 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
BEACON: A Benchmark for Efficient and Accurate Counting of Subgraphs
Apr 15, 2025



Subgraph counting the task of determining the number of instances of a query pattern within a large graph lies at the heart of many critical applications, from analyzing financial networks and transportation systems to understanding biological interactions. Despite decades of work yielding efficient algorithmic (AL) solutions and, more recently, machine learning (ML) approaches, a clear comparative understanding is elusive. This gap stems from the absence of a unified evaluation framework, standardized datasets, and accessible ground truths, all of which hinder systematic analysis and fair benchmarking. To overcome these barriers, we introduce BEACON: a comprehensive benchmark designed to rigorously evaluate both AL and ML-based subgraph counting methods. BEACON provides a standardized dataset with verified ground truths, an integrated evaluation environment, and a public leaderboard, enabling reproducible and transparent comparisons across diverse approaches. Our extensive experiments reveal that while AL methods excel in efficiently counting subgraphs on very large graphs, they struggle with complex patterns (e.g., those exceeding six nodes). In contrast, ML methods are capable of handling larger patterns but demand massive graph data inputs and often yield suboptimal accuracy on small, dense graphs. These insights not only highlight the unique strengths and limitations of each approach but also pave the way for future advancements in subgraph counting techniques. Overall, BEACON represents a significant step towards unifying and accelerating research in subgraph counting, encouraging innovative solutions and fostering a deeper understanding of the trade-offs between algorithmic and machine learning paradigms.
On Aggregation Queries over Predicted Nearest Neighbors
Feb 26, 2025We introduce Aggregation Queries over Nearest Neighbors (AQNNs), a novel type of aggregation queries over the predicted neighborhood of a designated object. AQNNs are prevalent in modern applications where, for instance, a medical professional may want to compute "the average systolic blood pressure of patients whose predicted condition is similar to a given insomnia patient". Since prediction typically involves an expensive deep learning model or a human expert, we formulate query processing as the problem of returning an approximate aggregate by combining an expensive oracle and a cheaper model (e.g, a simple ML model) to compute the predictions. We design the Sampler with Precision-Recall in Target (SPRinT) framework for answering AQNNs. SPRinT consists of sampling, nearest neighbor refinement, and aggregation, and is tailored for various aggregation functions. It enjoys provable theoretical guarantees, including bounds on sample size and on error in approximate aggregates. Our extensive experiments on medical, e-commerce, and video datasets demonstrate that SPRinT consistently achieves the lowest aggregation error with minimal computation cost compared to its baselines. Scalability results show that SPRinT's execution time and aggregation error remain stable as the dataset size increases, confirming its suitability for large-scale applications.
Towards Understanding Fine-Tuning Mechanisms of LLMs via Circuit Analysis
Feb 17, 2025Fine-tuning significantly improves the performance of Large Language Models (LLMs), yet its underlying mechanisms remain poorly understood. This paper aims to provide an in-depth interpretation of the fine-tuning process through circuit analysis, a popular tool in Mechanistic Interpretability (MI). Unlike previous studies \cite{prakash2024finetuningenhancesexistingmechanisms,chhabra2024neuroplasticity} that focus on tasks where pre-trained models already perform well, we develop a set of mathematical tasks where fine-tuning yields substantial performance gains, which are closer to the practical setting. In our experiments, we identify circuits at various checkpoints during fine-tuning and examine the interplay between circuit analysis, fine-tuning methods, and task complexities. First, we find that while circuits maintain high node similarity before and after fine-tuning, their edges undergo significant changes, which is in contrast to the previous work \cite{prakash2024finetuningenhancesexistingmechanisms,chhabra2024neuroplasticity} that show circuits only add some additional components after fine-tuning. Based on these observations, we develop a circuit-aware Low-Rank Adaptation (LoRA) method, which assigns ranks to layers based on edge changes in the circuits. Experimental results demonstrate that our circuit-based LoRA algorithm achieves an average performance improvement of 2.46\% over standard LoRA with similar parameter sizes. Furthermore, we explore how combining circuits from subtasks can enhance fine-tuning in compositional tasks, providing new insights into the design of such tasks and deepening the understanding of circuit dynamics and fine-tuning mechanisms.
