 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Recommendation with Personal Popularity
Feb 21, 2024



Global popularity (GP) bias is the phenomenon that popular items are recommended much more frequently than they should be, which goes against the goal of providing personalized recommendations and harms user experience and recommendation accuracy. Many methods have been proposed to reduce GP bias but they fail to notice the fundamental problem of GP, i.e., it considers popularity from a \textit{global} perspective of \textit{all users} and uses a single set of popular items, and thus cannot capture the interests of individual users. As such, we propose a user-aware version of item popularity named \textit{personal popularity} (PP), which identifies different popular items for each user by considering the users that share similar interests. As PP models the preferences of individual users, it naturally helps to produce personalized recommendations and mitigate GP bias. To integrate PP into recommendation, we design a general \textit{personal popularity aware counterfactual} (PPAC) framework, which adapts easily to existing recommendation models. In particular, PPAC recognizes that PP and GP have both direct and indirect effects on recommendations and controls direct effects with counterfactual inference techniques for unbiased recommendations. All codes and datasets are available at \url{https://github.com/Stevenn9981/PPAC}.
Multi-domain Recommendation with Embedding Disentangling and Domain Alignment
Aug 14, 2023Multi-domain recommendation (MDR) aims to provide recommendations for different domains (e.g., types of products) with overlapping users/items and is common for platforms such as Amazon, Facebook, and LinkedIn that host multiple services. Existing MDR models face two challenges: First, it is difficult to disentangle knowledge that generalizes across domains (e.g., a user likes cheap items) and knowledge specific to a single domain (e.g., a user likes blue clothing but not blue cars). Second, they have limited ability to transfer knowledge across domains with small overlaps. We propose a new MDR method named EDDA with two key components, i.e., embedding disentangling recommender and domain alignment, to tackle the two challenges respectively. In particular, the embedding disentangling