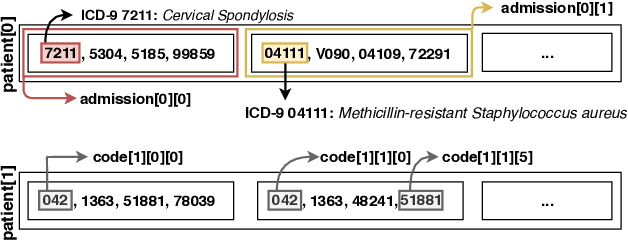

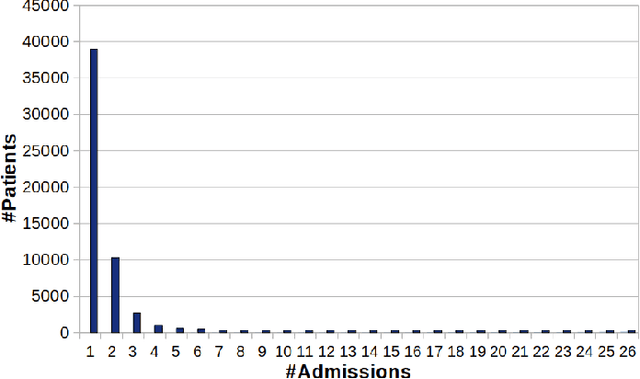
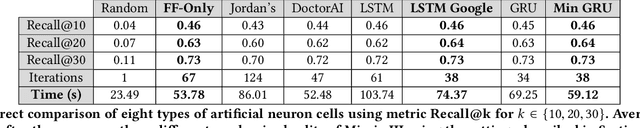
Automated medical prognosis has gained interest as artificial intelligence evolves and the potential for computer-aided medicine becomes evident. Nevertheless, it is challenging to design an effective system that, given a patient's medical history, is able to predict probable future conditions. Previous works, mostly carried out over private datasets, have tackled the problem by using artificial neural network architectures that cannot deal with low-cardinality datasets, or by means of non-generalizable inference approaches. We introduce a Deep Learning architecture whose design results from an intensive experimental process. The final architecture is based on two parallel Minimal Gated Recurrent Unit networks working in bi-directional manner, which was extensively tested with the open-access Mimic-III dataset. Our results demonstrate significant improvements in automated medical prognosis, as measured with Recall@k. We summarize our experience as a set of relevant insights for the design of Deep Learning architectures. Our work improves the performance of computer-aided medicine and can serve as a guide in designing artificial neural networks used in prediction tasks.
Eliciting Worker Preference for Task Completion
Jan 10, 2018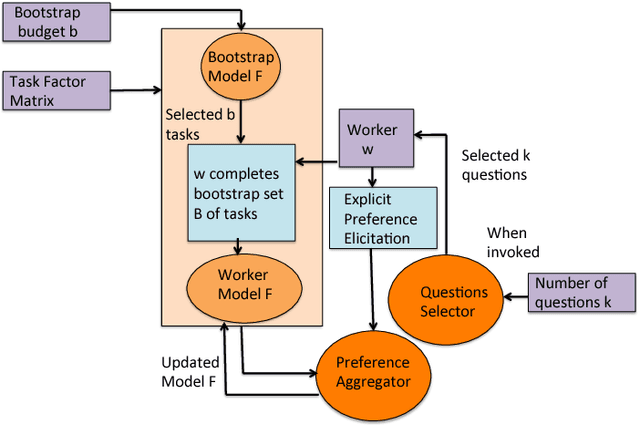
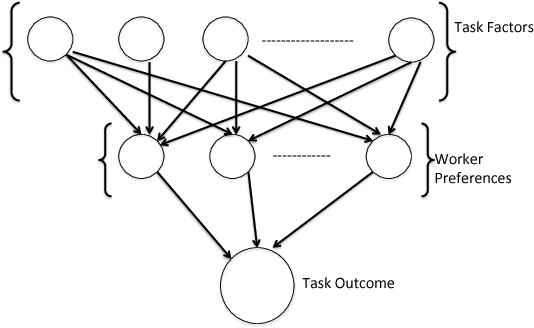
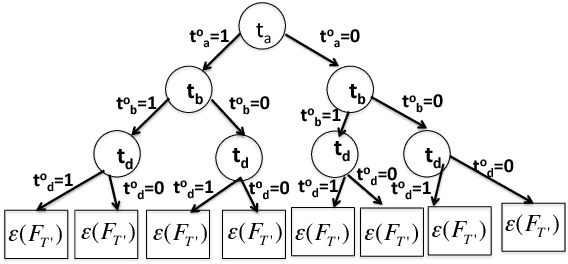
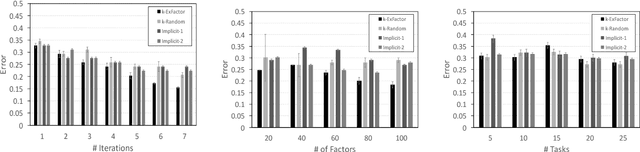
Current crowdsourcing platforms provide little support for worker feedback. Workers are sometimes invited to post free text describing their experience and preferences in completing tasks. They can also use forums such as Turker Nation1 to exchange preferences on tasks and requesters. In fact, crowdsourcing platforms rely heavily on observing workers and inferring their preferences implicitly. In this work, we believe that asking workers to indicate their preferences explicitly improve their experience in task completion and hence, the quality of their contributions. Explicit elicitation can indeed help to build more accurate worker models for task completion that captures the evolving nature of worker preferences. We design a worker model whose accuracy is improved iteratively by requesting preferences for task factors such as required skills, task payment, and task relevance. We propose a generic framework, develop efficient solutions in realistic scenarios, and run extensive experiments that show the benefit of explicit preference elicitation over implicit ones with statistical significance.