Unlocking Continual Learning Abilities in Language Models
Jun 25, 2024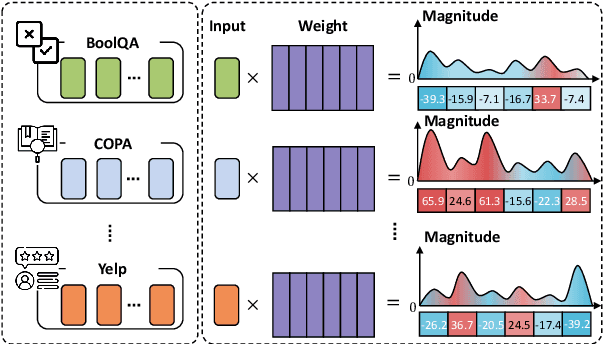
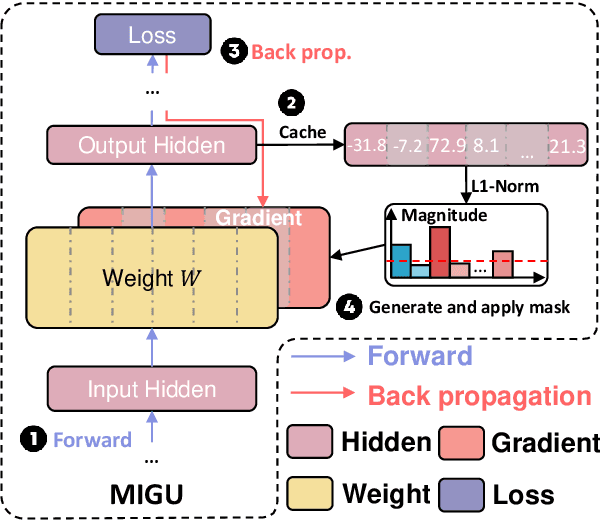
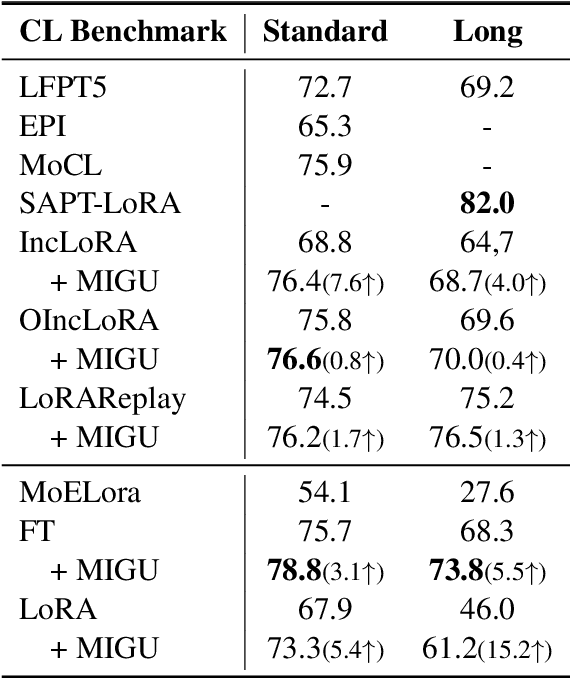
Language models (LMs) exhibit impressive performance and generalization capabilities. However, LMs struggle with the persistent challenge of catastrophic forgetting, which undermines their long-term sustainability in continual learning (CL). Existing approaches usually address the issue by incorporating old task data or task-wise inductive bias into LMs. However, old data and accurate task information are often unavailable or costly to collect, hindering the availability of current CL approaches for LMs. To address this limitation, we introduce $\textbf{MIGU}$ ($\textbf{M}$agn$\textbf{I}$tude-based $\textbf{G}$radient $\textbf{U}$pdating for continual learning), a rehearsal-free and task-label-free method that only updates the model parameters with large magnitudes of output in LMs' linear layers. MIGU is based on our observation that the L1-normalized magnitude distribution of the output in LMs' linear layers is different when the LM models deal with different task data. By imposing this simple constraint on the gradient update process, we can leverage the inherent behaviors of LMs, thereby unlocking their innate CL abilities. Our experiments demonstrate that MIGU is universally applicable to all three LM architectures (T5, RoBERTa, and Llama2), delivering state-of-the-art or on-par performance across continual finetuning and continual pre-training settings on four CL benchmarks. For example, MIGU brings a 15.2% average accuracy improvement over conventional parameter-efficient finetuning baselines in a 15-task CL benchmark. MIGU can also seamlessly integrate with all three existing CL types to further enhance performance. Code is available at \href{https://github.com/wenyudu/MIGU}{this https URL}.