recommender separates both the model and embedding for the inter-domain part and the intra-domain part, while most existing MDR methods only focus on model-level disentangling. The domain alignment leverages random walks from graph processing to identify similar user/item pairs from different domains and encourages similar user/item pairs to have similar embeddings, enhancing knowledge transfer. We compare EDDA with 12 state-of-the-art baselines on 3 real datasets. The results show that EDDA consistently outperforms the baselines on all datasets and domains. All datasets and codes are available at https://github.com/Stevenn9981/EDDA.
Reinforced Meta-path Selection for Recommendation on Heterogeneous Information Networks
Dec 28, 2021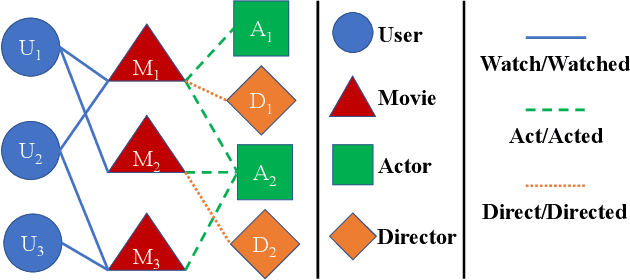
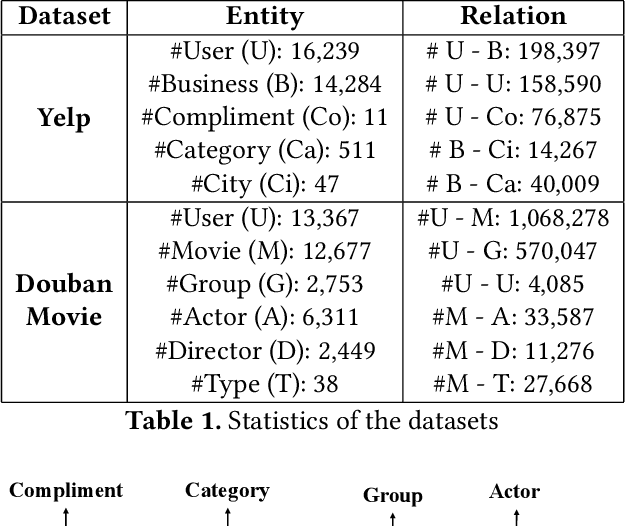
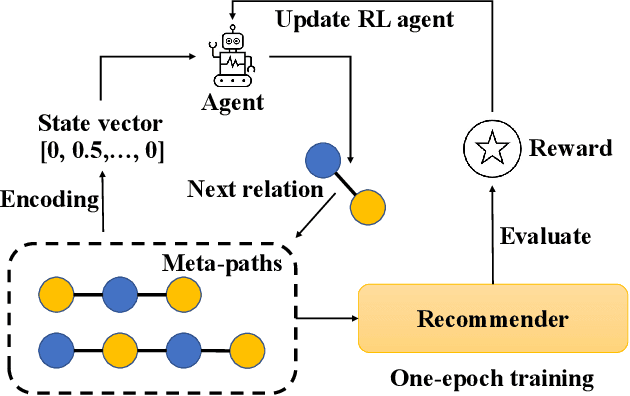
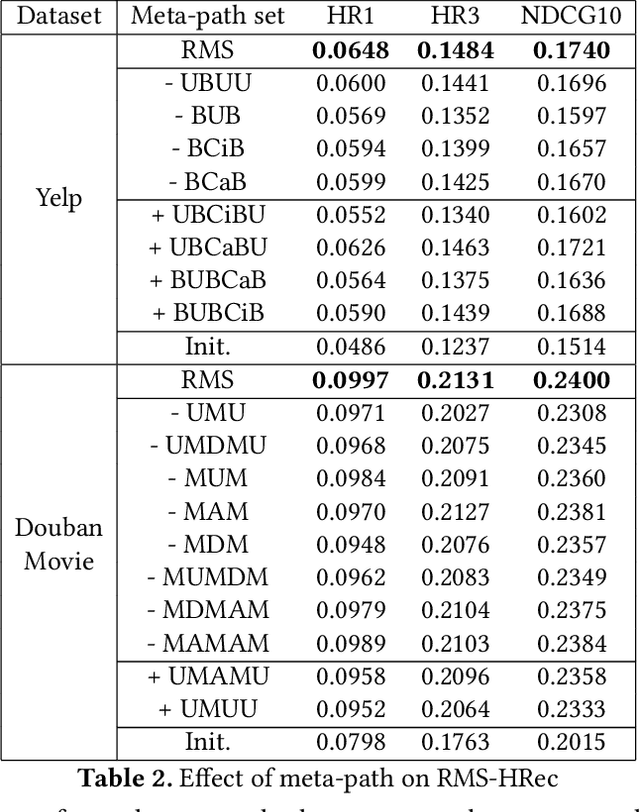
Heterogeneous Information Networks (HINs) capture complex relations among entities of various kinds and have been used extensively to improve the effectiveness of various data mining tasks, such as in recommender systems. Many existing HIN-based recommendation algorithms utilize hand-crafted meta-paths to extract semantic information from the networks. These algorithms rely on extensive domain knowledge with which the best set of meta-paths can be selected. For applications where the HINs are highly complex with numerous node and link types, the approach of hand-crafting a meta-path set is too tedious and error-prone. To tackle this problem, we propose the Reinforcement learning-based Meta-path Selection (RMS) framework to select effective meta-paths and to incorporate them into existing meta-path-based recommenders. To identify high-quality meta-paths, RMS trains a reinforcement learning (RL) based policy network(agent), which gets rewards from the performance on the downstream recommendation tasks. We design a HIN-based recommendation model, HRec, that effectively uses the meta-path information. We further integrate HRec with RMS and derive our recommendation solution, RMS-HRec, that automatically utilizes the effective meta-paths. Experiments on real datasets show that our algorithm can significantly improve the performance of recommendation models by capturing important meta-paths automatically.