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
May 24, 2024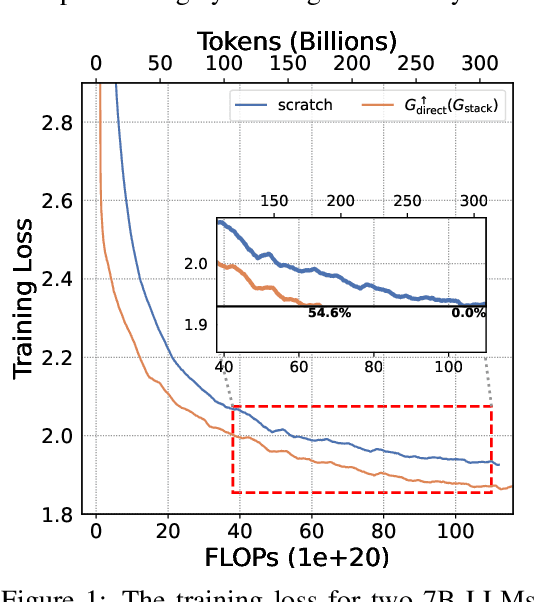

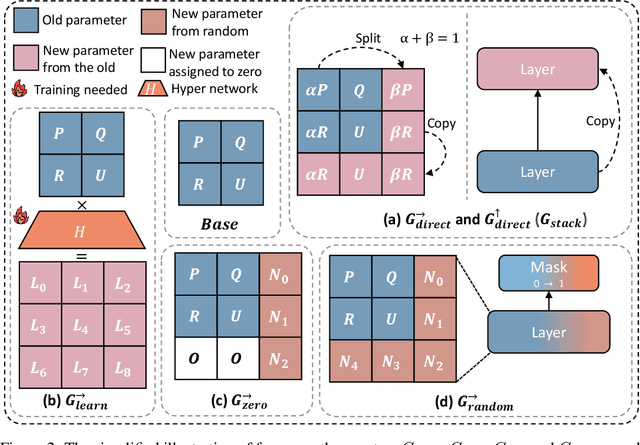

LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored. This work identifies three critical $\underline{\textit{O}}$bstacles: ($\textit{O}$1) lack of comprehensive evaluation, ($\textit{O}$2) untested viability for scaling, and ($\textit{O}$3) lack of empirical guidelines. To tackle $\textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting. Our findings reveal that a depthwise stacking operator, called $G_{\text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{\text{stack}}$ to address $\textit{O}$2 and $\textit{O}$3. For $\textit{O}$2 (untested scalability), our study shows that $G_{\text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens. For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{\text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup. We further address $\textit{O}$3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for $G_{\text{stack}}$, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of $G_{\text{stack}}$. Our code and pre-trained model are available at $\href{https://llm-stacking.github.io/}{https://llm-stacking.github.io/}$.
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation
May 24, 2024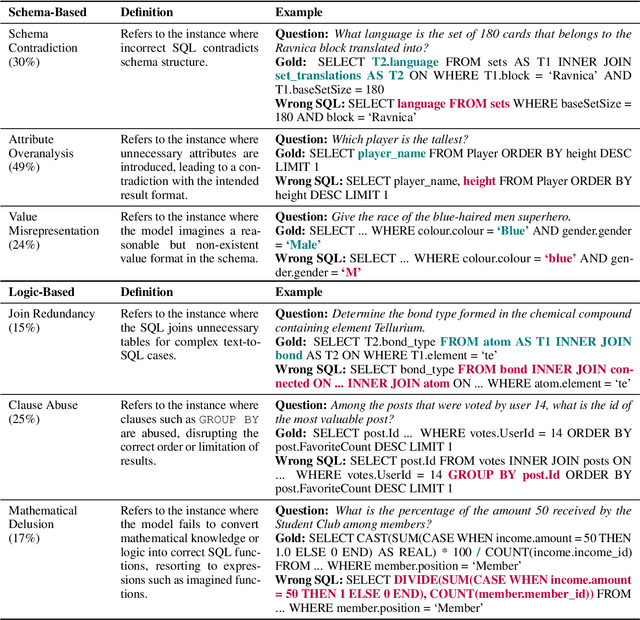
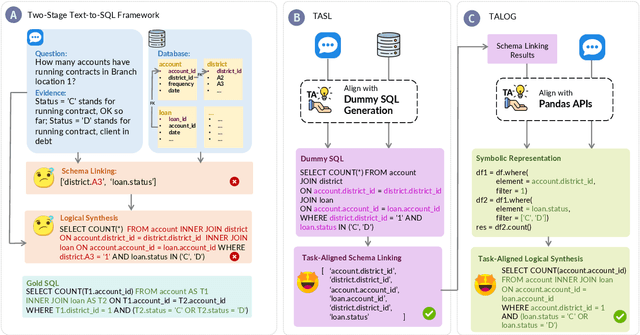
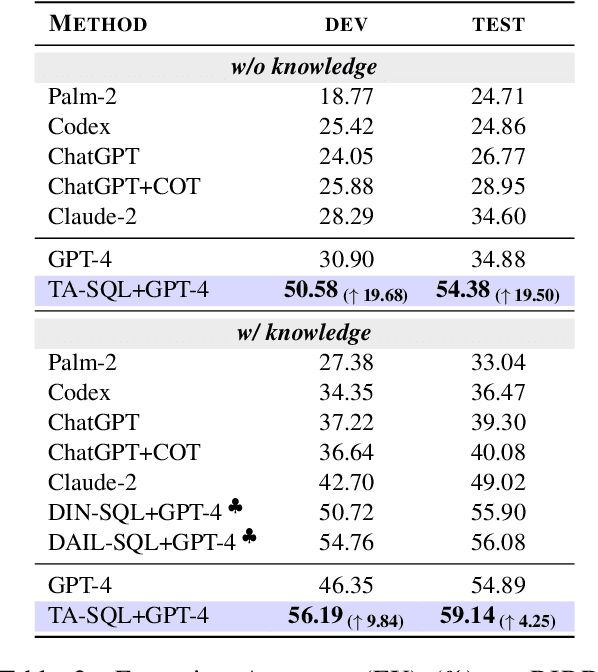
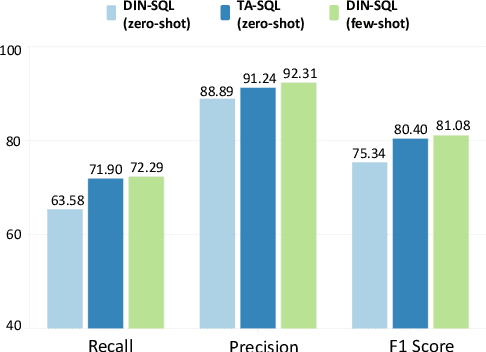
Large Language Models (LLMs) driven by In-Context Learning (ICL) have significantly improved the performance of text-to-SQL. Previous methods generally employ a two-stage reasoning framework, namely 1) schema linking and 2) logical synthesis, making the framework not only effective but also interpretable. Despite these advancements, the inherent bad nature of the generalization of LLMs often results in hallucinations, which limits the full potential of LLMs. In this work, we first identify and categorize the common types of hallucinations at each stage in text-to-SQL. We then introduce a novel strategy, Task Alignment (TA), designed to mitigate hallucinations at each stage. TA encourages LLMs to take advantage of experiences from similar tasks rather than starting the tasks from scratch. This can help LLMs reduce the burden of generalization, thereby mitigating hallucinations effectively. We further propose TA-SQL, a text-to-SQL framework based on this strategy. The experimental results and comprehensive analysis demonstrate the effectiveness and robustness of our framework. Specifically, it enhances the performance of the GPT-4 baseline by 21.23% relatively on BIRD dev and it yields significant improvements across six models and four mainstream, complex text-to-SQL benchmarks.
Multi-order Graph Clustering with Adaptive Node-level Weight Learning
May 20, 2024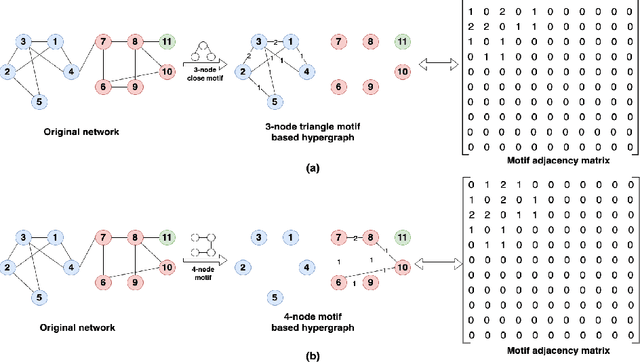

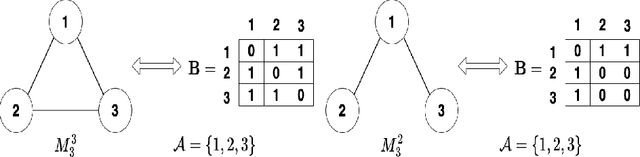
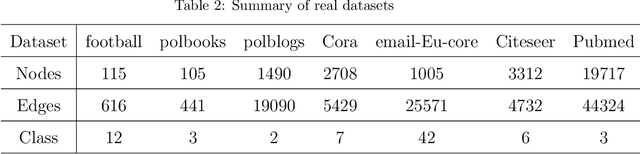
Current graph clustering methods emphasize individual node and edge con nections, while ignoring higher-order organization at the level of motif. Re cently, higher-order graph clustering approaches have been designed by motif based hypergraphs. However, these approaches often suffer from hypergraph fragmentation issue seriously, which degrades the clustering performance greatly. Moreover, real-world graphs usually contain diverse motifs, with nodes participating in multiple motifs. A key challenge is how to achieve precise clustering results by integrating information from multiple motifs at the node level. In this paper, we propose a multi-order graph clustering model (MOGC) to integrate multiple higher-order structures and edge connections at node level. MOGC employs an adaptive weight learning mechanism to au tomatically adjust the contributions of different motifs for each node. This not only tackles hypergraph fragmentation issue but enhances clustering accuracy. MOGC is efficiently solved by an alternating minimization algo rithm. Experiments on seven real-world datasets illustrate the effectiveness of MOGC.
A Sampling-based Framework for Hypothesis Testing on Large Attributed Graphs
Mar 20, 2024



Hypothesis testing is a statistical method used to draw conclusions about populations from sample data, typically represented in tables. With the prevalence of graph representations in real-life applications, hypothesis testing in graphs is gaining importance. In this work, we formalize node, edge, and path hypotheses in attributed graphs. We develop a sampling-based hypothesis testing framework, which can accommodate existing hypothesis-agnostic graph sampling methods. To achieve accurate and efficient sampling, we then propose a Path-Hypothesis-Aware SamplEr, PHASE, an m- dimensional random walk that accounts for the paths specified in a hypothesis. We further optimize its time efficiency and propose PHASEopt. Experiments on real datasets demonstrate the ability of our framework to leverage common graph sampling methods for hypothesis testing, and the superiority of hypothesis-aware sampling in terms of accuracy and time efficiency.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024



Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.